|
31 |
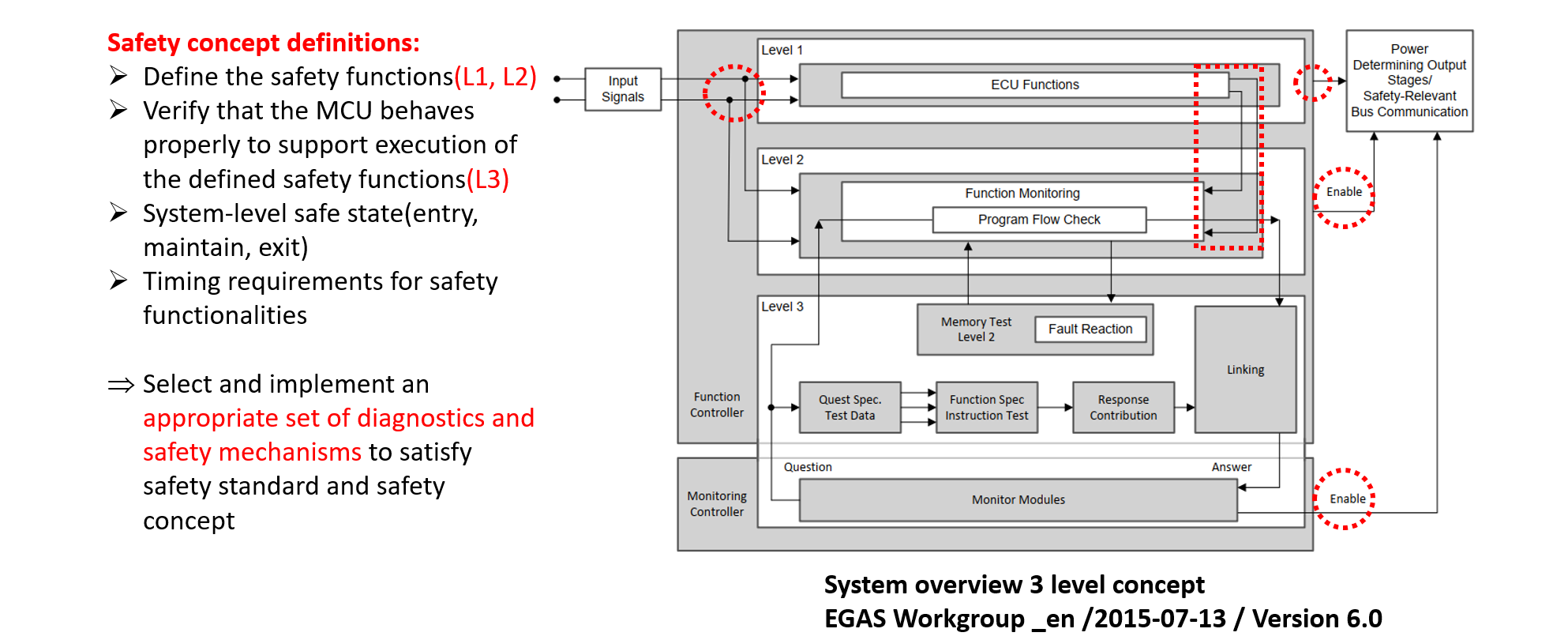
Fault treeの自動生成 (24) |
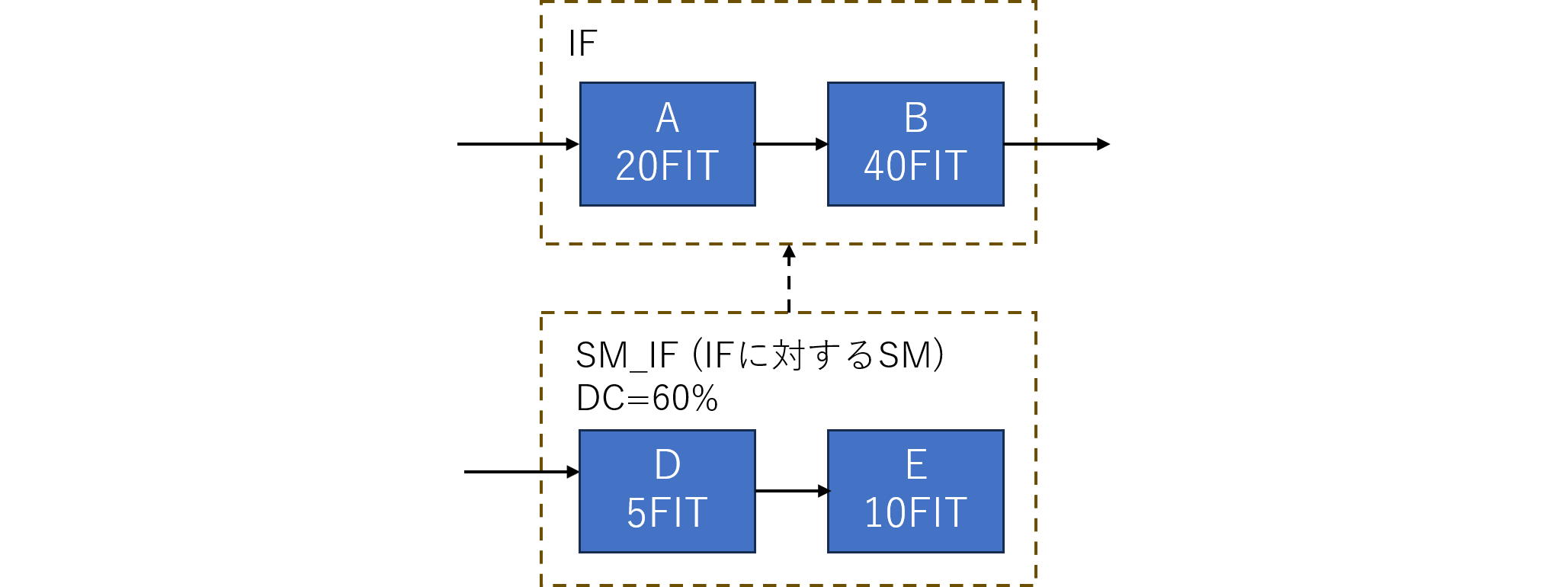
特にSMのパスの論理が分かりにくいので解説します。図941.1は前稿の図940.1のうちSM部を抜き出した図です。
$$\img[-1.35em]{/images/withinseminar.png}$$
図で見るように、SM部前半の検出手段は次の4つが存在します。
- APSの情報を受けTPSからのズレをメインマイコンが故障検出
- TPSの情報を受けAPSからのズレをメインマイコンが故障検出
- DRIVER_DIAGの故障診断をメインマイコンが故障検出
- サブマイコンによるメインマイコンの故障検出
RBDで書くとこのように、EGASシステムはいずれの故障が検出されてもORされ、リレーによりモータ電源が遮断される安全なシステムであると言えます。
一方FTでは動作ではなく故障を伝えるので、論理が反転となりORはANDになります。 RBDにおいては動作を
