|
23 |
【速報】RAMS 2021にアブストラクトが採択 |
Posts Issued in June, 2020
|
22 |
RISC-Vの調査 (9) |
ソースの解読
ここからはソースを読んで行きます。パイプラインプロセッサは、その名のとおり各ステージがパイプラインとして動作するもので、つまりステージ毎にステージを構成するレジスタでできています。逆に、レジスタ以外は全て組み合わせ回路です。これに気づくとソースの理解が速そうです。
難しいのはパイプラインレジスタの更新ロジックで、パイプラインが動作したりストールしたりするのはこのレジスタ更新論理ですが、一方、ステージの実質のロジックは単なる組み合わせ回路です。最も分かりやすいのが演算ステージStage1で、ALU等はファンクション(組み合わせ回路)で記述されます。
それらのファンクションはパイプラインのステージからコールされ、パイプラインにはパイプライ制御のロジックしかなくなります。従って、Fluteの複雑そうな各パイプラインステージは非常に簡単な記述になっています。表280.1に各ステージのbsvで記述された行数を示します。
| ファイル名 | 行数 |
|---|---|
| CPU_StageF.bsv | 170 |
| CPU_StageD.bsv | 153 |
| CPU_Stage1.bsv | 336 |
| CPU_Stage2.bsv | 627 |
| CPU_Stage3.bsv | 245 |
|
19 |
RISC-Vの調査 (8) |
ループにおける効率調査
前稿のプログラムは命令試験プログラムだったので、キャッシュの効果が出ていませんでした。そのため、ここではループにおける効率の向上を調査します。合わせてgccの効率も調べます。
int main() {
for (int j = 0; j < 100; j++) {
for (int i = 0; i <= 9; i++) {
*UART0_ADDR = '0'+i;
}
*UART0_ADDR = '\n';
}
}
このようなループの関数を作成し、gccにより-O, -O2, -O3でコンパイルします。まず+v1で実行命令数を確認すれば、それぞれ、5617、5517、2422実行命令数となりました。
次に+v2でパイプラインの状況を確認します。
| 状態 | StageF | StageD | Stage1 | Stage2 | Stage3 |
|---|---|---|---|---|---|
| BUSY | 91 | 0 | 1,150 | 2,251 | 0 |
| EMPTY | 106 | 198 | 178 | 1,410 | 3,664 |
| PIPE処理 | 9,187 | 9,186 | 8,056 | 5,723 | 5,720 |
| 合計 | 9,384 | ||||
| 状態 | StageF | StageD | Stage1 | Stage2 | Stage3 |
|---|---|---|---|---|---|
| BUSY | 88 | 0 | 23 | 2,259 | 0 |
| EMPTY | 106 | 172 | 170 | 284 | 2,544 |
| PIPE処理 | 7,972 | 7,994 | 7,973 | 5,623 | 5,622 |
