|
12 |
PUA関連論文Hokstad1997 (2) |
論文$\dagger$の続きです。
モデルDにおいては、 $$ I(t)=f(t-i\tau),\ t\in(i\tau, (i+1)\tau), i=0, 1, 2, ... $$ これは周期関数としては正しいですが、DC=100%として100%修理されていることに改善の余地があります。本来は2nd SMによる検出可否に分解し、露出時間は検出可の部分は$\tau$とし、不可の部分は車両寿命とすべきです。検出可否を考慮に入れれば、 $$ q(t)=(1-K)f(t)+Kf(u), u=t\bmod \tau $$ となりPUDの一般式となります。
また、著者によるmean number of failure (cumulative intensity)は、 $$ \require{color} \definecolor{pink}{rgb}{1.0,0.8,1.0} M(t)=\colorbox{pink}{$i$}F(\tau)+F(t-i\tau),\ t\in(i\tau, (i+1)\tau), i=0, 1, 2, ... $$ となっており、初項の$iF(\tau)$に疑問があります。
初項の導出の理由を示す部分を見てみましょう。原文では$n$となっていますが$i$に変えたのは、我々は$n=\lfloor t/\tau\rfloor$として使用しているためです。
As a last feature of model D observe that the mean number of failures up to time $t$ equals
モデルDの最後の特徴として、時刻$t$までの平均故障数が次に等しいことがわかる $$ M(t) = n\cdot F(\tau)+F(t - n\cdot\tau),\ \text{for }n\tau \le t\lt(n + 1)\tau. $$ In each interval there is either one failure or no failure, and of course $M(\tau)=F(\tau)=1-R(\tau)$ equals the probability of having one failure in the interval. In particular $M(n\cdot\tau)=n\cdot F(\tau)$, which is the relation to be used for estimating $i_{\tau}$.
各区間には故障が1回あるかないかであり、当然$M( \tau)=F( \tau)=1-R( \tau)$ はその区間に故障が1回ある確率に等しい。特に、$M(n\cdot \tau)=n\cdot F(\tau)$は、$i_{\tau}$を推定するための関係式である。
一区間の故障確率は、$M(\tau)=F(\tau)$であるから、$i\tau$における故障確率は$M(i\tau)=iF(\tau)$だとこのとですが、論文の最後のせいか十分な検討無しに書いたように思われます。そもそも$M(t)$はunavailabilityであるため、1を超えることはないはずです。
検証のためにChatGPTにより$M(t)$をグラフ化すると、
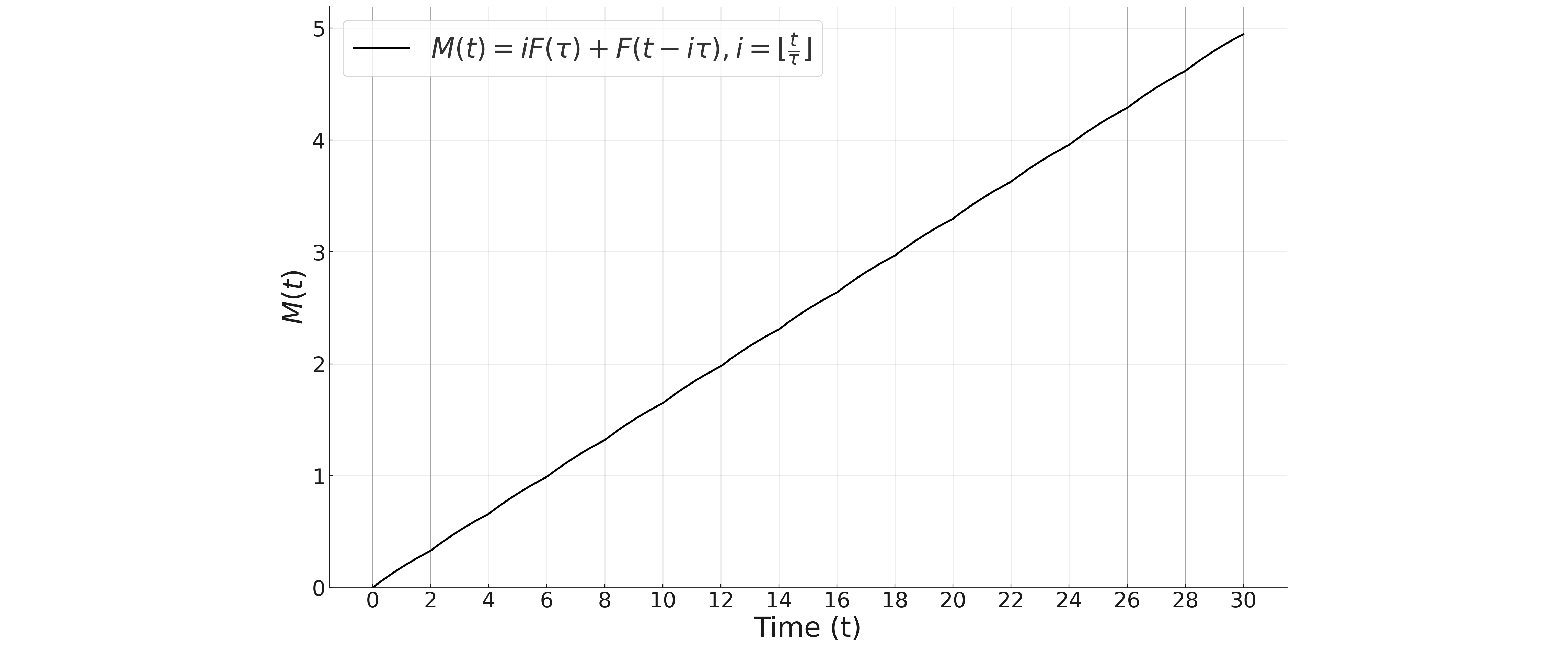
となり、明らかにおかしいです。$M(t)$は我々の記法によれば、PUAであり、 $$ Q(t)=(1-K)F(t)+KF(u), u=t\bmod \tau $$ と書くことができます。
本論文は、様々なモデルや関数の定義を与える良い論文ではあるものの、昔の論文のせいかグラフ図が手書きで不正確です。上記の誤りがあるだけでなく、PUAの一般式も求められていません。
$\dagger$ P. Hokstad, “The Failure Intensity Process and the Formulation of Reliability and Maintenance Models,” Rel. Eng. Syst. Safety, vol. 58, no. 1, pp 69–82, (Oct.) 1997.
