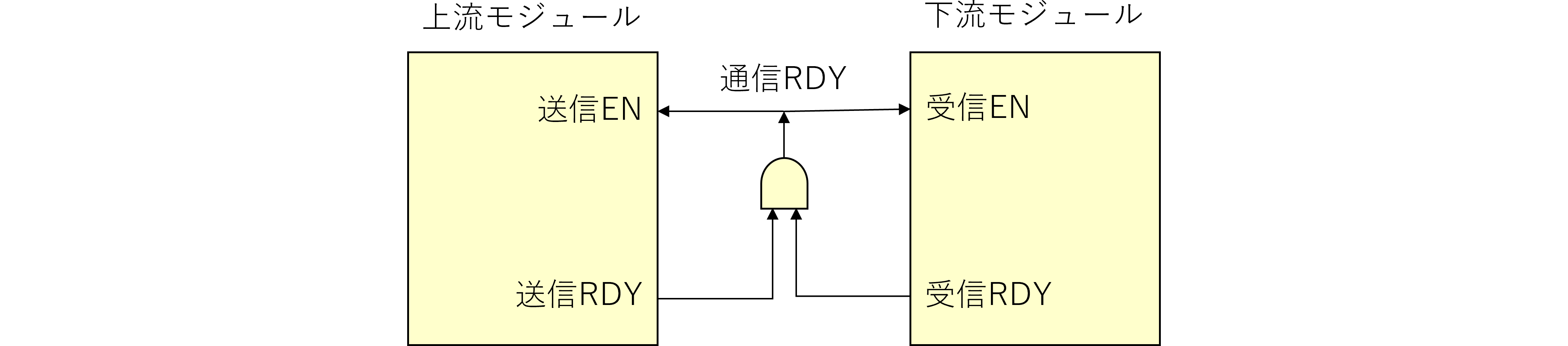
コール順位4位のsound関数は元々サウンドFSMを構成しており、それを起動するだけなので、このままでOKです。
最後にコール順位6位のketa関数をリファクタします。これは元は10進4桁の数値を表示する関数であり、一桁ずつ10^nを引いて商を求めるものでした。従ってStmtを用いてループを構成しており、汎用FSM起動マクロでもうまく行きましたが、一方で内部変数への競合の回避が困難でした。
ChatGPTに相談したところ、組み合わせ回路で可能とのことで全面リファクタしたものです。
// 14bit → BCD4(加算+比較のみ、組合せ)
function Tuple4#(UInt#(4), UInt#(4), UInt#(4), UInt#(4)) dec4_dd (UInt#(14) x);
Bit#(16) b16 = 0; // [15:12]=千, [11:8]=百, [7:4]=十, [3:0]=一
Bit#(14) bx = pack(x); // ★ UInt を Bit に変換してからビット参照
for (Integer i = 13; i >= 0; i = i - 1) begin
// 各桁 >=5 なら +3
for (Integer n = 0; n < 4; n = n + 1) begin
Bit#(4) nib = b16[n*4 + 3 : n*4];
if (nib >= 5) nib = nib + 3;
b16[n*4 + 3 : n*4] = nib;
end
// 左シフトして次ビットを流し込む
b16 = { b16[14:0], bx[i] };
end
UInt#(4) d0 = unpack(b16[3:0]);
UInt#(4) d1 = unpack(b16[7:4]);
UInt#(4) d2 = unpack(b16[11:8]);
UInt#(4) d3 = unpack(b16[15:12]);
return tuple4(d3, d2, d1, d0);
endfunction
よく見ると、dec4_dd関数には=は使われていますが、<=(レジスタ代入)は使われていません。これはdec4_ddには見かけはforループがあるものの、全てstaticに展開され、全体として組み合わせ回路になっていることがわかります。
最後にこれを用いてscoreとhigh_scoreを画面の特定の場所に表示する関数です。
// Draw Score and High-score
function Stmt scores;
match { .s3, .s2, .s1, .s0 } = dec4_dd(score);
match { .h3, .h2, .h1, .h0 } = dec4_dd(high_score);
return (seq
// display score
if (score > high_score) high_score <= score;
copyArea(zeroExtend(s3) << 3, 169, 38 , 24, 8, 8);
copyArea(zeroExtend(s2) << 3, 169, 38 + 8 , 24, 8, 8);
copyArea(zeroExtend(s1) << 3, 169, 38 + 16 , 24, 8, 8);
copyArea(zeroExtend(s0) << 3, 169, 38 + 24 , 24, 8, 8);
copyArea(zeroExtend(h3) << 3, 177, 110 , 24, 8, 8);
copyArea(zeroExtend(h2) << 3, 177, 110 + 8 , 24, 8, 8);
copyArea(zeroExtend(h1) << 3, 177, 110 + 16 , 24, 8, 8);
copyArea(zeroExtend(h0) << 3, 177, 110 + 24 , 24, 8, 8);
endseq);
endfunction
このようにバイナリを4桁BCD化する関数を組合わせ回路にしたところ、ワンサイクルなので回路は増加するかと思いきや、以下のように若干減少する結果になりました。組合せ回路は多少増えても10^nを引くループが8回削減された効果が大きいようです。
| BCD4桁表示を最適化前後 |
前 |
後 |
比較 |
| BSV合成 |
コンパイル時間 |
2:08 |
2:04 |
▲3.1% |
| Verilog合成 |
ファイルサイズ[KB] |
8,396 |
8,101 |
▲3.5% |
| 合成時間 |
1:01 |
0:54 |
▲11.5% |
| Vivado LUT数 |
5,901 |
5,565 |
▲5.7% |
| Vivado FF数 |
1,812 |
1,766 |
▲2.5% |
結果が良かったためこの最適化を採用します。
 前のブログ
次のブログ
前のブログ
次のブログ