| 合計 | 8,166 | ||||
| 状態 | StageF | StageD | Stage1 | Stage2 | Stage3 |
|---|---|---|---|---|---|
| BUSY | 152 | 0 | 1,023 | 2,264 | 0 |
| EMPTY | 4 | 131 | 131 | 1,138 | 3,403 |
| PIPE処理 | 5,672 | 5,697 | 4,674 | 2,426 | 2,425 |
| 合計 | 5,828 | ||||
これらの表の合計欄がマシンサイクルを意味しています。従って、最適化度合いに対するCPIは、-O, -O2, -O3のそれぞれで1.67、1.48、2.41となりました。
表279.3の-O3においてはインナーループを展開しているため、命令キャッシュミスが若干増加しており、デコードステージ以下のパイプラインバブルが発生していますが、命令数をぐっと少なくしてマシンサイクルを縮めています。いずれも表264.1と比較すると、ループであるため命令キャッシュミスによるパイプラインストールがかなり少なくなっており、効率が向上しています。
|
18 |
RISC-Vの調査 (7) |
Bsimによるシミュレーション
$ ./exe_HW_sim +v1 +tohost
によりBsimのシミュレーションが実行されます。+v1で命令毎のトレース、+v2でパイプライン内容を含めたトレースが表示されます。さらに波形観測のためには
$ ./exe_HW_sim +v1 +tohost -V dump.vcd
のようにVCDファイルを指定します。これをGtkwaveにより開き、波形を観測してみます。\$80000000から開始しており、キャッシュラインバウンダリでのブロックインが観察されます。
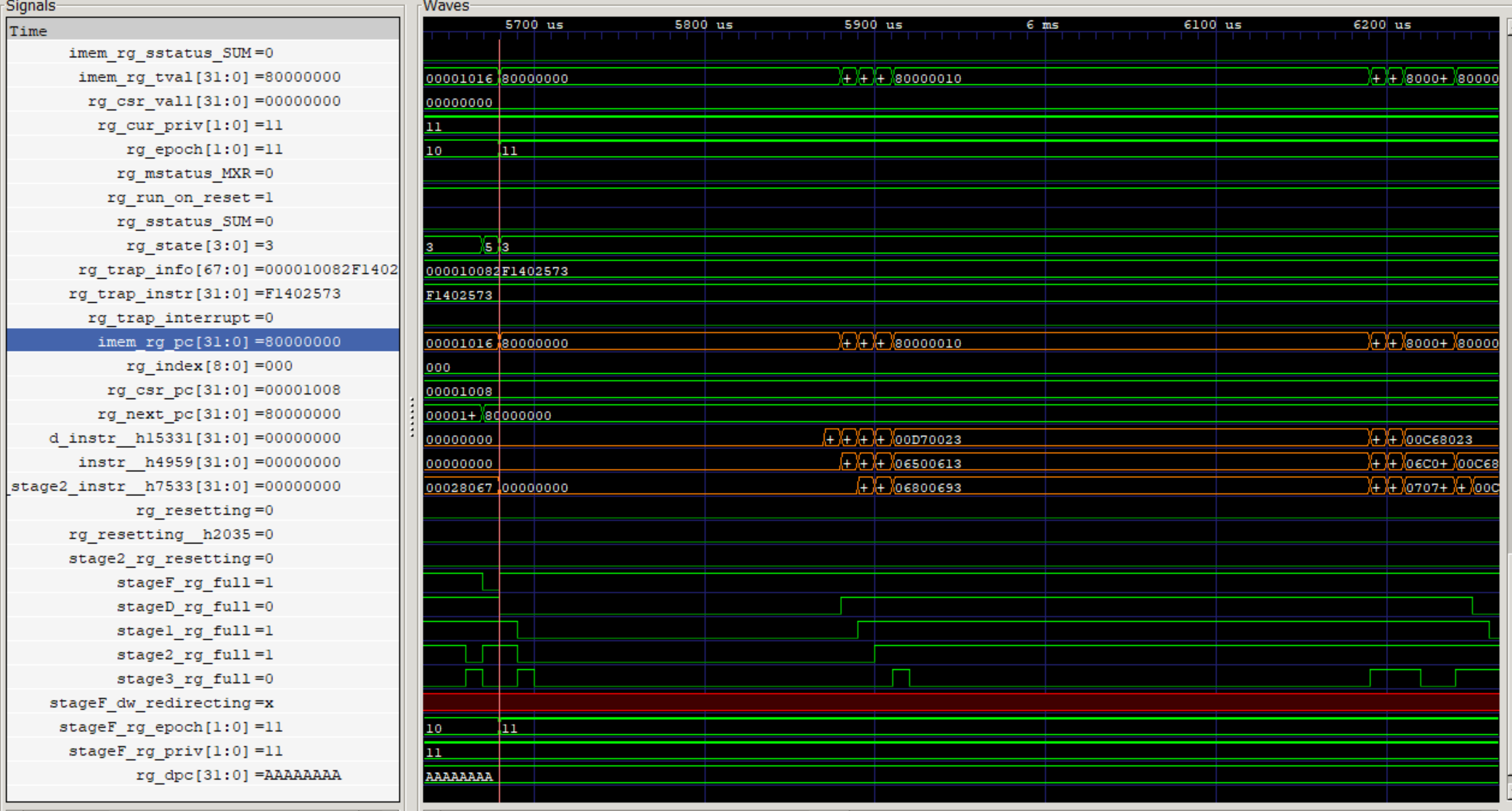
2回目に実行する場合は基本的にキャッシュヒットし、1サイクルで動作しています。
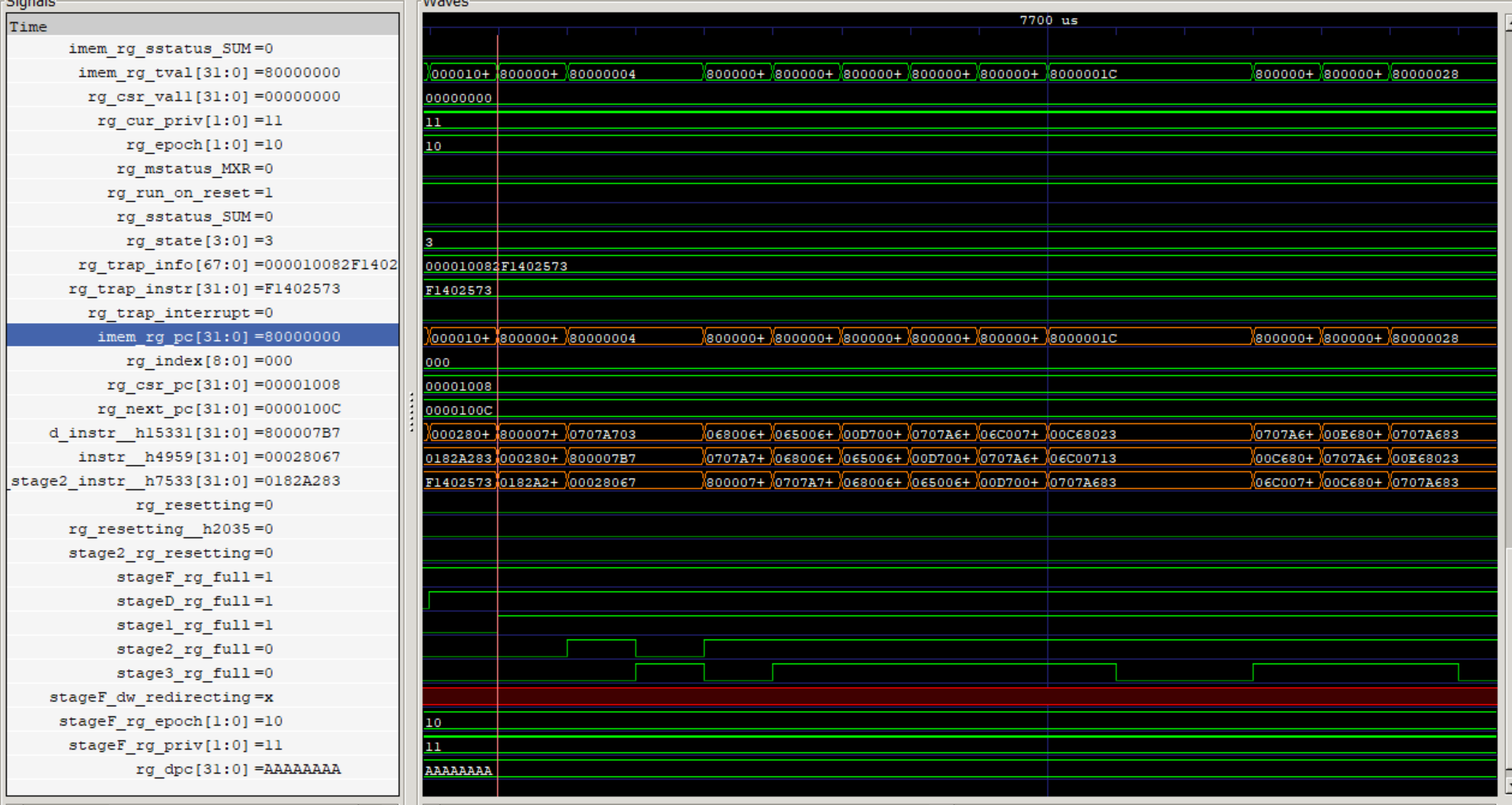
BsimにはUARTが実装されているため、UARTに対して、\$68('h'),\$65('e'),\$6c('l'),\$6c('l'),\$6f('o'),\$21('!'),\$0a('lf')と出力されていることが確認できます。
|
17 |
RISC-Vの調査 (6) |
Bsimによるシミュレーション
QemuのシミュレーションからBsimのシミュレーションに切り替えます。ここで、Flute SoCではUARTのアドレスが異なっているため、テストプログラムのUARTアドレスを
<volatile char* UART0_ADDR = (char*)0x10000000;
>volatile char* UART0_ADDR = (char*)0xc0000000;
と変更した上でコンパイルします。
$ riscv32-unknown-elf-gcc -march=rv32i -mabi=ilp32 -nostartfiles -Tlink.lds -Wall -O2 hello.c -o hello.elf
ここで、リンカへの指示であるlink.ldsは以下のようにしています。
OUTPUT_ARCH("riscv")
