|
29 |
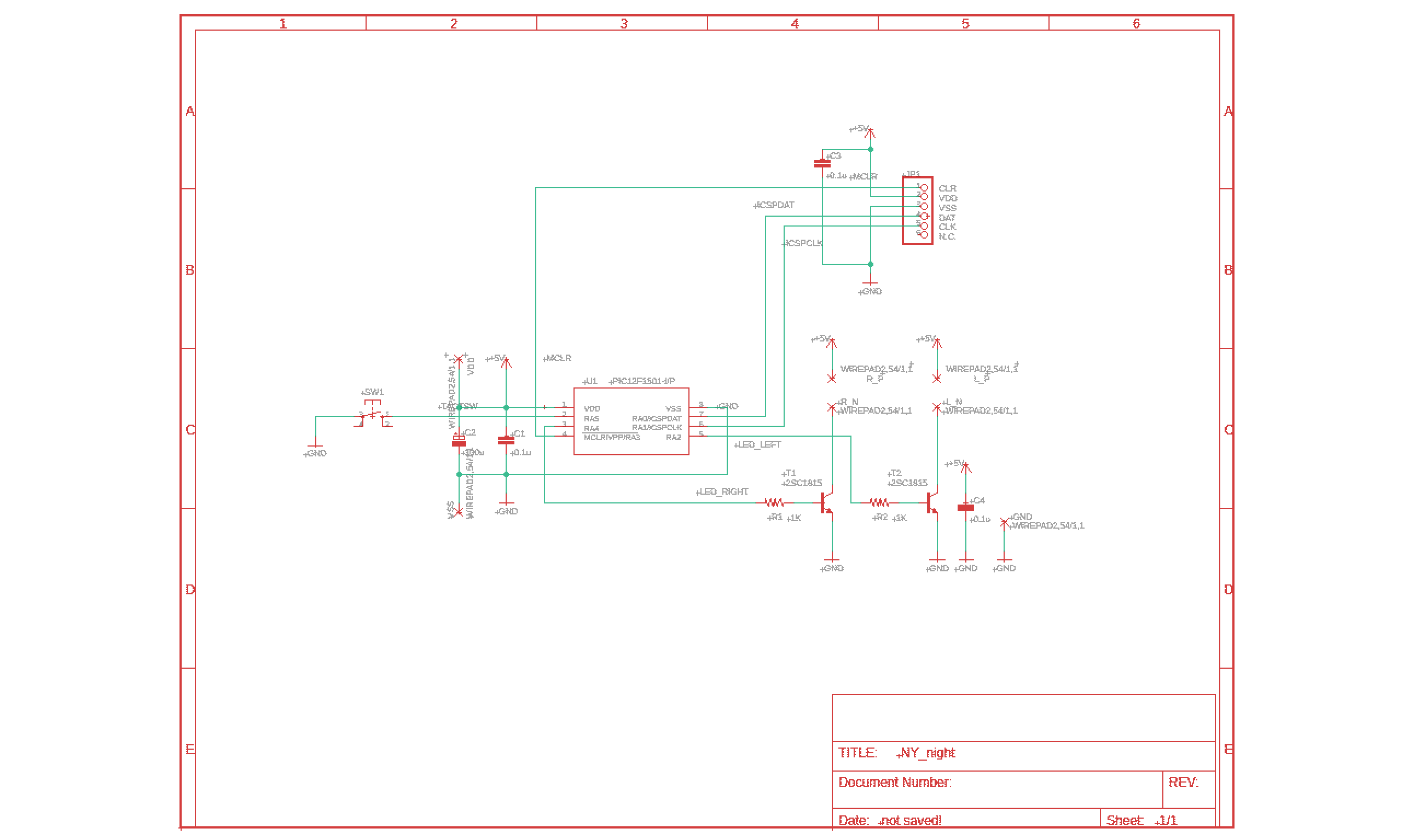
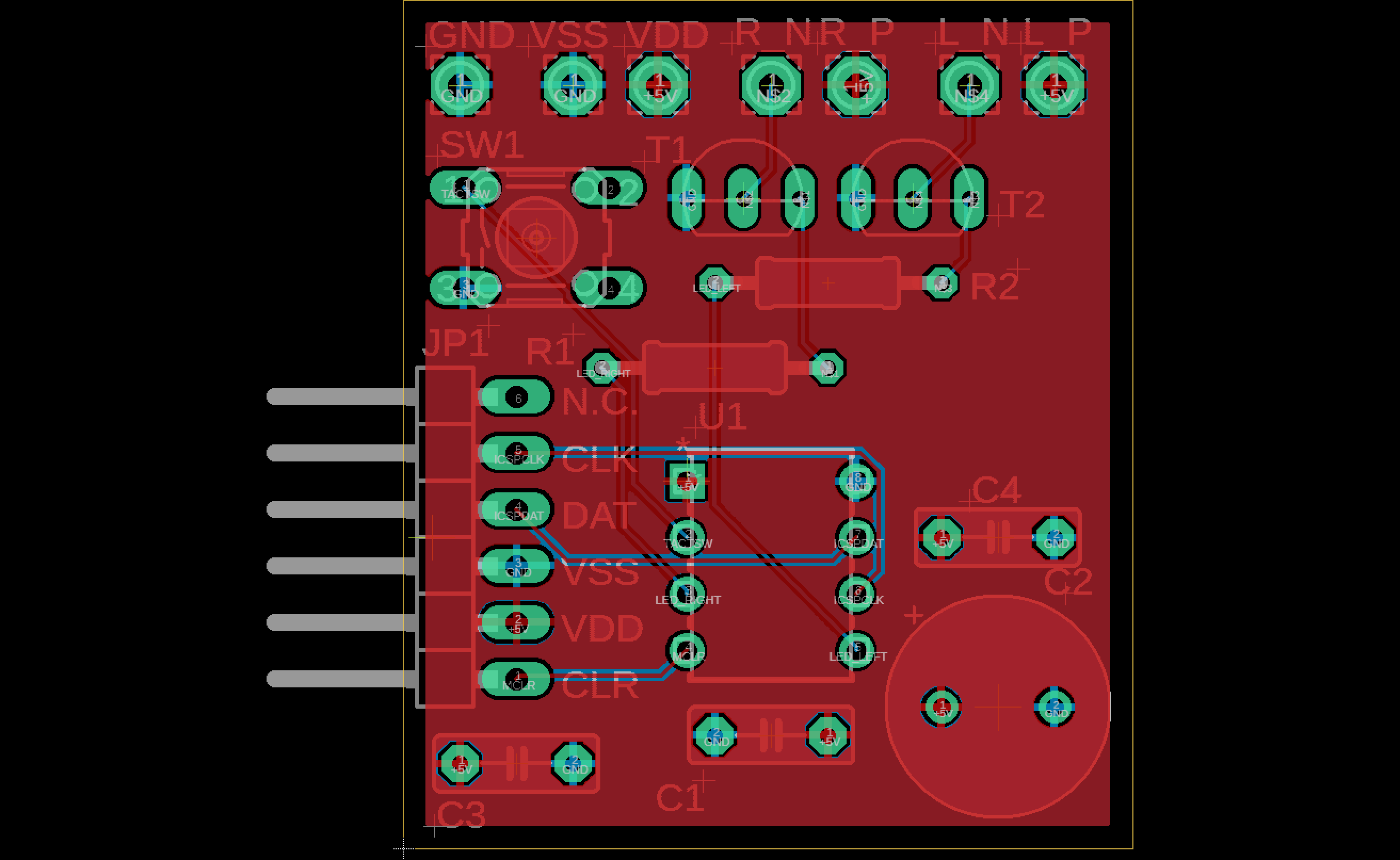
PICによるLEDドライバボードの設計 (3) |
Geminiに設計してもらったプログラムを以下に示します。
// --- コンフィギュレーション設定(マイコンの基本動作設定) ---
#pragma config FOSC = INTOSC // 内蔵クロックを使用
#pragma config WDTE = OFF // ウォッチドッグタイマーOFF
#pragma config PWRTE = ON // パワーアップタイマーON
#pragma config MCLRE = OFF // 4番ピンをリセットに使わずGPIO(RA3)として使う
#pragma config CP = OFF // コードプロテクトOFF
#pragma config BOREN = ON // 電圧低下で安全停止
#pragma config CLKOUTEN = OFF // クロック出力OFF
#pragma config LVP = OFF // 低電圧プログラミングOFF(ICSP動作を安定させる)
#include <xc.h>
// 動作クロックの定義(__delay_msの計算に必要)
#define _XTAL_FREQ 4000000
void main(void) {
// --- マイコンの初期化 ---
OSCCON = 0x6A; // 内部クロック4MHzに設定
ANSELA = 0x00; // 全ピンをデジタルモードに設定(スイッチ入力に必須)
TRISA = 0b00100000; // RA5(2番ピン)を入力、他を出力に設定
WPUA = 0b00100000; // RA5を内部プルアップ設定
OPTION_REGbits.nWPUEN = 0; // 内部プルアップ機能を有効化
// PWM(調光)の初期設定
PWM1CON = 0xC0; // PWM1(5番ピン/RA2)を有効化
PWM3CON = 0xC0; // PWM3(3番ピン/RA4)を有効化
T2CON = 0x04; // Timer2 ON, プリスケーラ1:1
PR2 = 255; // PWMの周期設定
// 制御用変数の宣言
unsigned char mode = 1; // 0:消灯, 1:交互ゆらぎ, 2:全点灯, 3:点滅
unsigned char duty_L = 0; // 左側の明るさ用変数
signed char direction = 5; // 明るさの変化量(プラスで明るく、マイナスで暗く)
while(1) {
// --- モード切り替えスイッチ判定(2番ピンをGNDに落とすと反応) ---
if (RA5 == 0) {
__delay_ms(20); // チャタリング防止
if (RA5 == 0) { // 押し続けられているか再確認
while(RA5 == 0); // 指を離すまで待機
