|
26 |
RISC-Vプロセッサの設計 (24) |
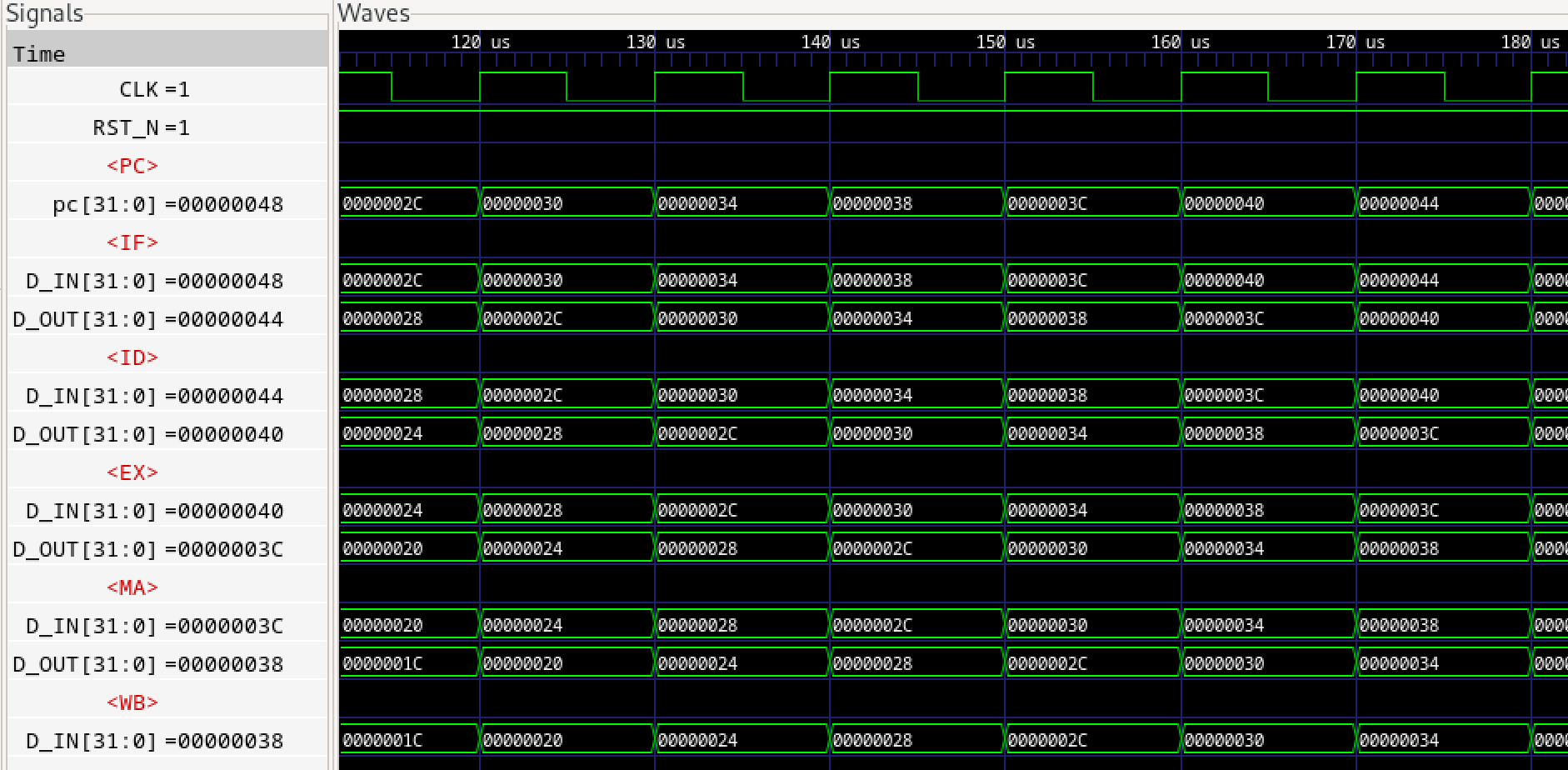
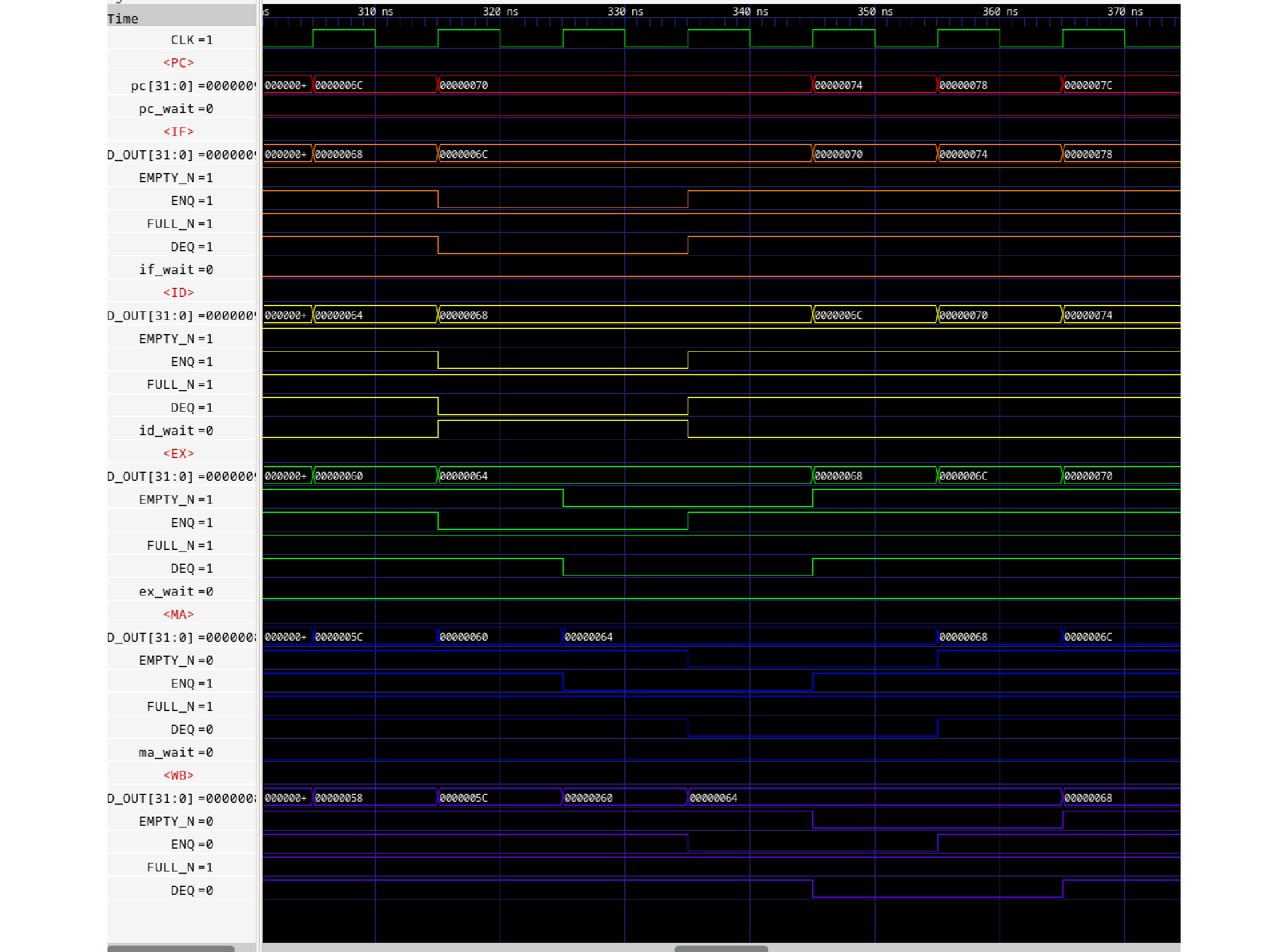
過去記事で設計したPCパイプラインをモジュールに変更し、その上にテストベンチをかぶせます。以下にテストベンチTb.bsv及びPCパイプラインProcessor.bsvのソースを示します。
Tb.bsv
import StmtFSM::*;
import Processor::*;
(* synthesize *)
module mkTb();
Empty proc <- mkProcessor();
Stmt main = seq
delay(30);
$finish;
endseq;
mkAutoFSM(main);
endmodule