ENTRY(main)
SECTIONS
{
. = 0x80000000;
.text.startup : { *(.text.startup) }
.text : {
_start = .;
*(.text);
_text_end = .;
exit = .;
}
.rodata : { *(.rodata) }
.sdata : { *(.sdata) }
.bss : { *.(.bss) }
/DISCARD/ : { *(.comment);
*(.riscv.attributes);
*(.strtab*);
*(.shstrtab);
}
. = ALIGN(8);
= . + 0x4000;
sp_top = .;
}
前稿で作成したelfを、Bsimによるシミュレーションが可能なhexファイルに変換します。これはFlute/Tests/elf_to_hex/elf_to_hexで行います。
$ ../Flute/Tests/elf_to_hex/elf_to_hex hello.elf Mem.hex
c_mem_load_elf: hello.elf is a 32-bit ELF file
Section .text.startup : addr 80000000 to addr 8000006c; size 0x 6c (= 108) bytes
Section .sdata : addr 80000068 to addr 80000070; size 0x 8 (= 8) bytes
Section .comment : Ignored
Section .riscv.attributes: Ignored
Section .symtab : Searching for addresses of '_start', 'exit' and 'tohost' symbols
Writing symbols to: symbol_table.txt
No 'exit' label found
No 'tohost' symbol found
Section .strtab : Ignored
Section .shstrtab : Ignored
Min addr: 80000000 (hex)
Max addr: 80000073 (hex)
Writing mem hex to file 'Mem.hex'
Subtracting 0x80000000 base from addresses
作成されたhello.hexの内容は以下のようになっています。逆アセンブルリストと比較して概ね良さそうです。
@0000000 // raw_mem addr; byte addr: 00000000
00c6802306c007130707a68300d7002306500613068006930707a703800007b7 // raw_mem addr 00000000; byte addr 00000000
0707a70300d7002306f006930707a70300e680230707a68300e680230707a683 // raw_mem addr 00000001; byte addr 00000020