__delay_ms(20); // 離した後の安定待ち
mode++; // モードを1つ進める
if (mode > 3) mode = 0; // モード0〜3を循環
// モード切替時に明るさ変数をリセット
duty_L = 0;
direction = 5;
}
}
// --- 各モードの動作実行 ---
switch(mode) {
case 0: // 【全消灯】
PWM1DCH = 0;
PWM3DCH = 0;
break;
case 1: // 【アナログ交互ゆらぎ】★初期起動モード
PWM1DCH = duty_L; // 5番ピン(L)を出力
PWM3DCH = (unsigned char)(255 - duty_L); // 3番ピン(R)は逆位相で出力
// 明るさを変化させる
if (direction > 0) {
if (duty_L < 250) {
duty_L += 5;
} else {
direction = -5; // 上限で反転
}
} else {
if (duty_L > 5) {
duty_L -= 5;
} else {
direction = 5; // 下限で反転
}
}
__delay_ms(40); // 変化のスピード調整(ニューヨークの夜景風)
break;
case 2: // 【全点灯】
PWM1DCH = 255;
PWM3DCH = 255;
break;
case 3: // 【同時点滅】
PWM1DCH = 255;
PWM3DCH = 255;
__delay_ms(300);
PWM1DCH = 0;
PWM3DCH = 0;
__delay_ms(300);
break;
}
__delay_ms(10); // ループの安定用ウェイト
}
}
コンパイル(build)は金槌のアイコンをクリックします。PICへの書き込みはダウンロードのような下向き矢印アイコンをクリックします。読み出しはアップロードのような上向き矢印アイコンをクリックします。書き込んだPICかみ書き込みかは読みだすとわかります。以下はプログラムしたPICをhexで読みだしたファイルの中身です。
:020000040000FA
:100000000128FE2BFF3FFF3FFF3FFF3FFF3FFF3F2A
:10001000FF3FFF3FFF3FFF3FFF3FFF3FFF3FFF3FF0
:10002000FF3FFF3FFF3FFF3FFF3FFF3FFF3FFF3FE0
:10003000FF3FFF3FFF3FFF3FFF3FFF3FFF3FFF3FD0
:10004000FF3FFF3FFF3FFF3FFF3FFF3FFF3FFF3FC0
:
:10061000FF3FFF3FFF3FFF3FFF3FFF3FFF3FFF3FEA
:10062000FF3FFF3FFF3FFF3FFF3FFF3FFF3FFF3FDA
:10063000FF3FFF3FFF3FFF3FFF3FFF3FFF3FFF3FCA
