|
15 |
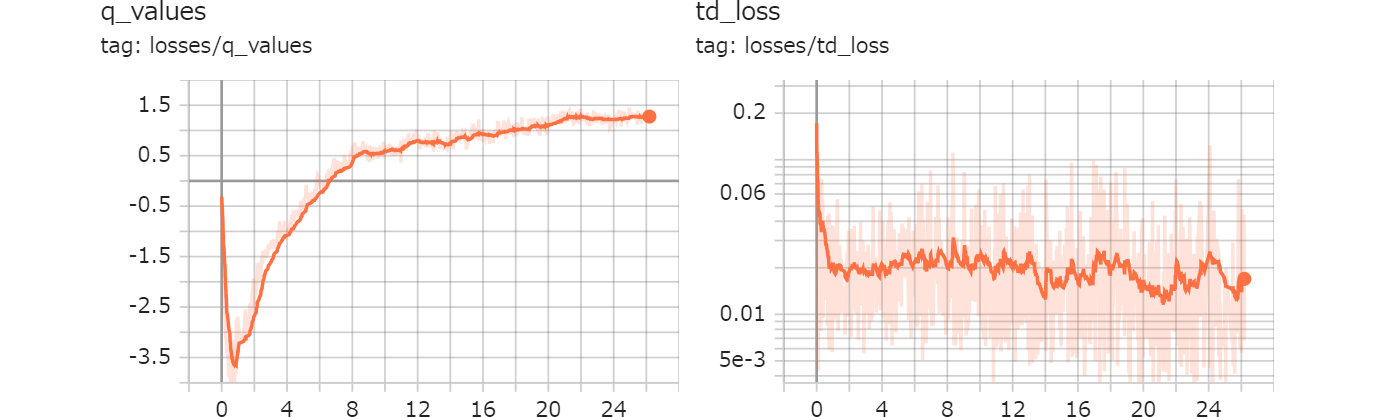
Pongと強化学習 (74) |
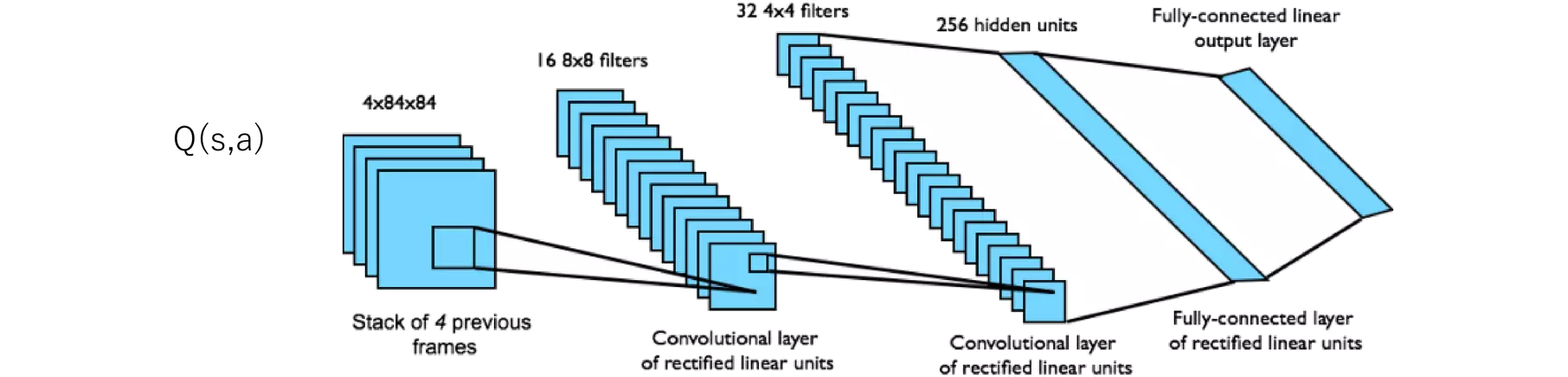
nn.Conv2d(4, 32, 8, stride=4)において、各引数の意味を聞いてみます。
nn.Conv2dはPyTorchで2次元畳み込み層を定義するためのクラスです。このクラスのコンストラクタは複数の引数を受け取りますが、nn.Conv2d(4, 32, 8, stride=4)における各引数の意味は以下の通りです:
in_channels (4): 入力チャネルの数です。この場合、4は入力画像が4つのチャネルを持つことを意味します。強化学習において、これは通常、直近の4フレームをスタックしたものを表し、動きなどの時間的な情報を捉えるために使用されます。
out_channels (32): 出力チャネルの数、または畳み込みによって生成される特徴マップの数です。この場合、32はこの畳み込み層が32枚の特徴マップを生成することを意味します。各特徴マップは異なるフィルター(カーネル)によって得られる画像の特徴を捉えます。
kernel_size (8): カーネル(フィルター)のサイズです。この場合、8x8ピクセルのカーネルサイズを示します。カーネルは入力画像を走査し、局所的な特徴を抽出します。
stride (4): ストライドのサイズです。ストライドはカーネルが入力画像上を移動する際のステップサイズを指し、この場合、カーネルは水平方向および垂直方向に4ピクセルずつ移動します。ストライドが大きいほど、畳み込み後の特徴マップのサイズは小さくなり、計算量を削減できますが、画像の情報損失も大きくなります。
nn.Conv2dのこれらの引数を適切に設定することで、畳み込み層が入力画像から特徴を抽出する方法を制御します。畳み込み層は、画像認識タスクにおいて重要な役割を果たし、画像の局所的なパターンやテクスチャを捉えることができます。