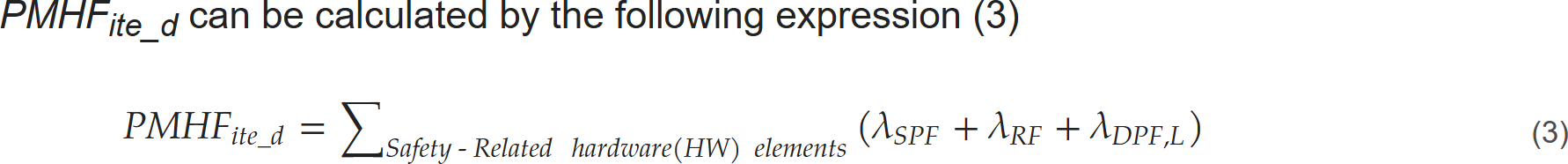|
30 |
Pongと強化学習 (104) |
コードの続きの説明です。
このコードブロックは、強化学習の訓練プロセス中に、定期的にトレーニングの進捗とパフォーマンスの指標を記録し、監視するためのものです。具体的には、損失やQ値の平均、そしてトレーニングの速度(Seconds Per Step、SPS)をログに記録し、可視化ツール(例えばTensorBoard)で確認できるようにしています。以下に、コードの各部分の詳細な解説を行います。
コードの詳細解説
1. 定期的なメトリクスの記録:
if global_step % 100 == 0:
この条件文は、100ステップごとに以下のメトリクスを記録するためのチェックポイントです。この頻度は、トレーニングプロセスを適度に監視するのに十分な間隔であり、パフォーマンスの低下を引き起こさずに進捗を追跡できるため選ばれています。
2. 損失とQ値の記録:
writer.add_scalar("losses/td_loss", loss, global_step)
writer.add_scalar("losses/q_values", old_val.mean().item(), global_step)
- 損失の記録:TD損失(Temporal Difference loss)をログに記録します。これは、エージェントの予測と実際の報酬との差の大きさを示し、学習がうまく進んでいるかを示す重要な指標です。
- Q値の記録:サンプルのアクションに対するQ値の平均を計算し、ログに記録します。これにより、Qネットワークがどの程度価値を学習しているかを監視できます。
3. トレーニングの速度(SPS)の計算と記録:
print("SPS:", int(global_step / (time.time() - start_time)))
writer.add_scalar("charts/SPS", int(global_step / (time.time() - start_time)), global_step)
- ここで、プログラムが開始してから現在までの総時間を用いて、1秒あたりの処理ステップ数(SPS)を計算しています。これは、トレーニングの効率を測る指標であり、ハードウェアのパフォーマンスや実装の効率を反映します。
- SPSの値をコンソールに出力し、同時にログファイルに記録しています。これにより、トレーニングの速度が時間とともにどのように変化するかを追跡し、必要に応じて最適化を行うことができます。
役割と重要性
これらのステップは、エージェントの学習プロセスを透明にし、問題が発生した際に迅速に対処するための洞察を提供します。定期的な監視により、アルゴリズムの微調整やパラメータの調整が必要かどうかを判断するための具体的なデータを得ることができます。また、SPSなどのパフォーマンス指標は、システムのボトルネックを特定し、トレーニングプロセスの最適化に役立ちます。このようなフィードバックは、効果的な機械学習システムを開発する上で不可欠です。