|
27 |
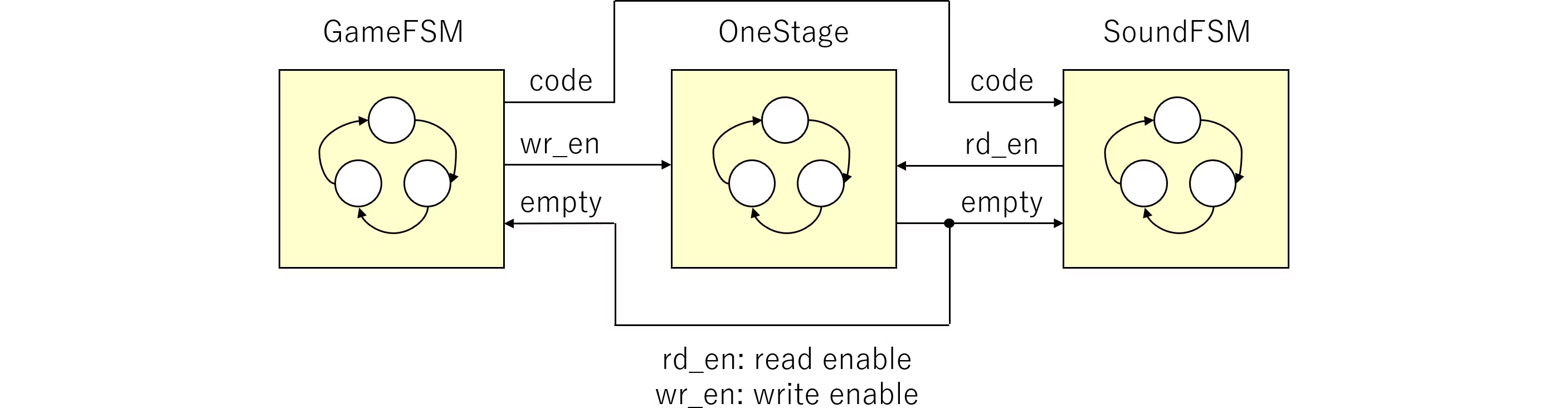
BSVにおけるコマンドバッファ制御 (8) |
5. Bsimシミュレーション
次にbsimシミュレーションを実行します。
$ make bsim
bsc -sim -bdir bsim -u -g mkTopDirect TopDirect.bsv
checking package dependencies
All packages are up to date.
cd bsim && \
bsc -sim -bdir . -e mkTopDirect -o ../mkTopDirect.exe
/home/sakurai/src/bsv/testFSM/bsim
Warning: Command line: (S0073)
Duplicate directories were found in the path specified with the -p flag.
Only the first occurrence will be used. The duplicates are:
/home/sakurai/src/bsv/testFSM/bsim
Note that when the -bdir flag is used, that directory is automatically added
to the head of the path.
Bluesim object reused: mkTopDirect.{h,o}
Bluesim object created: model_mkTopDirect.{h,o}
Simulation shared library created: ../mkTopDirect.exe.so
Simulation executable created: ../mkTopDirect.exe
./mkTopDirect.exe -V bsim.vcd
10: consume = 1
10: produce = 1
210: consume = d
210: produce = d
410: consume = e
410: produce = e
610: consume = a
610: produce = a
810: consume = b
810: produce = b
1010: consume = 6
1010: produce = 6
1210: consume = 8
1210: produce = 8
1410: consume = 2
1410: produce = 2
1610: consume = 9
1610: produce = 9
1810: consume = f
1810: produce = f
=== simulation finished ===
シミュレーション波形を確認します。
$ gtkwave -A bsim.vcd

bsimシミュレーションではtop/producer/consumerのモジュール階層は存在せず、最適化が図られています。受け渡しする信号xは内部信号となるため、使用されていなければ削除されてしまいます。ここではcons_Lastvalとしてオレンジ色にて波形が表示されています。