000057b706c7a703800007b700e7802300a007130707a78300d7002302100693 // raw_mem addr 00000002; byte addr 00000040
00000000000000000000000010000000001000000000806700f7102355578793 // raw_mem addr 00000003; byte addr 00000060
@07fffff // last raw_mem addr; byte addr: 0fffffe0
000000000000000000000000000000000000000000000000000000000000000 // raw_mem addr 007fffff; byte addr 0fffffe0
|
15 |
RISC-Vの調査 (5) |
開発環境のインストール
開発環境のインストールを行います。最初にct-ngをインストールしようとしたのですが、RV32ではうまく行きませんでした。そこで、この記事を参考にインストールを実施しました。make中にインストールもしているので、あらかじめ/opt/riscvを作成しておき、記事中にもあるように自分が書き込み可能にしておくのが良さそうです。
qemuについてもこの記事のとおりにインストールしますが、
ERROR: glib-2.48 gthread-2.0 is required to compile QEMU
このようなエラーが出ました。私はFedora32を使用しているので、
$ sudo dnf install glib2 glib2-devel pixman-devel
と不足しているパッケージを追加したところ、configureが通ったので、makeします。
テストプログラム実行
早速、テストプログラムhello.cをコンパイルして実行してみます。Qemuを前提とするプログラムで、QemuのUartとシミュレーション停止アドレスが定義されています。
volatile char* UART0_ADDR = (char*)0x10000000;
volatile short* VIRT_TEST_ADDR = (short*)0x100000;
void _start(void) __attribute__((section(".text.startup")));
void _start(void) {
*UART0_ADDR = 'h';
*UART0_ADDR = 'e';
*UART0_ADDR = 'l';
*UART0_ADDR = 'l';
*UART0_ADDR = 'o';
*UART0_ADDR = '!';
*UART0_ADDR = '\n';
*VIRT_TEST_ADDR = 0x5555;
}
gccによりコンパイルし、qemuによりシミュレーションを行います。
$ riscv32-unknown-elf-gcc -march=rv32i -mabi=ilp32 -nostartfiles -Tlink.lds -Wall -O2 hello.c -o hello.elf
$ qemu-system-riscv32 -nographic -M virt -m 4096 -serial mon:stdio -bios none -kernel hello.elf
hello!
