|
29 |
Pongと強化学習 (3) |
DQNとCNNの構造とベルマン方程式について深堀りします。
DQN(Deep Q-Network)を使用してFPGA上でPongゲームの強化学習を実装する場合、まずは画面データ(256x256、ON/OFF)をCNNを通じて効率的に情報を圧縮し、その後の強化学習アルゴリズムで利用できるようにする必要があります。CNNを用いて画面データから特徴を抽出し、その特徴を基にDQNが行動選択を行います。
情報の圧縮
畳み込み層:画面のサイズが大きいため、最初の畳み込み層で画像サイズを大幅に削減することが効果的です。例えば、最初の畳み込み層でストライドを大きく取り(例:4または5)、カーネルサイズを(8x8)や(5x5)に設定します。これにより、画像の次元を減らしながらも、ゲーム内の主要な特徴(ボールやパドルの位置)を捉えることができます。
プーリング層:畳み込み層の後にプーリング層(例:最大プーリング)を挿入して、さらに特徴マップのサイズを減らします。これは、重要な特徴を保持しながらデータ量を減らすのに有効です。
複数の畳み込み層とプーリング層の使用:複数の畳み込み層とプーリング層を交互に配置することで、より高度な特徴を抽出しつつ、データの次元を効率的に減少させることができます。
報酬の設定
DQNでは、各行動の選択に対して報酬を与えることで学習を進めます。Pongゲームにおける報酬の設定は次のようになります:
- 加点:ボールを打ち返した時に正の報酬を与えます。これはエージェントがボールを落とさずに続ける動機付けになります。
