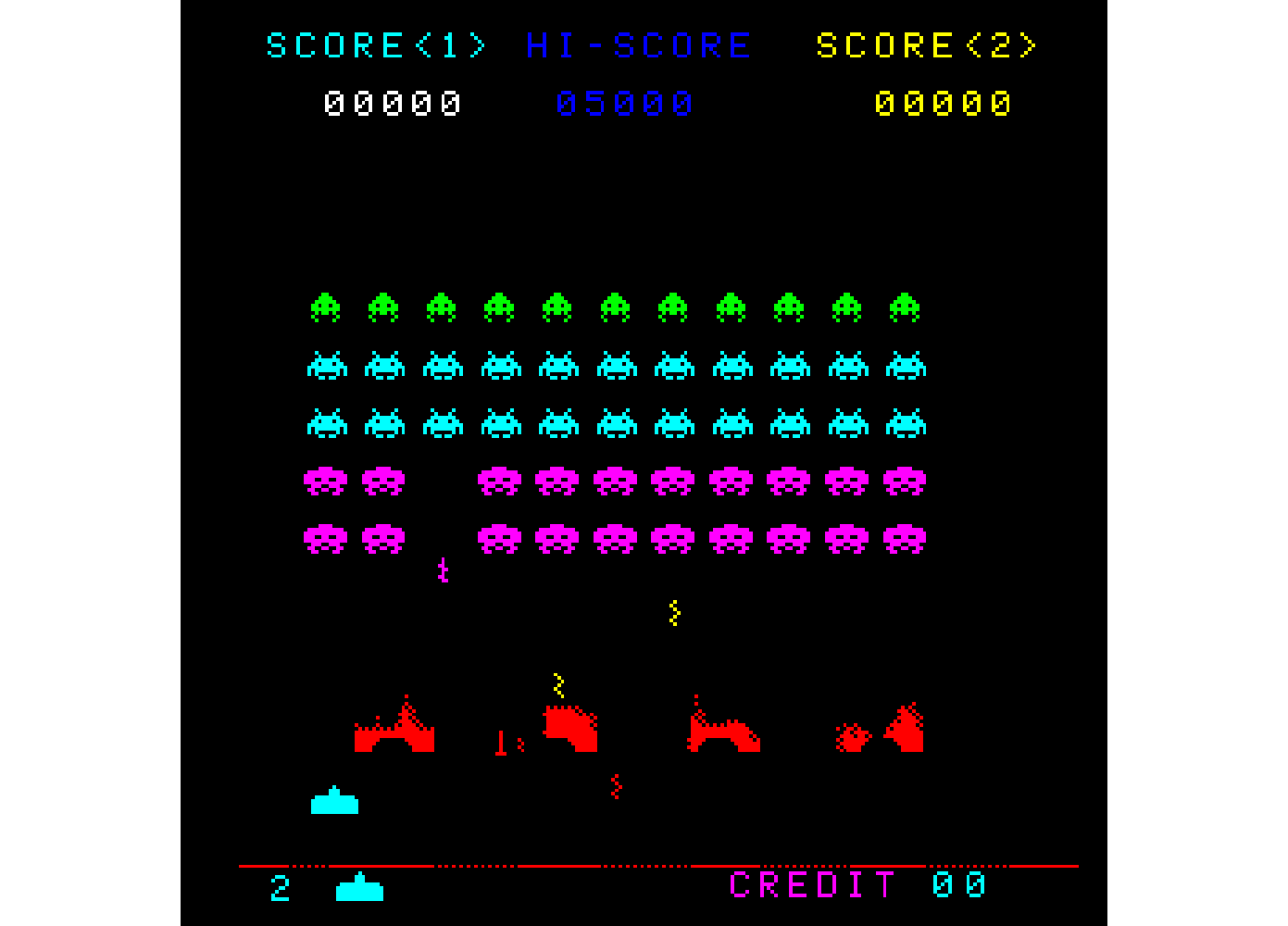
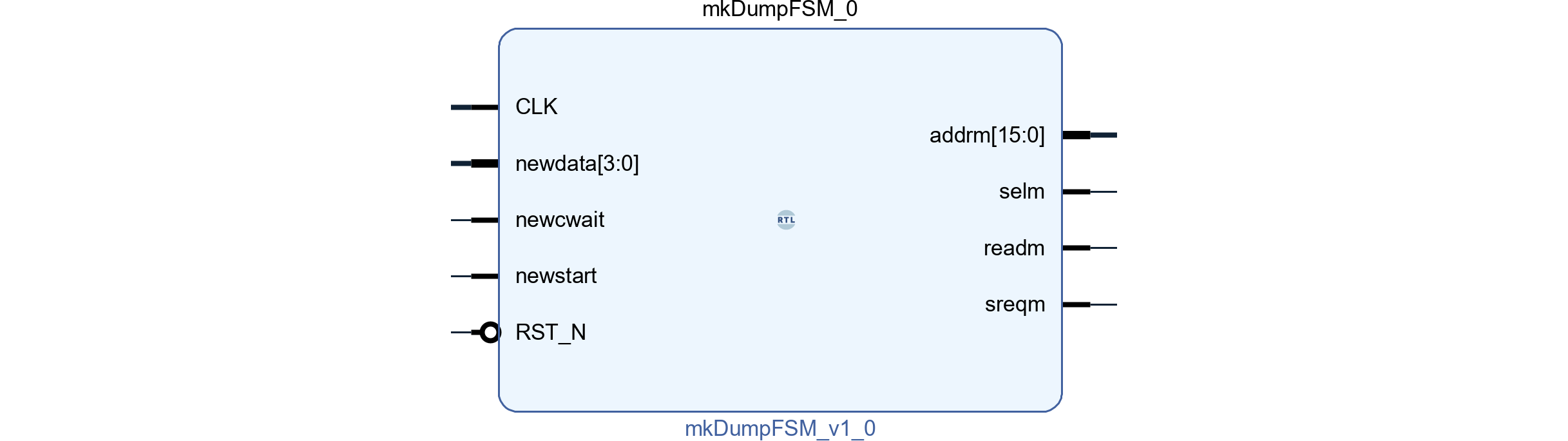
インベーダの歩行音
インベーダの歩行音は、現在は隊列に同期して出力されます。インベーダ一匹の歩行処理は60Hzで実施されるため、初期状態では55/60secに一度、最後の一匹では1/60secに一度歩行音が出力されます。
最後の一匹の時に、どうも歩行音が速すぎると思っていたら、過去記事のとおり、インベーダの数に応じた間隔で歩行音が出力され、必ずしも隊列の動作とは同期していないことが判明しました。アニメーションは、インベーダーの数に比例して徐々に速くなるのに比べ、サウンドは段階的に速くなるのは、どのような意図があるのでしょうか?
なるべくオリジナルに近づけるという方針から、今回はこれを実装します。
歩行音間隔タイマの実装
まず、過去記事の表を実装します。タイマ初期値の最大値は52なので6bitのレジスタが55個必要です。1から55までを使用しており、0を含めた56個を定義しています。
UInt#(6) inv_init_stimer[56] = {5, 5, 7, 9,11,12,13,14,16,16,19,19,19,21,21,21,21,24,24,24,
24,24,28,28,28,28,28,28,34,34,34,34,34,34,34,34,39,39,39,39,
39,39,39,46,46,46,46,46,46,46,52,52,52,52,52,52};
