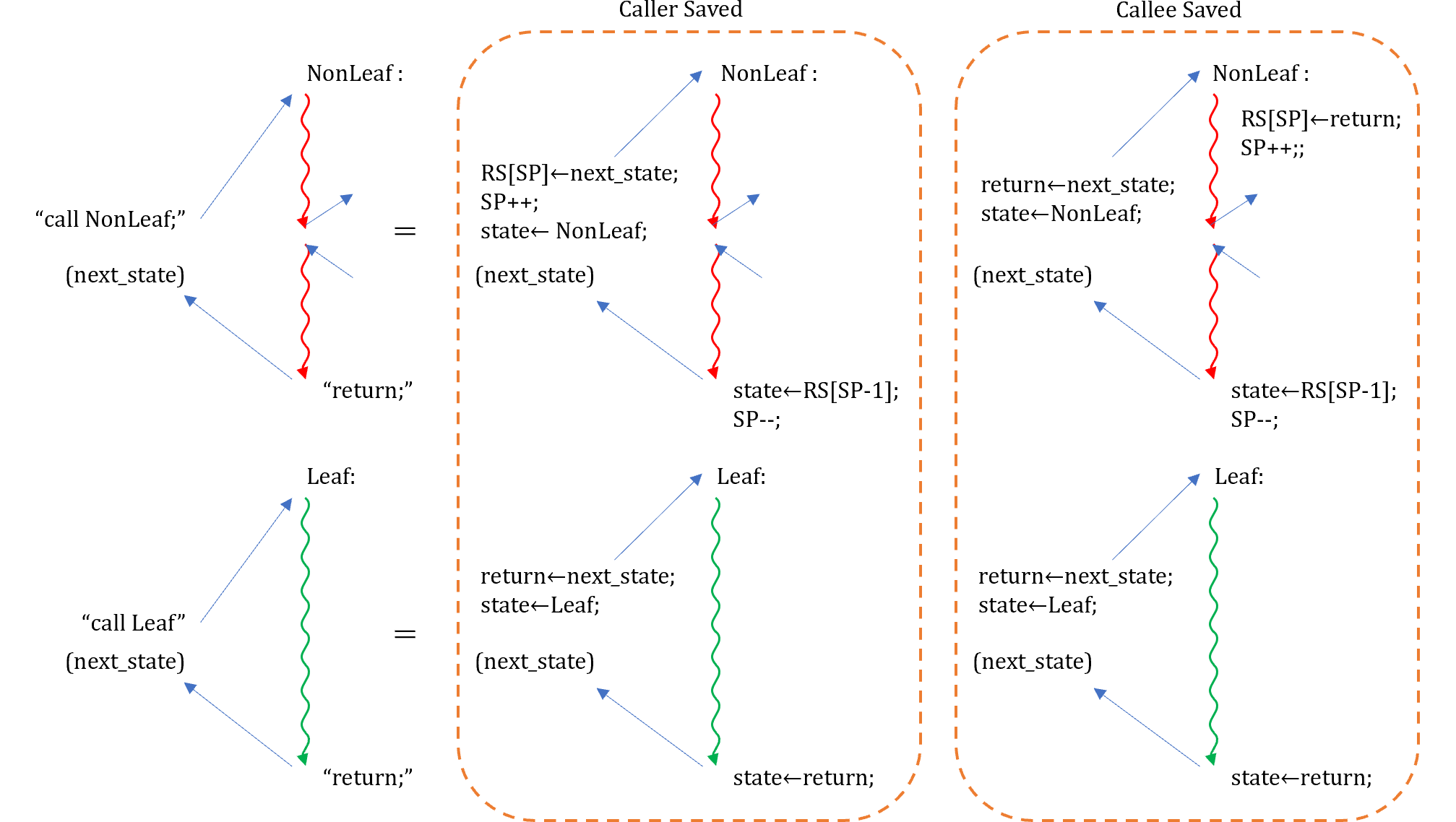
mkConnection
BSVにはmkConnectionという機能があり、インターフェースの接続を効率的に行えます。
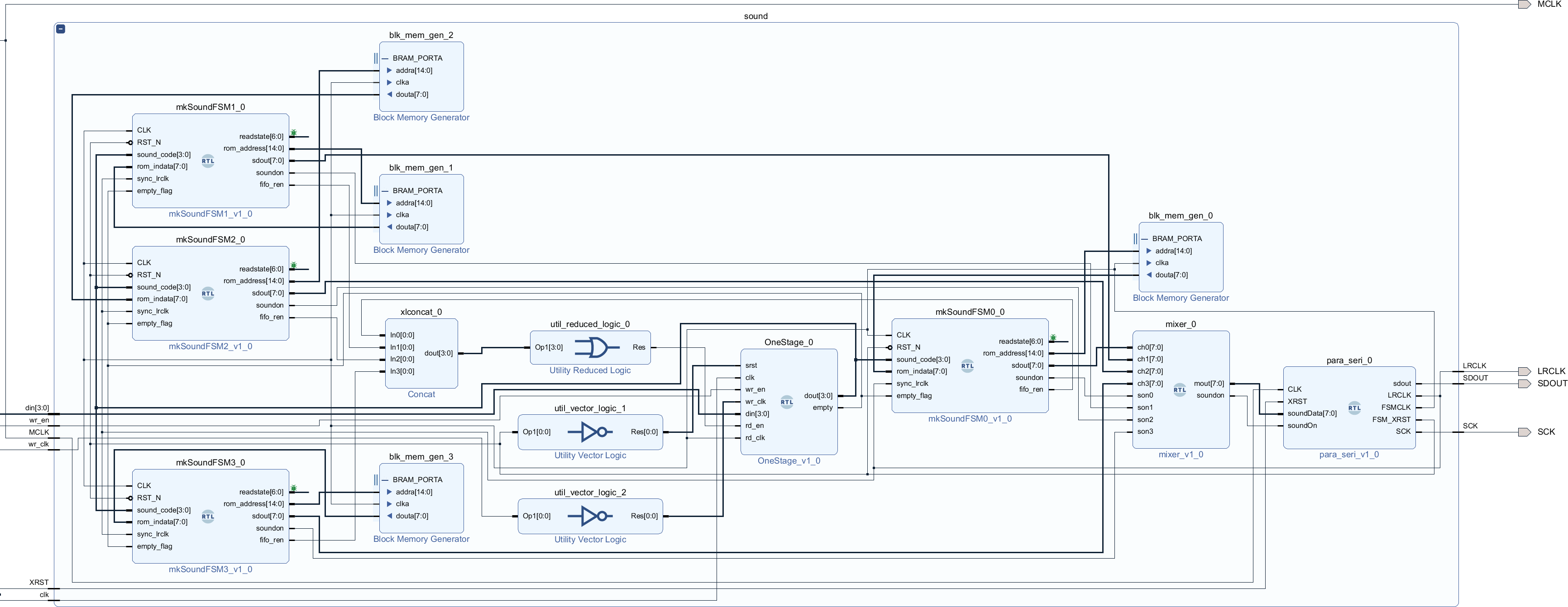
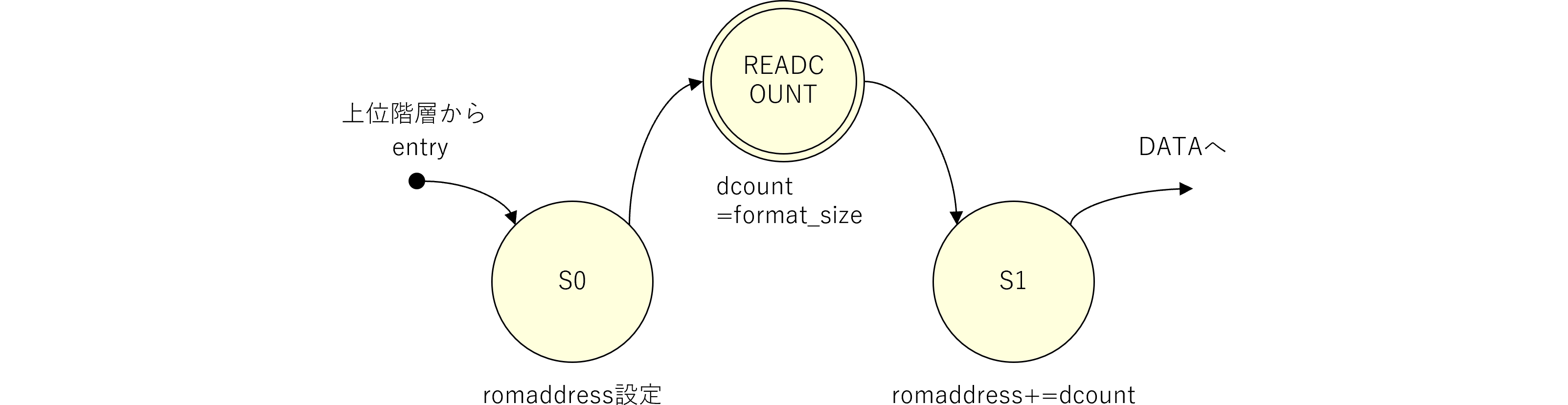
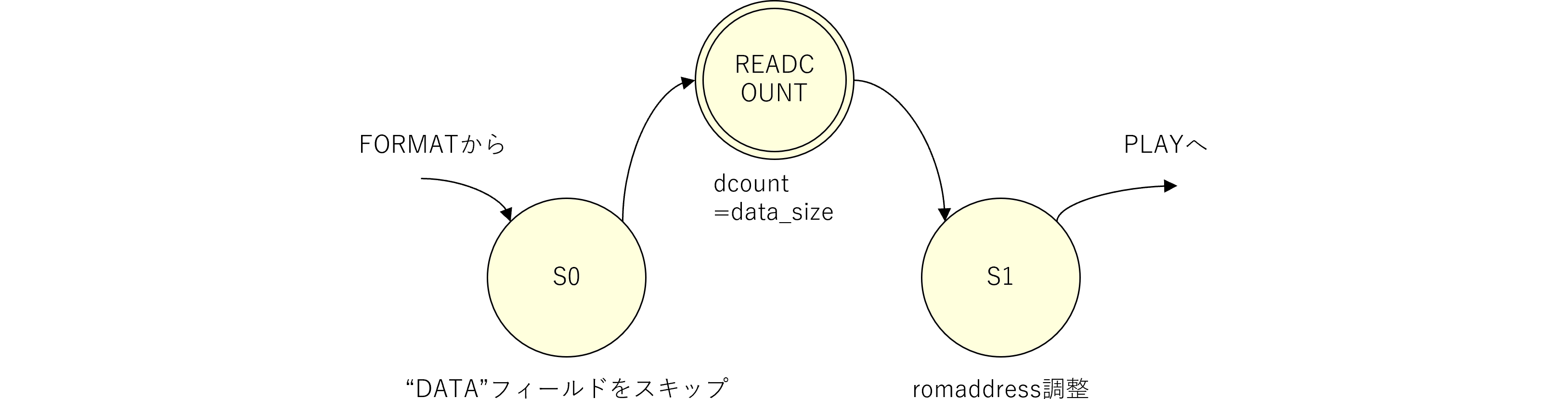
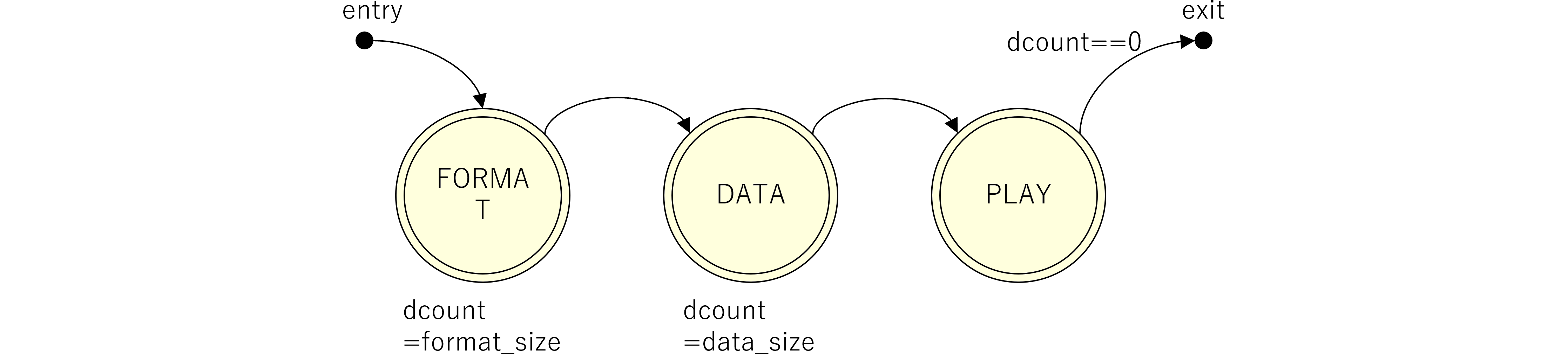
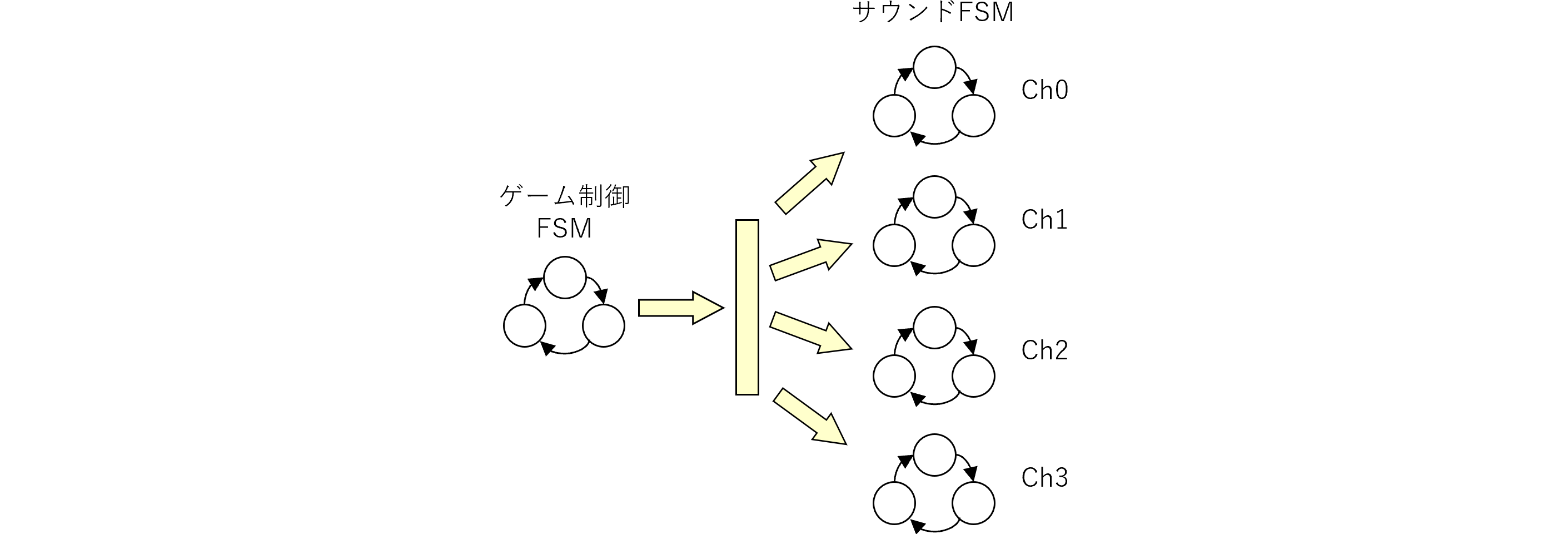
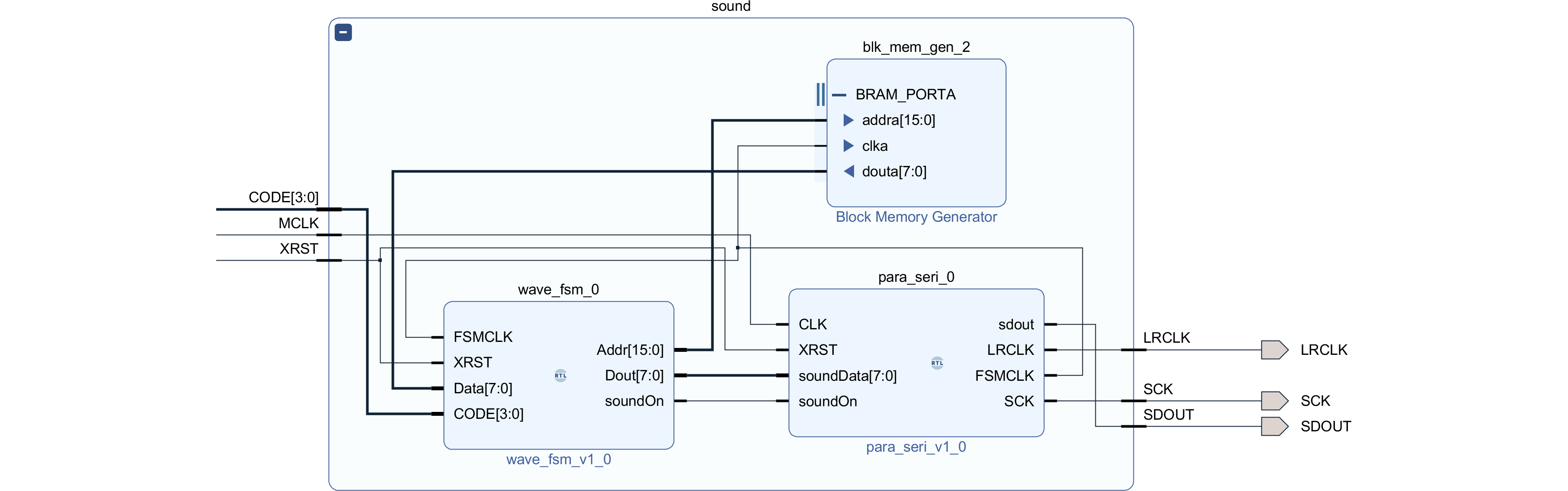
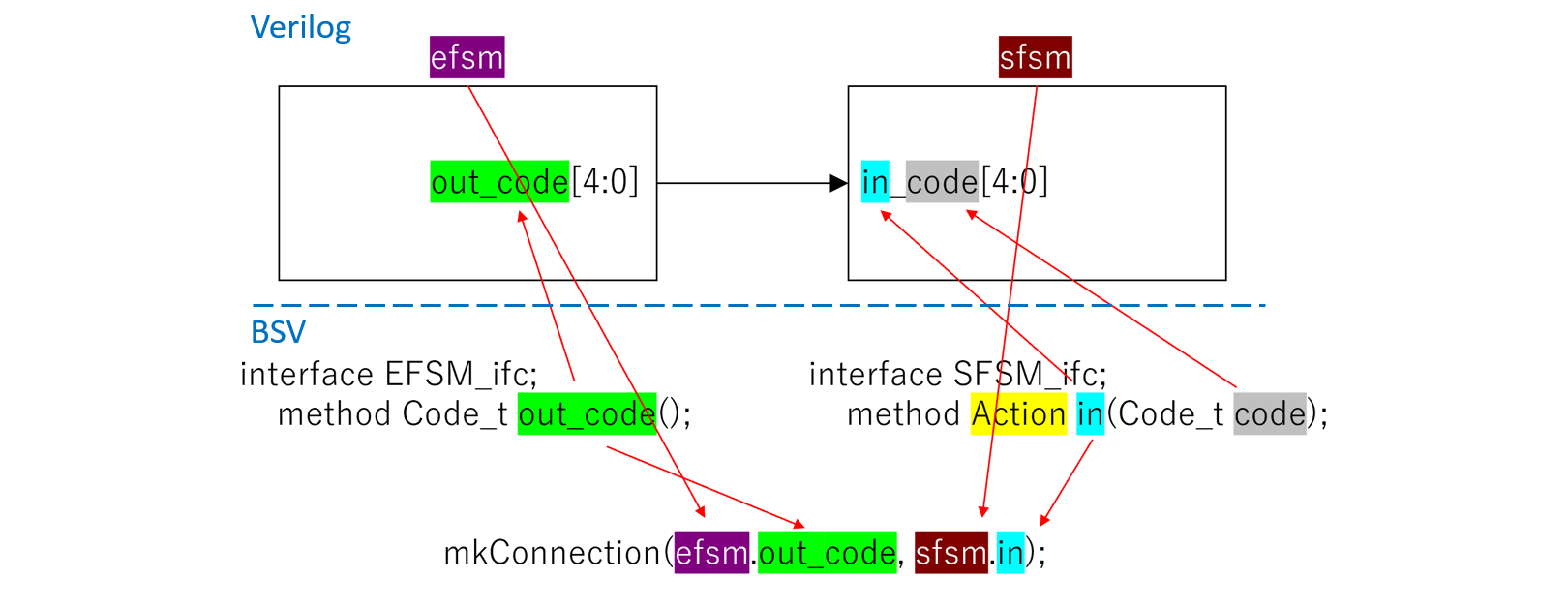 図240.1 Vivado sound階層ブロック図
図240.1 Vivado sound階層ブロック図
図240.1にmkConnectionによる信号の接続及び、BSVで言うメソッドとVerilogで言う信号端子の関係を示します。