Processor.bsv
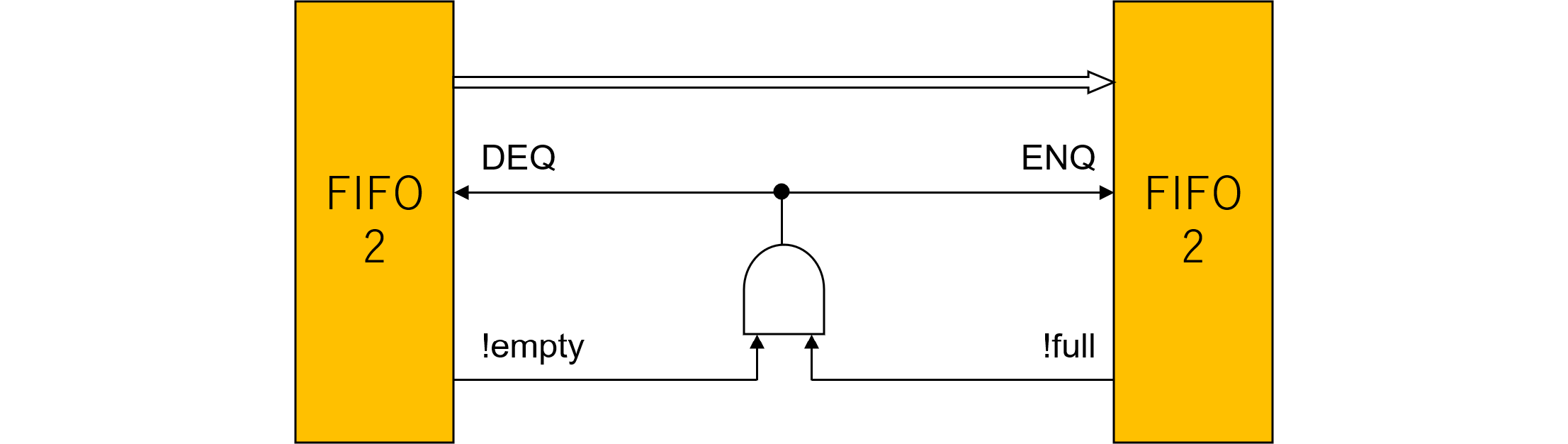
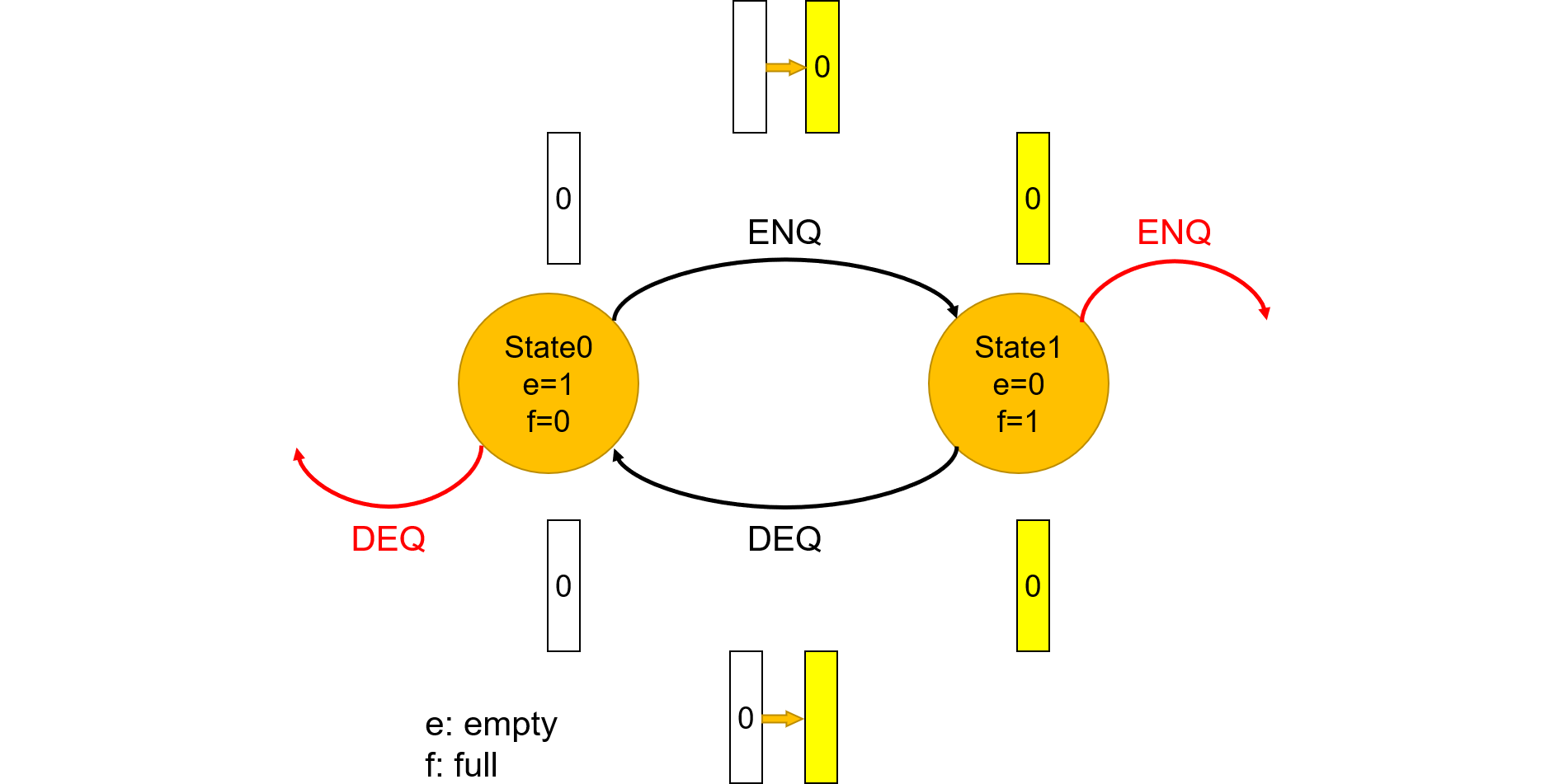
import FIFO::*;
(* synthesize, always_ready *)
module mkProcessor(Empty);
Reg#(int) pc <- mkReg(0);
FIFO#(int) ifs <- mkFIFO;
FIFO#(int) ids <- mkFIFO;
FIFO#(int) exs <- mkFIFO;
FIFO#(int) mas <- mkFIFO;
FIFO#(int) wbs <- mkFIFO;
// <PC>
rule pc_stage;
if (pc > 100) $finish(0);
$display("------");
ifs.enq(pc);
pc <= pc + 4;
endrule
// <IF>
rule if_stage;
let pc_if = ifs.first;
ifs.deq;
$display (" pc_if = %04h", pc_if);
ids.enq (pc_if);
endrule
// <ID>
rule id_stage;
let pc_id = ids.first;
ids.deq;
$display (" pc_id = %04h", pc_id);
exs.enq (pc_id);
endrule
// <EX>
rule ex_stage;
let pc_ex = exs.first;
exs.deq;
$display (" pc_ex = %04h", pc_ex);
mas.enq (pc_ex);
endrule
// <MA>
rule ma_stage;
let pc_ma = mas.first;
mas.deq;
$display (" pc_ma = %04h", pc_ma);
wbs.enq (pc_ma);
endrule
// <WB>
rule wb_stage;
let pc_wb = wbs.first;
wbs.deq;
$display (" pc_wb = %04h", pc_wb);
endrule
endmodule: mkProcesso
コンパイルと起動コマンドは以下のとおりです。gtkwaveはここ。
$ bsc -u -sim Tb.bsv; bsc -sim -e mkTb -o mkTb.exe;
$ ./mkTb.exe -V;
$ gtkwave -A dump.vcd