- 減点:ボールを落とした時に負の報酬(または大きな負の報酬)を与えます。これにより、エージェントはボールを落とさないように学習します。
CNNの構造
一般的なCNNの構造は以下のようになります:
- 入力層:256x256の画像データ(ON/OFF)。
- 畳み込み層:活性化関数(ReLUなど)、カーネルサイズ(例:5x5)、ストライド(例:4)。
- プーリング層:最大プーリングを使用し、特徴マップのサイズをさらに削減。
- 全結合層:畳み込み層とプーリング層を通過した後の特徴をもとに、行動価値(Q値)を出力します。
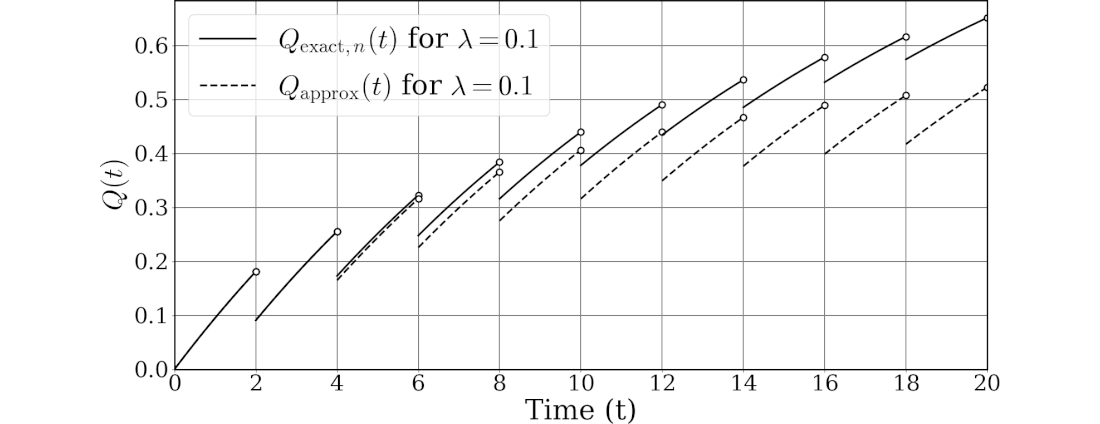
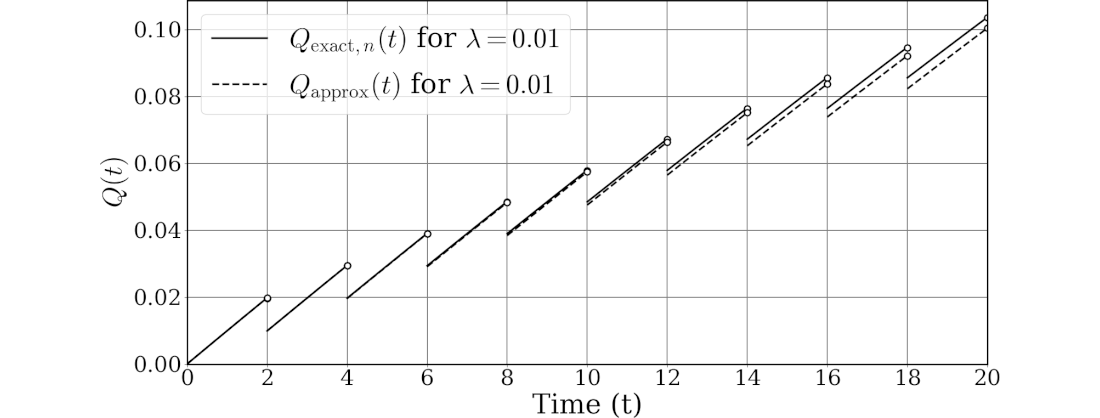
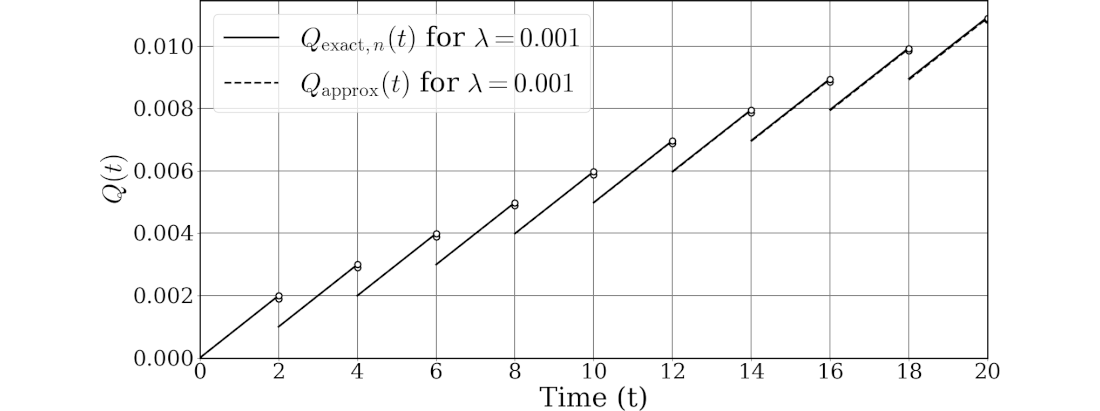
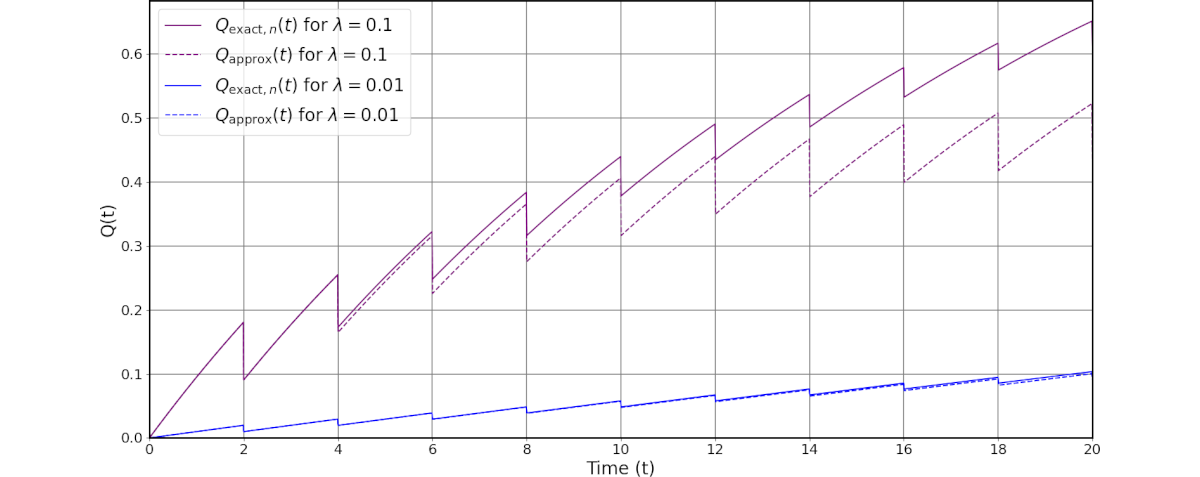
ベルマン方程式の具体化
DQNでは、ベルマン方程式を用いてQ値(行動価値関数)を更新します。具体的には、以下の式を用います:
$$Q(s,a) = R(s,a) + \gamma \max_{a'} Q(s', a')$$
ここで、$s$は現在の状態、$a$は取られた行動、$R(s,a)$はその行動による報酬、$\gamma$は割引率(将来の報酬の重要性を表す)、$s'$は次の状態、$a'$は次の行動です。この式により、最適な行動選択を学習します。
FPGA上でこれらを実装する際は、演算の効率化、メモリ使用の最適化、およびリアルタイム性の確保に特に注意が必要です。