Verilogで表すと、モジュールefsmの端子out_code[4:0]から出力した信号code[4:0]が、モジュールsfsmの端子in_code[4:0]に接続されるものとします。この接続を実現するのは上位でのmkConnectionメソッドです。
まず、出力側モジュールefsmの読み出しメソッドは、interfaceブロックにおいてout_code()メソッドで記述されます。メソッドのリターンタイプはCode_tです。BSVのメソッド名がそのままVerilogの端子名になります。
interface EFSM_ifc;
method Code_t out_code();
上位での接続のための識別子は、"モジュール名"+"."+"BSVメソッド名(=Verilog端子名)"となります。EFSMモジュールのインスタンス名をefsmとすると、以下のようになります。
efsm.out_code
一方、入力側モジュールsfsmへの書き込みメソッドには副作用があるため、interfaceブロックにおいて、method Actionとします。書き込みとVerilog端子は少々複雑で、Verilog端子名は"BSVメソッド名_入力パラメータ"となります。
interface SFSM_ifc;
method Action in(Code_t code);
上位での接続のための識別子は出力側と同じく、"モジュール名"+"."+"BSVメソッド名"となります。Verilog端子名とは若干異なります。
sfsm.in
ここでは分かりやすさのため、メソッド名をinとしましたが、重なることはできないため、現実的にはinXXXXのように、意味のあるメソッド名を付けることになります。最後に上位での接続を示します。
import Connectable::*;
mkConnection(efsm.out_code, sfsm.in);
inとoutのどちらを先に書いても文法的には問題ありませんが、回路図の記法の通例として左から右に信号の流れを書くため、左側に出力メソッド、右側に入力メソッドを書くルールとします。
Verilog端子名の制御
注意:端子名制御はVerilogのみに影響を与えるため、mkConnection等のBSVの世界では影響を与えません。
