|
12 |
bsvのMakefile作成 (2) |
トラブルシュート
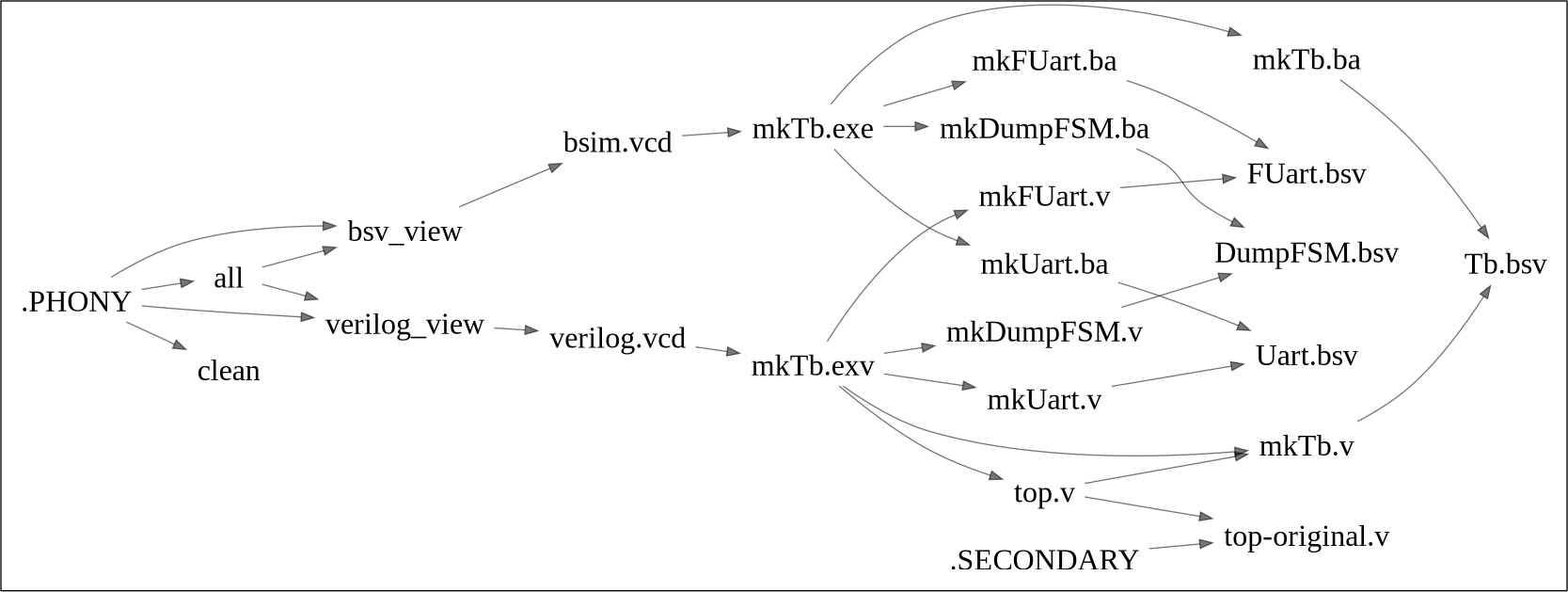
当初、以下のbsvからverilogをコンパイルするというふつうの依存関係が動作せずに苦労しました。
# Verilogファイルの生成
mk%.v: %.bsv
time bsc -verilog -u -steps-warn-interval 1000000 -steps 8000000 -suppress-warnings T0054 $<
そこで以下のコマンドによりデバッグ情報を出力したところ、原因がわかりました。
$ make -rd
原因は、makeがtop-original.vという原始ファイルの元となるtop-original.bsvを探しに行ったためでした。探しに行って無ければ無視すれば問題ないのですが、動作としてはこのルール全体を却下する動作をするため、このルールが無効になっていたものです。ChatGPTと相談して.SECONDARYキーワードでなんとか無視させることができました。
パターンマッチ
さらにC/C++等だと拡張子のみが変化するのですが、bsvではUart.bsvをコンパイルするとmkUart.vとなるなど変則的な変化をするため、それがなかなか表現できませんでしたが、
mk%.v: %.bsv
このように変化しないところを%で記述することで対処できました。
原始ファイルからのファイル名生成法
汎用的に使用できるように、原始ファイル名から中間ファイル名を生成するようにしました。例えば、
$(addprefix mk, $(addsuffix .v, $(basename $(wildcard *.bsv))))
これにより原始ファイルのbsvファイル名からverilogファイル名を自動生成します。このようにすればMakefileに具体的なファイル名を書く必要がありません。誤ってwildcard *.v等としてしまうと、make cleanを行った後には何もないためmake処理が正しく行えないので、全部を集めるリンクのような場合は必ず存在するファイルに基づき必要なファイル名を生成します。一方、一対一の場合は%.v: %.bsvのような記法で十分です。
top.vの役割
忘れがちですが、top.vは直下の端子とemacsのマクロにより自動結線するため、テストベンチのverilogであるmkTb.vが必要です。そのため、Makefileにはその依存関係も加えました。
そもそもtop.vはverilog.vcdを出力するためのものです。
$ bsc -verilog -e mkTb -o mkTb.exv
一方、このようにbsimシミュレーションと同様、フラグを-verilogに変えるだけでiverilogを使わずとも*.vファイルをリンクし、実行ファイルまで生成されます。ではなぜtop.vを使ったかというと、verilog.vcdをダンプするためで、mkTb.exvを実行するだけではvcdが出力されなかったからです。
ところが、
$ ./mkTb.exv +bscvcd=verilog.vcd
このフラグ設定によりvcdが出力できることがわかりました。これによってtop.v等は不要となります。従ってemacsで結線する手段やiverilogが不要となるため、Makefileもだいぶ簡潔になります。