Qemuによりシミュレーションができました。また、逆アセンブラはobjdumpであり、以下の方法でアセンブルリストが確認できます。
$ riscv32-unknown-elf-objdump -D hello.elf
hello.elf: ファイル形式 elf32-littleriscv
セクション .text.startup の逆アセンブル:
80000000 <_start>:
80000000: 800007b7 lui a5,0x80000
80000004: 0707a703 lw a4,112(a5) # 80000070
80000008: 06800693 li a3,104
8000000c: 06500613 li a2,101
80000010: 00d70023 sb a3,0(a4)
80000014: 06c7a683 lw a3,108(a5)
80000018: 06c00713 li a4,108
8000001c: 00c68023 sb a2,0(a3)
80000020: 06c7a683 lw a3,108(a5)
80000024: 00e68023 sb a4,0(a3)
:
|
12 |
RISC-Vの調査 (4) |
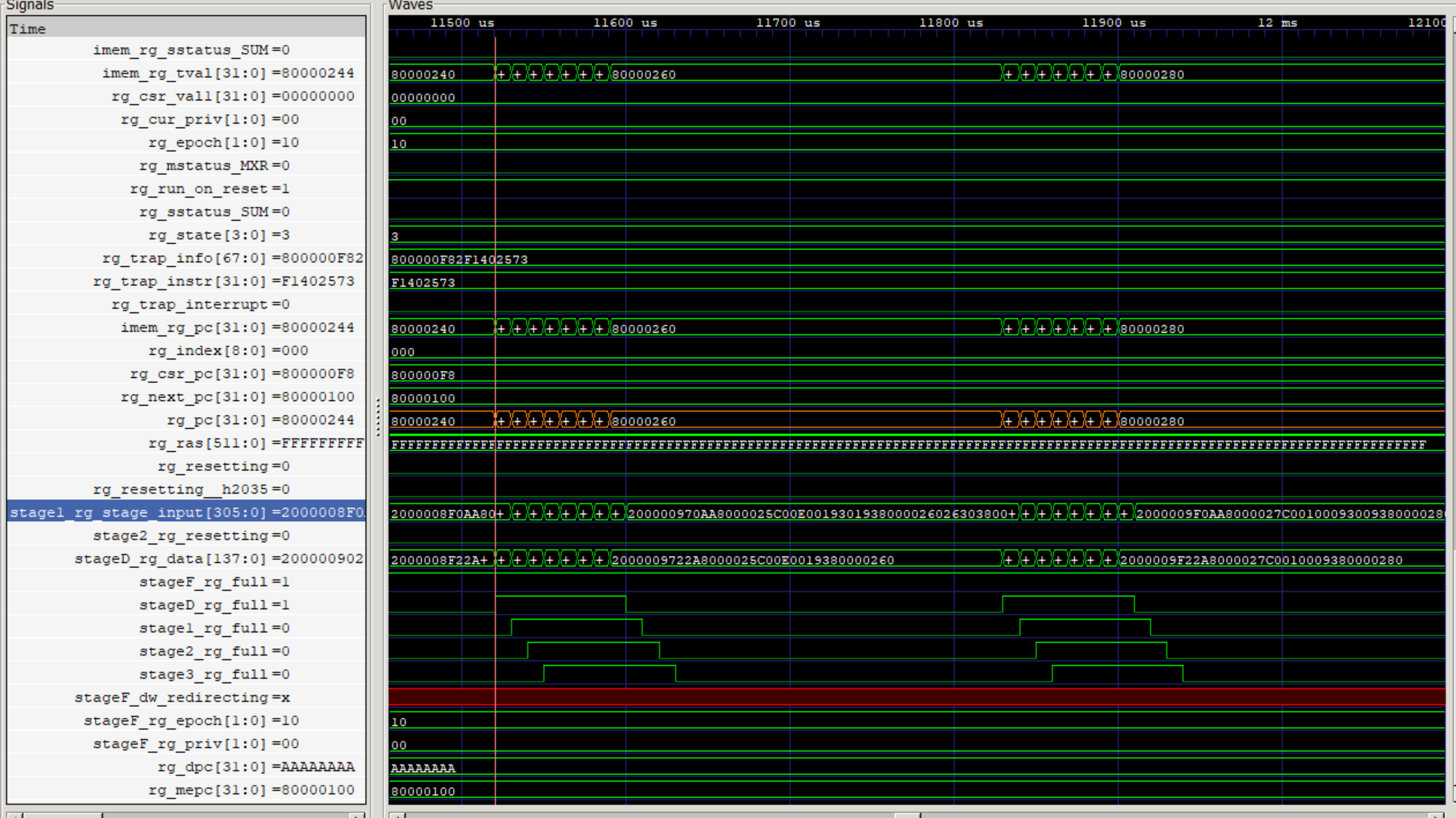
シミュレーションモデルの波形を観測してみます。テストプログラムは、\$80000000から始まっていますが、シミュレーションは\$1000から始まっています。これはBootROMのようです。BootROMのブロックインが19サイクルかかっています。
図275.1はGtkwaveによるシミュレーション波形で、pcをオレンジ色で塗っています。
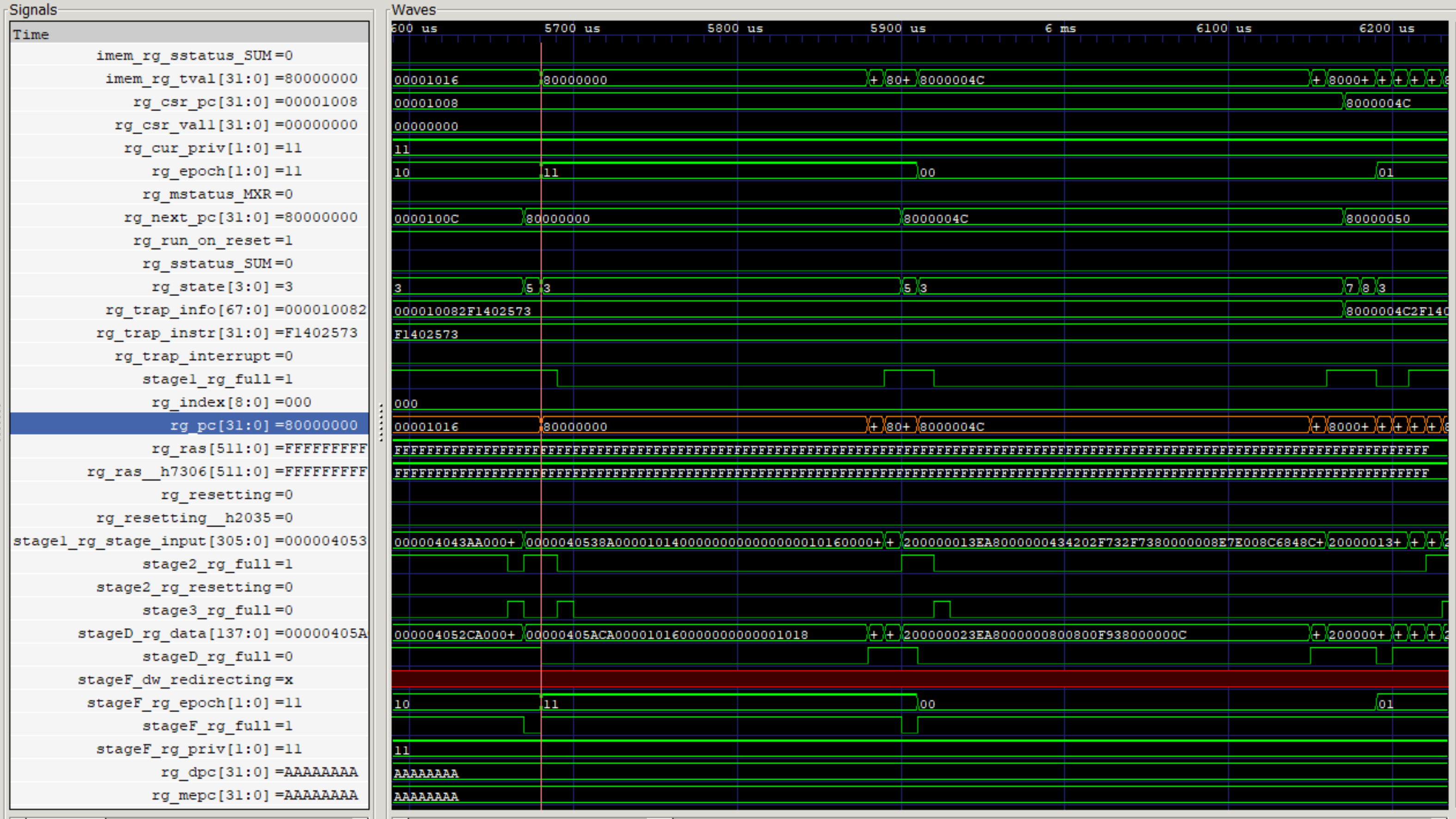
|
11 |
RISC-Vの調査 (3) |
前々稿の記事において、シミュレーションモデルが生成できましたが、これを実行させてみます。
テストプログラムは、add命令単体テストで、
80000000 <_start>:
80000000: 04c0006f j 8000004c
8000004c :
8000004c: f1402573 csrr a0,mhartid
80000050: 00051063 bnez a0,80000050
80000054: 00000297 auipc t0,0x0
80000058: 01028293 addi t0,t0,16 # 80000064
8000005c: 30529073 csrw mtvec,t0
80000060: 18005073 csrwi satp,0
:
80000100 :
80000100: 00000093 li ra,0
80000104: 00000113 li sp,0
80000108: 00208f33 add t5,ra,sp
8000010c: 00000e93 li t4,0
80000110: 00200193 li gp,2
80000114: 4ddf1663 bne t5,t4,800005e0
80000118 :