「いずれか一つの故障が検出されたら、モータ電源が遮断される」
と書き、FTでは
「全ての故障が起きた場合のみ、モータ電源が遮断されない」
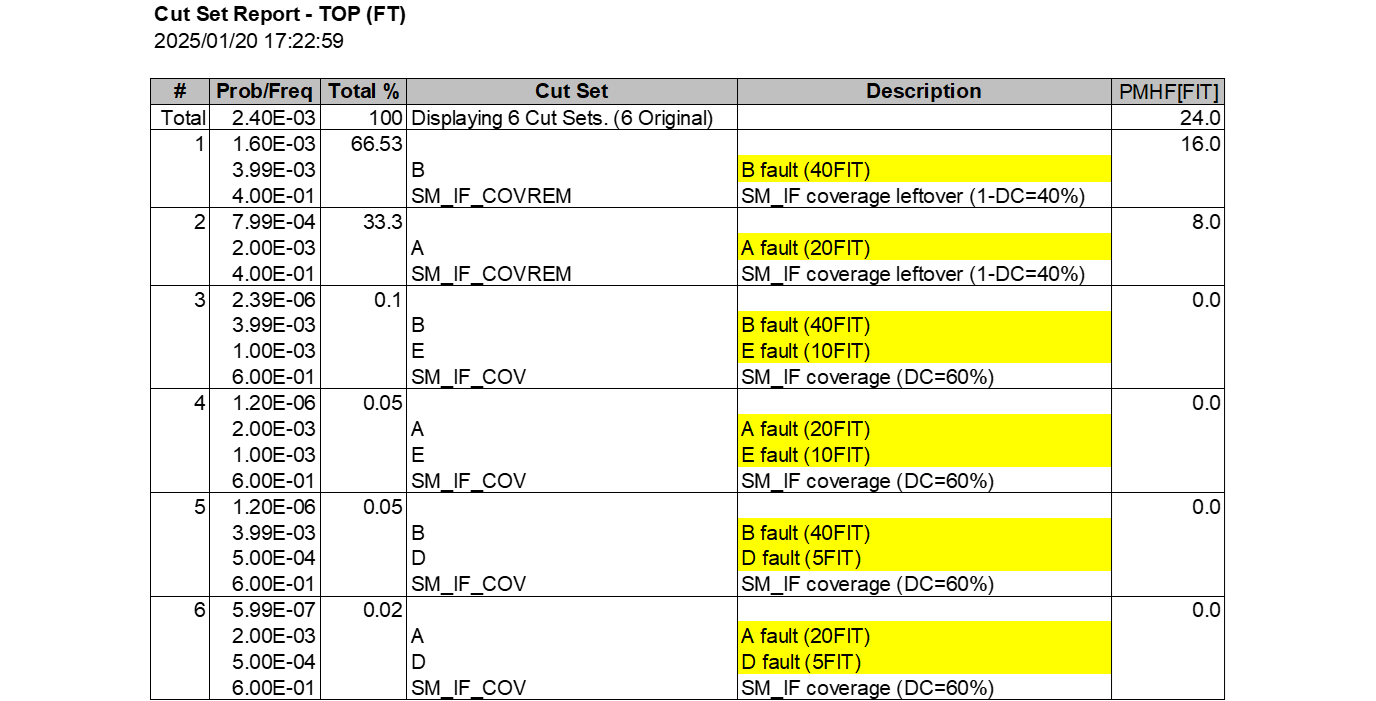
と故障を書くわけです。つまりSMの動作ではなく、SMの故障について考えなければなりません。従って、図941.2のように、全ての故障検出のAND関係となります。

ただしSM部後半の手段のほうはこれと異なり、メインマイコンからリレードライバ経由でリレーが直列になっているため、メインマイコンかリレードライバのいずれかの故障でモータ電源が遮断されないOR関係となります。
結果として、SM部の前半のANDと後半のORを組み合わせると図941.3のようになります。これも手で構成したのではなく、ChatGPT により自動生成されたものです。 $$\img[-1.35em]{/images/withinseminar.png}$$
なお、本稿はRAMS 2026に投稿予定のため一部を秘匿していますが、論文公開後の2026年2月頃に開示予定です。