開発環境のインストール
開発環境のインストールを行います。最初にct-ngをインストールしようとしたのですが、RV32ではうまく行きませんでした。そこで、この記事を参考にインストールを実施しました。make中にインストールもしているので、あらかじめ/opt/riscvを作成しておき、記事中にもあるように自分が書き込み可能にしておくのが良さそうです。
qemuについてもこの記事のとおりにインストールしますが、
ERROR: glib-2.48 gthread-2.0 is required to compile QEMU
このようなエラーが出ました。私はFedora32を使用しているので、
$ sudo dnf install glib2 glib2-devel pixman-devel
と不足しているパッケージを追加したところ、configureが通ったので、makeします。
テストプログラム実行
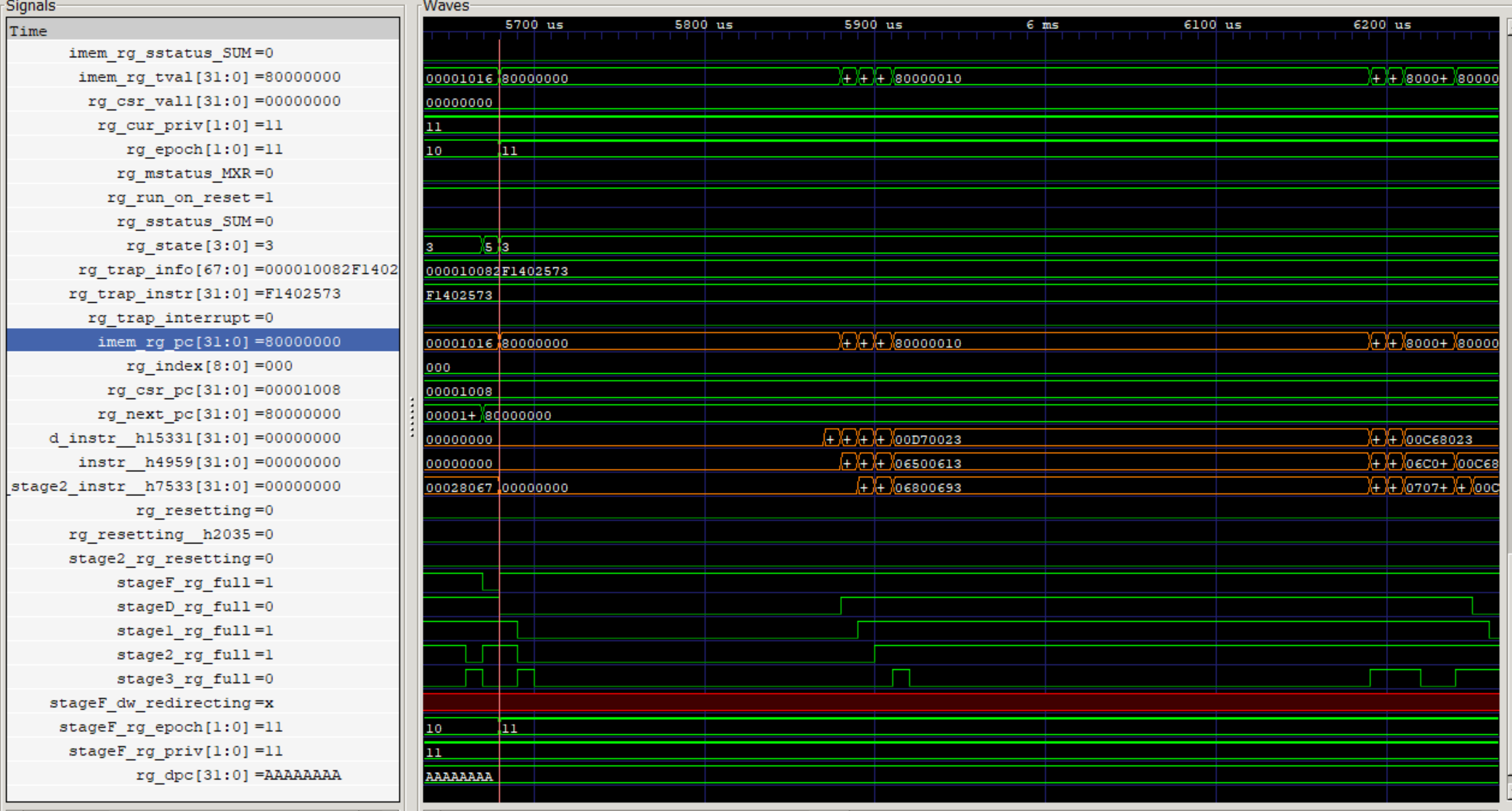
早速、テストプログラムhello.cをコンパイルして実行してみます。Qemuを前提とするプログラムで、QemuのUartとシミュレーション停止アドレスが定義されています。
volatile char* UART0_ADDR = (char*)0x10000000;
volatile short* VIRT_TEST_ADDR = (short*)0x100000;
void _start(void) __attribute__((section(".text.startup")));
void _start(void) {
*UART0_ADDR = 'h';
*UART0_ADDR = 'e';
*UART0_ADDR = 'l';
*UART0_ADDR = 'l';
*UART0_ADDR = 'o';
*UART0_ADDR = '!';
*UART0_ADDR = '\n';
*VIRT_TEST_ADDR = 0x5555;
}
gccによりコンパイルし、qemuによりシミュレーションを行います。
$ riscv32-unknown-elf-gcc -march=rv32i -mabi=ilp32 -nostartfiles -Tlink.lds -Wall -O2 hello.c -o hello.elf
$ qemu-system-riscv32 -nographic -M virt -m 4096 -serial mon:stdio -bios none -kernel hello.elf
hello!