80000118: 00100093 li ra,1
8000011c: 00100113 li sp,1
80000120: 00208f33 add t5,ra,sp
80000124: 00200e93 li t4,2
80000128: 00300193 li gp,3
8000012c: 4bdf1a63 bne t5,t4,800005e0
:
のように構成されています。Bsimによるシミュレーションは、+v1で命令トレースが、+v2でパイプラインステージの内容を表示させるようになっています。+v2で実行させた結果をgrepにより計数してみると、表274.1のようになりました。パイプラインの各ステージの出力ステータスの意味は、以下のとおりです。
- EMPTY --- 入力が来ないためアイドルとなっている
- BUSY --- 入力があるが、処理中で出力がレディではない
- PIPE --- 入力があり、パイプラインは正常な出力を行っている
- NONPIPE --- 入力があり、出力は例外的な場合(トラップ等)
| 状態 | StageF | StageD | Stage1 | Stage2 | Stage3 |
|---|---|---|---|---|---|
| BUSY | 1,118 | 0 | 23 | 26 | 0 |
| EMPTY | 22 | 1,094 | 959 | 1,373 | 1,409 |
| PIPE処理 | 743 | 789 | 901 | 484 | 474 |
| 合計 | 1,883 | ||||
- 試験命令数は473命令だったので、CPI(Cycles Per Instruction)は3.98となりました。命令キャッシュミスのためにかなり大きく(悪く)なっています。
- マシンサイクル1,883サイクルのうち、実際に処理しているのは半分くらいであり、主なパイプラインストールは命令キャッシュによるものだと考えられます。
- StageFがBUSYの分だけStageD以降がEMPTYとなり、空いています。すなわち約1,100サイクルがパイプラインバブルとなっています。
- Stage1に対してStage2のPIPE処理が半分なのは、ロードストア命令が半分(レジスタとロードストアが1:1)くらいだからかもしれません。
- StageDに対してStage1のPIPE処理が増加しているのは、マルチサイクル命令のためかもしれません。
これだけ見るとかなり効率が悪そうですが、対象がテストプログラムでループが無いため、基本的にキャッシュミスが頻発します。一般のアプリケーションのようにループがあれば、ずっと効率が向上するはずです。
|
10 |
RISC-Vの調査 (2) |
Fluteの階層構造
CPUの階層構造を図273.1に示します。5段のパイプラインは図273.1に示すように、"F"(命令Fetchステージ), "D"(命令デコードステージ), "1"(命令実行ステージ), "2"(メモリアクセス、長レインテンシステージ), "3"(ライトバックステージ)とステージ名が付けられています。なぜステージ"1”,"2",...,"5"でないかと言えば、3段パイプラインのPiccoloとステージを共用しているため書かれていました。Piccoloではパイプラインステージは”1", "2", "3"と名付けられており、Fluteでは、Piccoloの"1"を"F", ”D”, "1"に分解したようです。

