
On October 29, 2024, FS Micro Corporation※1 announced that a research paper by President and CEO Atsushi Sakurai has been accepted at RAMS※2, an international conference organized by the IEEE※3 Reliability Society.
This marks the sixth consecutive year that a paper by Atsushi Sakurai has been accepted at RAMS. The paper is scheduled for presentation at RAMS 2025, to be held on January 28, 2025, in Florida, USA.

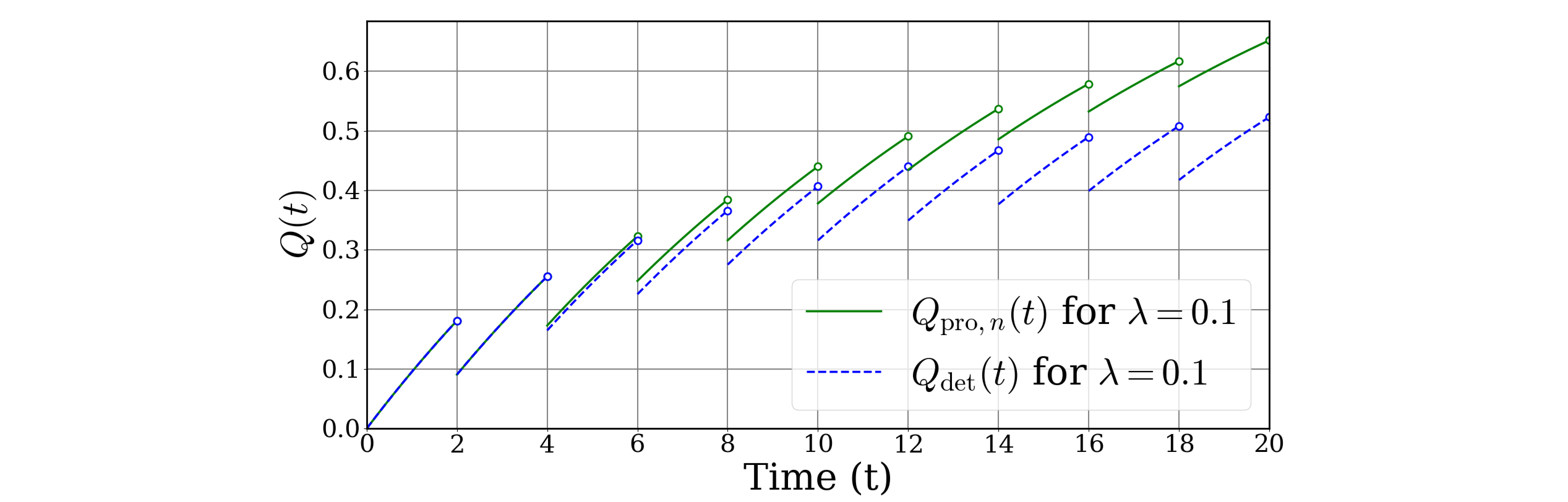
This paper focuses on the PMHF※4 formula in ISO 26262※5. In ISO 26262, the PMHF is positioned as a critical metric for evaluating the safety of automotive systems, yet its derivation process is not thoroughly explained. Since 2011, Atsushi Sakurai has been addressing this issue and proposed a more accurate formula for the PMHF at RAMS 2020.
In this paper, the behaviors of the two stochastic processes, the PUA※6 and the PUD※7, under periodic inspection are analyzed in detail, and rigorous formulas for these processes are derived. Furthermore, the paper compares the rigorous formulas with the proposed approximate formulas, demonstrating the effectiveness of the approximate formulas in practical PMHF calculations.
The proposed PMHF formula provides higher accuracy while also allowing for improved design constraints. Therefore, this research is expected to make a significant contribution to enhancing the reliability of automotive systems.
Notes
※1: FS Micro Corporation (Headquarters: Nagoya, Japan; President and CEO: Atsushi Sakurai) is a consulting firm specializing in functional safety (a methodology for ensuring that equipment function correctly by implementing various safety measures) for automotive systems.
※2: RAMS (the Reliability and Maintainability Symposium) is an international conference on reliability engineering held annually by the IEEE Reliability Society. The 71st conference will take place in 2025. For more information: https://rams.org/
※3: IEEE is the abbreviation for the Institute of Electrical and Electronics Engineers, the world's largest professional technical organization dedicated to advancing technology. For more information: https://ieee.org/
※4: PMHF stands for Probabilistic Metric for Random Hardware Failures, a key metric under ISO 26262. It represents the time-averaged probability of hazardous system failures over a vehicle’s lifetime.
※5: ISO 26262 is an international standard for functional safety of automotive electronic and electrical systems, aiming to reduce the risk of hazardous events occurring while driving to an acceptable level due to system failures.
※6: PUA or the Point Unavailability, one of the stochastic processes that define the PMHF. It represents the probability that a system is in a failed state at a specific point in time.
※7: PUD or the Point Unavailability Density, another stochastic process that defines the PMHF. It represents the probability density of unavailability.
Contact Information
Company Name: FS Micro Corporation
Representative: Atsushi Sakurai
Date of Establishment: August 21, 2013
Capital: 32 million yen
Business Description: Consulting services and seminars on functional safety for automotive electronic devices in compliance with ISO 26262
Head Office Address: 4-1-57 Osu, Naka-ku, Nagoya, Aichi 460-0011, Japan
Phone: +81-52-263-3099
Email: info@fs-micro.com
URL: https://fs-micro.com/
