|
13 |
Pongと強化学習 (58) |
ネット情報を探してみたら以下の図を見つけました。
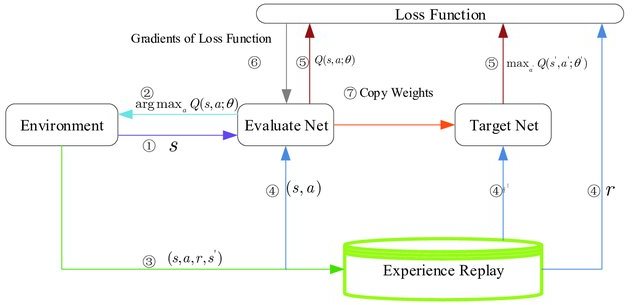
図の説明が言葉足らずなので、ChatGPTに補完してもらいました。
- エージェントは$Q(s,a)$が最大となる行動$a$を選択し、その結果として報酬$r$を環境から受け取る
- エージェントは経験$(s,a,r,s′)$をReplay Memoryに保存する
- Replay Memoryからサンプリングした経験を用いて、DQN損失を計算し、その結果をもとにQ-networkのパラメータを更新する
- 定期的に(特定のN回の更新ごとに)Q-networkのパラメータをTarget Q-networkにコピーする
元の論文の図の説明では、DQNアルゴリズムは3つの主要コンポーネントから構成されるとあります。
- 行動方針を定義するQネットワーク ($Q(s, a; θ)$)
- DQN損失項のターゲットQ値を生成するために使用されるターゲットQネットワーク($Q(s, a; θ^-)$)
- エージェントがQネットワークのトレーニングのためにランダムな遷移をサンプリングするために使用するリプレイメモリ
この図に従い、再度ChatGPTの書いた記事を見直してみたいと思います。