:10064000FF3FFF3FFF3FFF3FFF3FFF3FFF3FFF3FBA
:10065000FF3FFF3FF501F31F2E2B2F2B362BF20907
:10066000F309F20A0319F30A0130F500F11F392BDF
:100670003A2B3F2BF009F109F00A0319F10A70082F
:1006800071040319442B452B6C2B0130F4004F2BC4
:100690000130F035F10D890B492B0130F407F11FC2
:1006A000522B532B482B71087302031D592B7008D2
:1006B0007202031C5C2B5D2B612B7008F202710827
:1006C000F33B0130F136F00C890B622B0130F40260
:1006D000031D6B2B6C2B532B75080319702B712B7F
:1006E000762BF209F309F20A0319F30A7308F100F1
:1006F0007208F0000800203021008C0023008C01DB
:10070000203024008C0021009513043020009C0030
:10071000FF309B00C0302C009300C0309900F801DE
:10072000F90120008C1A952B962BED2B0330F0004D
:100730000030F1007808013EF2000030793DF3000E
:1007400083312A2383317108F9007008F8000230E0
:10075000F7008630F6009930890BAC2BF60BAC2BEA
:10076000F70BAC2B000020008C1EB72BB82BB32B43
:10077000ED2BFF302C009200FF309800912BFA01F6
:100780007A082C0092007A0998000D30F600FC30AF
:10079000890BC82BF60BC82B0130FA077A0A031D08
:1007A000D22BD32BC02BFF30FA007A082C009200FA
:1007B0007A0998000D30F600FC30890BDD2BF60B22
:1007C000DD2B0130FA027A08031DE72BE82BD52B2D
:1007D000912B2C0092019801912B7908003A031972
:1007E000F22B912B7808003A0319B92B013A03191F
:1007F000BF2B033A0319E92B912B012820007B2BF7
:020000040001F9
:04000E00843FFF3FED
:08000000FF3FFF3FFF3FFF3F00
:00000001FF








{kind=link}