|
11 |
bsvのMakefile作成 |
Makefile
ChatGPTの助けを借りながらbsvのMakefileを作成しました。bsvソースはBSVの問題点?を作成したときのファイルです。完成したMakefileを示します。
# ファイル名の生成
BSRCS = $(wildcard *.bsv) # BSVソースファイル
BASRCS = $(addprefix mk, $(addsuffix .ba, $(basename $(BSRCS)))) # BA中間ファイル
VSRCS = $(addprefix mk, $(addsuffix .v, $(basename $(BSRCS)))) # Verilogファイル
# .PHONY ターゲットの定義
.PHONY: all bsv_view verilog_view clean
# 全体のターゲット定義
all: bsv_view verilog_view
# BSV波形ビューアの起動
bsv_view: bsim.vcd
gtkwave -A bsim.vcd
# BSV波形ファイルの生成
bsim.vcd: mkTb.exe
./mkTb.exe -V bsim.vcd
# BSV実行ファイルの生成
mkTb.exe: $(BASRCS)
bsc -sim -e mkTb -parallel-sim-link 4 -o mkTb.exe
# BSVファイルのコンパイル
mk%.ba: %.bsv
time bsc -sim -u -steps-warn-interval 1000000 -steps 8000000 -suppress-warnings T0054 $<
# Verilog波形ビューアの起動
verilog_view: verilog.vcd
gtkwave -A verilog.vcd
# Verilog波形ファイルの生成
verilog.vcd: mkTb.exv
./mkTb.exv -V verilog.vcd
# Verilog実行ファイルの生成
mkTb.exv: top.v $(VSRCS)
iverilog -y /usr/local/lib/Verilog/ top.v $(VSRCS) -o mkTb.exv
# top.vの生成と更新
top.v: top-original.v mkTb.v
cp top-original.v top.v
chmod 644 top.v
emacs --batch top.v -f verilog-batch-auto
# BSVファイルからVerilogファイルを生成
mk%.v: %.bsv
time bsc -verilog -u -steps-warn-interval 1000000 -steps 8000000 -suppress-warnings T0054 $<
# クリーンアップ
clean:
@rm -f mk*.v top.v
@rm -f *.bi *.bo *.ba a.out \#*
@rm -f *.cxx *.h *.o *.so *.bexe
@rm -f *.exe *.exv
@rm -f *.vcd *~ *.fsdb *.log
# 中間ファイルを保持するための設定
.SECONDARY: top-original.v
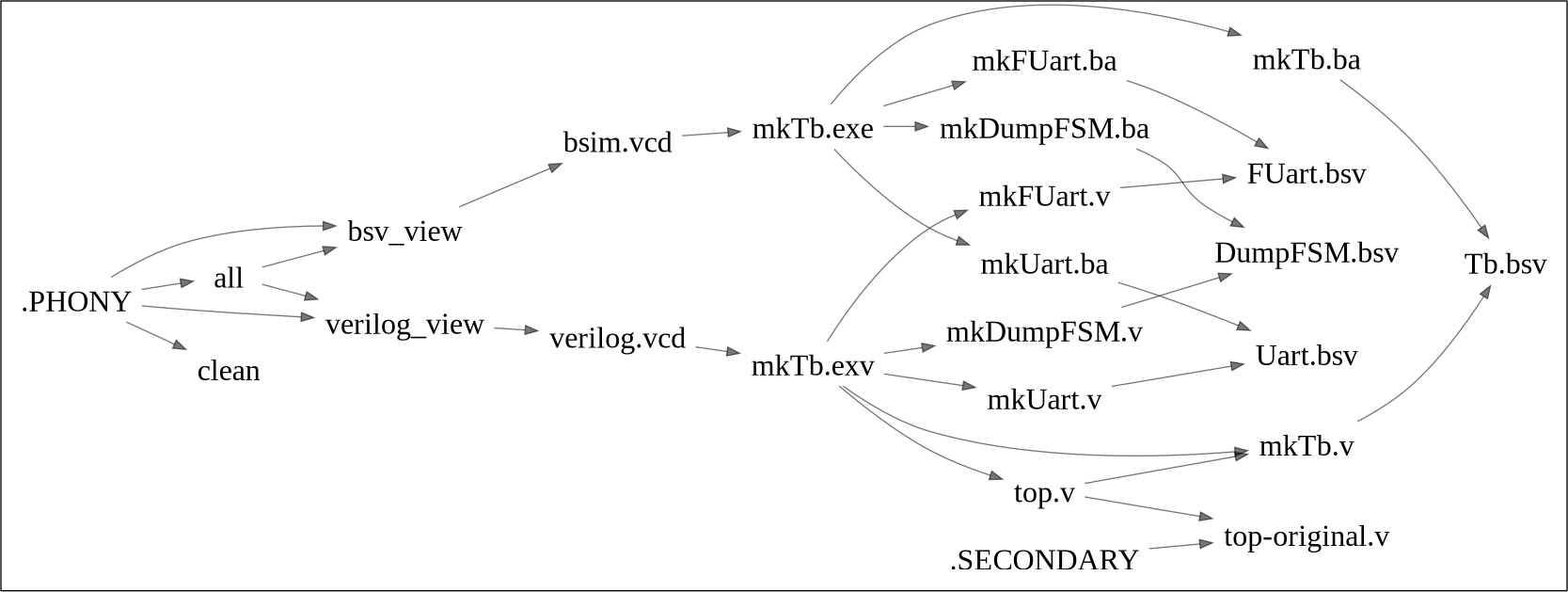
依存関係グラフ
ここで、’Makefile'の依存関係の可視化の記事のプログラムをそのまま用いて、
$ LANG=C make -np | python3 make_p_to_json.py > graph.json; python json_to_dot.py workflow.png; xv workflow.png
このコマンドにより作成した依存関係図を図814.1に示します。