|
5 |
Fault treeの自動生成 (25) |
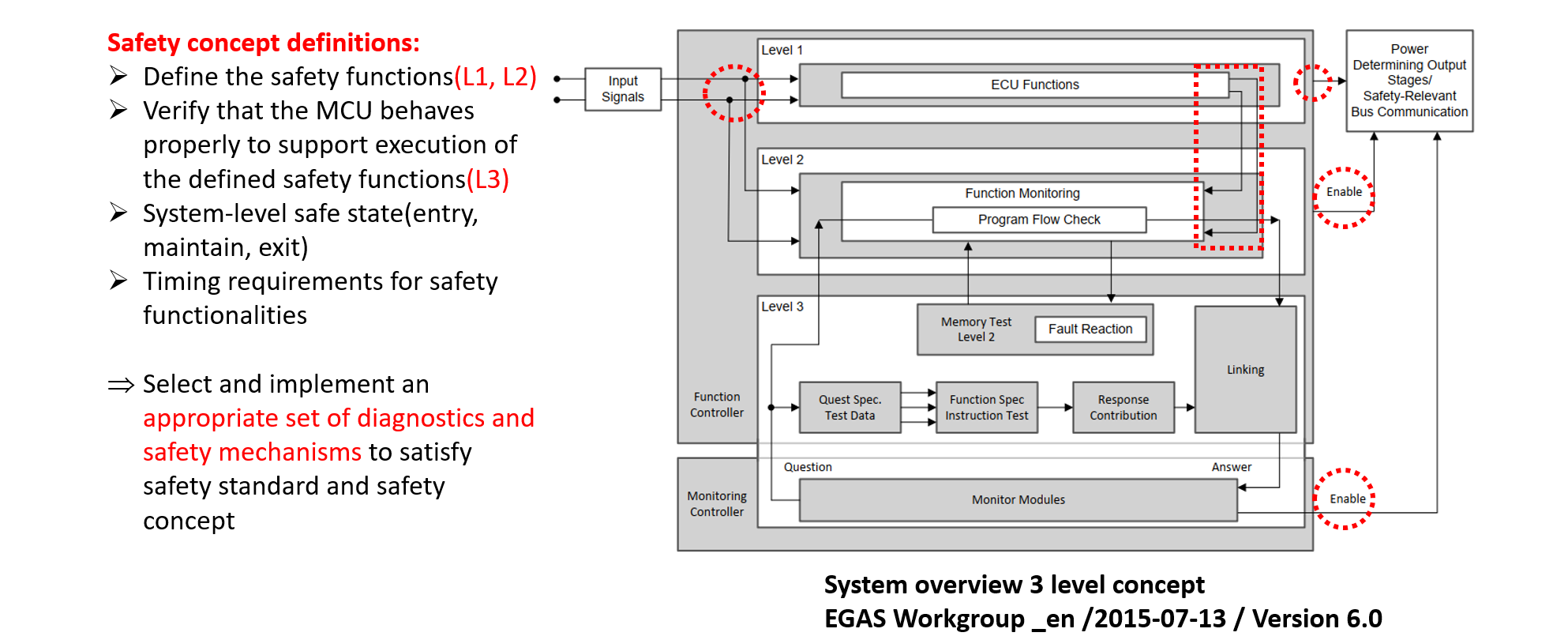
さてMCSを取ることにより、このアーキテクチャの欠点が見えてきました。
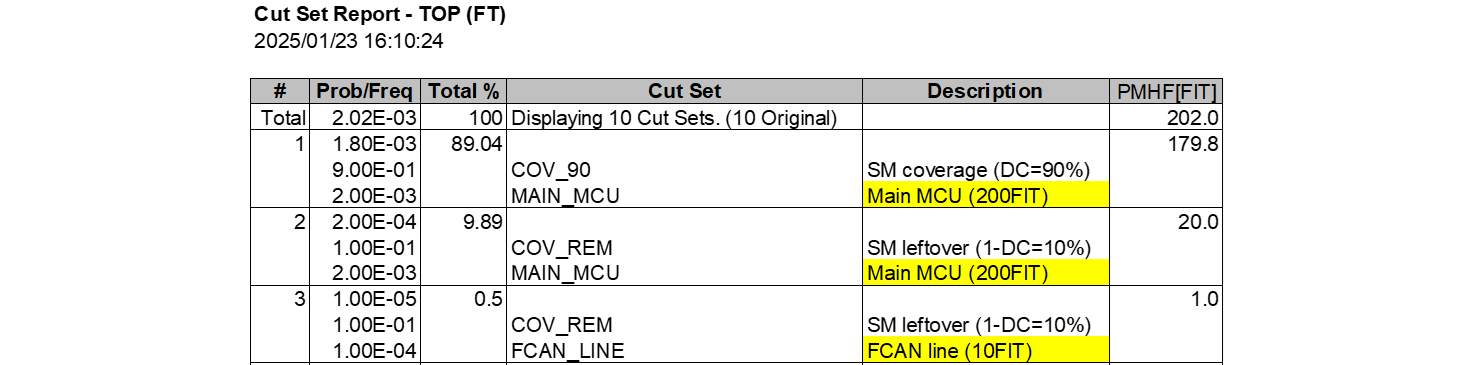
積項No.1とNo.2の論理和を取れば、 $$ \mathtt{MAIN\_MCU}\cdot \mathtt{COV\_90}+\mathtt{MAIN\_MCU}\cdot \mathtt{COV\_REM}\\=\mathtt{MAIN\_MCU}\cdot \mathtt{COV\_90}+\mathtt{MAIN\_MCU}\cdot\overline{\mathtt{COV\_90}}\\=\mathtt{MAIN\_MCU} $$
積項No.1とNo.2の割合を加えれば89.04+9.89=99.29。このように、約99%以上のPMHFがメインマイコンとなっており、その理由は先の通りメインマイコンがIFパスとSMパスに存在するため、単一故障で両方のパス共に故障するためです。
これを避けるため、サブマイコンがメインマイコンの故障を検出したらいきなりリレーをオフするようにパスを変更します。
$$\img[-1.35em]{/images/withinseminar.png}$$
なお、本稿はRAMS 2026に投稿予定のため一部を秘匿していますが、論文公開後の2026年2月頃に開示予定です。