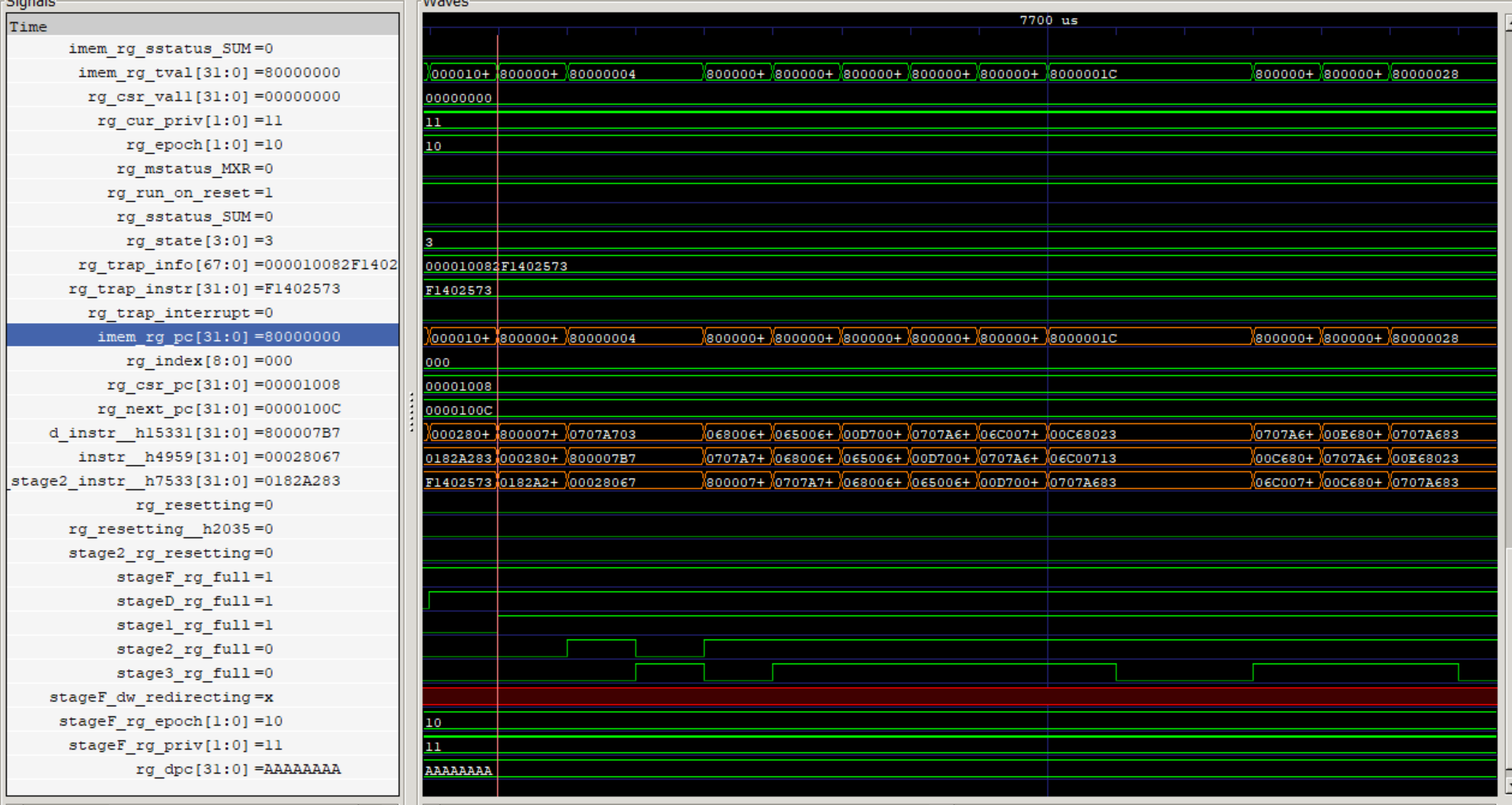
Qemuによりシミュレーションができました。また、逆アセンブラはobjdumpであり、以下の方法でアセンブルリストが確認できます。
$ riscv32-unknown-elf-objdump -D hello.elf
hello.elf: ファイル形式 elf32-littleriscv
セクション .text.startup の逆アセンブル:
80000000 <_start>:
80000000: 800007b7 lui a5,0x80000
80000004: 0707a703 lw a4,112(a5) # 80000070 <sp_top+0xffffbff8>
80000008: 06800693 li a3,104
8000000c: 06500613 li a2,101
80000010: 00d70023 sb a3,0(a4)
80000014: 06c7a683 lw a3,108(a5)
80000018: 06c00713 li a4,108
8000001c: 00c68023 sb a2,0(a3)
80000020: 06c7a683 lw a3,108(a5)
80000024: 00e68023 sb a4,0(a3)
:
 前のブログ
次のブログ
前のブログ
次のブログ