各モジュールがmk〇〇と名付けられているのはBSVのお作法です。モジュールとそのインスタンスは一対nの関係にあり、モジュール名はいわばテンプレート名を意味するため、モジュールからインスタンスがmakeされるということを表しています。例えば上図のmkMMU_Cacheはどちらも同じモジュールですが、それぞれ命令用とデータ用に2個インスタンシエートしています。
キャッシュは上記のように、パラメタライズ可能な命令キャッシュ、データキャッシュの2つがあります。その他に、分岐予測器があります。
|
9 |
RISC-Vの調査 |
BluespecのFluteプロセッサ
BluespecのBSVが読めるようになったところで、引き続いてFluteプロセッサの調査を行います。FluteはBluespecの開発したRISC-Vアーキテクチャの5段パイプラインRISC CPUです。それだけでなく、仮想記憶をサポートしているため、Linuxが動作します。(ページ)テーブルウォークはMMU内のハードウェアが実行します。ソースではステートベース設計のFSMで実装されていました。
Githubからダウンロード
$ git clone https://github.com/bluespec/Flute.git
としてGithubからダウンロードします。
RV32ACIMUアーキテクチャのBsimモデルの作成
アーキテクチャには各種ありますが、比較的軽いもの、例えば32bit、Floating無しのマイクロアーキテクチャを選択します。
$ cd builds/RV32ACIMU_Flute_bluesim
として、ターゲットディレクトリに移行します。
$ make all
と実行すると、
:
Simulation shared library created: exe_HW_sim.so
Simulation executable created: ./exe_HW_sim
INFO: linked bsc-compiled objects into Bluesim executable
$
このように、bsvで書かれたソースファイルがbscによりコンパイルされ、シミュレーションモデルであるexe_HW_simが生成されます。
RV32ACIMUアーキテクチャのBsimモデルの試験
$ make test
により、出来上がったシミュレーションモデルが、RISC-Vのテストスイートによりテストされます。
$ make test
make -C ../../Tests/elf_to_hex
make[1]: Entering directory '/home/sakurai/src/bsv/riscv/Flute/Tests/elf_to_hex'
make[1]: 'elf_to_hex' is up to date.