過去記事の歩行音間隔タイマの仕様に示すように、これはタイムアウトした際に、インベーダ数に応じた値でタイマを初期化するための表です。次に、歩行音間隔タイマ本体を実装します。
Reg#(UInt#(6)) inv_stimer <- mkRegU;
次に、サウンドパターンは4から7を繰り返すため、2bitのパターンレジスタを用意します。
Reg#(UInt#(2)) inv_spattern <- mkRegU;
初期化部分です。タイマの初期値は52とします。パターンの初期値は0とします。
inv_stimer <= 52;
inv_spattern <= 0;
隊の先頭で実施していた次のサウンド出力処理を削除します。
// if (inv_ido != END_STATE) seq
// sound(extend(inv_pattern) + 4); // from 4 to 7
// endseq
その代わり、 全てのインベーダについて次の処理を追加します。
// 全てのインベーダについて処理
if (inv_stimer == 0) seq
sound(extend(inv_spattern) + 4); // from 4 to 7
inv_spattern <= inv_spattern + 1;
inv_stimer <= inv_init_stimer[inv_no];
endseq else seq
inv_stimer <= inv_stimer - 1;
endseq
これにより過去記事のような動作を行うはずです。⇒実施したところ、正しく動作したようです。
 前のブログ
次のブログ
前のブログ
次のブログ