defaultのVerilog端子生成ルールはコントロールすることができ、
- 出力側の端子名をOUTPORTとしたい場合は(* result="OUTPORT" *)とインタフェースに記述します。
- 入力側の端子名をINPORTとしたい場合は(* prefix="" *)としてメソッド名を消去し、さらに(* port="INPORT" *)とインタフェースに記述します。
メソッド名は大文字で始まることが許されていないため、任意のポート名を付けるにはこの制御指示子を用います。例えば、出力インタフェース部に
method Bool fifo_ren();
という出力インタフェースがある場合、
(* result="FIFO_REN" *)
method Bool fifo_ren(); // output terminal "fifo_ren" -> "FIFO_REN"
という指示を与えることで、生成されるverilogにはFIFO_RENという端子が生成されます。
// value method fifo_ren
output FIFO_REN;
また、入力インタフェース
method Action rom(Data_t indata);
においては、メソッド名がromでアーギュメントがindataであるため、defaultでは端子名はrom_indataとなります。これに対して、
(* prefix="" *)
method Action rom((* port="INDATA" *) // input terminal "rom_indata" -> "INDATA"
Data_t indata);
という指示を与えることで、生成されるverilogにはINDATAという端子が生成されます。
// action method rom
input [7 : 0] INDATA;
最後にmethod名を生かしたい場合には次のようにします。例えば
method ActionValue#(Bit#(8)) read(); // パラレル出力メソッド
method Action write(Bit#(8) nodata); // パラレル入力メソッド
のようにread及びwriteというパラレル入出力が有った場合、readという出力インタフェースに対して生成されたverilogは以下のようにmethod名がそのまま端子名になります。
// read O 8 reg
// RDY_read O 1
// EN_read I 1
反対にwriteという入力インタフェースに対してはmethod名を消去しなければmethod名と変数名の結合となります。または、上記のようにmethod名を消去すると入力変数名が生きることになります。
そこで、method名を生かすには一度method名を消去して再度method名をポートで定義することで対処します。
(* prefix="" *) // delete write
method Action write((* port="write" *) Bit#(8) nodata); // パラレル入力メソッド
これにより生成されたverilogのコメント部は以下のとおりです。
// write I 8
// RDY_write O 1
// EN_write I 1
 前のブログ
次のブログ
前のブログ
次のブログ