make[1]: Leaving directory '/home/sakurai/src/bsv/riscv/Flute/Tests/elf_to_hex'
../../Tests/elf_to_hex/elf_to_hex ../../Tests/isa/rv32ui-p-add Mem.hex
c_mem_load_elf: ../../Tests/isa/rv32ui-p-add is a 32-bit ELF file
Section .text.init : addr 80000000 to addr 80000604; size 0x 604 (= 1540) bytes
Section .tohost : addr 80001000 to addr 80001048; size 0x 48 (= 72) bytes
Section .riscv.attributes: Ignored
Section .symtab : Searching for addresses of '_start', 'exit' and 'tohost' symbols
Writing symbols to: symbol_table.txt
No 'exit' label found
Section .strtab : Ignored
Section .shstrtab : Ignored
Min addr: 80000000 (hex)
Max addr: 80001047 (hex)
:
================================================================
Bluespec RISC-V standalone system simulation v1.2
Copyright (c) 2017-2019 Bluespec, Inc. All Rights Reserved.
================================================================
INFO: watch_tohost = 1, tohost_addr = 0x80001000
1: top.soc_top.mem0_controller_axi4_deburster::AXI4_Deburster.rl_reset
2:top.soc_top.rl_reset_start_initial ...
3: Core.rl_cpu_hart0_reset_from_soc_start
================================================================
CPU: Bluespec RISC-V Flute v3.0 (RV32)
Copyright (c) 2016-2020 Bluespec, Inc. All Rights Reserved.
================================================================
6: D_MMU_Cache: cache size 8 KB, associativity 2, line size 32 bytes (= 8 XLEN words)
6: I_MMU_Cache: cache size 8 KB, associativity 2, line size 32 bytes (= 8 XLEN words)
512: top.soc_top.core.cpu.rl_reset_complete: restart at PC = 0x1000
514: Near_Mem_IO_AXI4.set_addr_map: addr_base 0x2000000 addr_lim 0x200c000
514: Core.rl_cpu_hart0_reset_complete
515: Mem_Controller.set_addr_map: addr_base 0x80000000 addr_lim 0x90000000
515:top.soc_top.rl_reset_complete_initial
instret:0 PC:0x1000 instr:0x297 priv:3
instret:1 PC:0x1004 instr:0x2028593 priv:3
instret:2 PC:0x1008 instr:0xf1402573 priv:3
:
instret:471 PC:0x80000044 instr:0xfc3f2023 priv:3
instret:472 PC:0x80000048 instr:0xff9ff06f priv:3
instret:473 PC:0x80000040 instr:0x1f17 priv:3
2396: Mem_Controller.rl_process_wr_req: addr 0x80001000 () data 0x1
PASS
2397: top:.rl_terminate: soc_top status is 0x1 (= 0d1)
Simulation speed: 2396 cycles, 60915008 nsecs = 39333 cycles/sec
テストスイートのelfを、elf_to_hexにより、asciiのメモリイメージファイルに変換しています。
これはadd命令単体のテストですが、全てのテストを行うには、以下のように実行します。
$ make isa_tests
と実行すると、
:
Worker 1: Test: rv32um-p-mul PASS [So far: total 67, executed 34, PASS 34, FAIL 0]
Worker 0 executed 33 tests, of which 33 passed
Worker 1 executed 34 tests, of which 34 passed
Total tests: 67 tests
Executed: 67 tests
PASS: 67 tests
FAIL: 0 tests
Finished running regressions; saved logs in Logs/
のように出力され、67個全てのテストが実行され、全てパスしたことが表示されます。
ページ:
