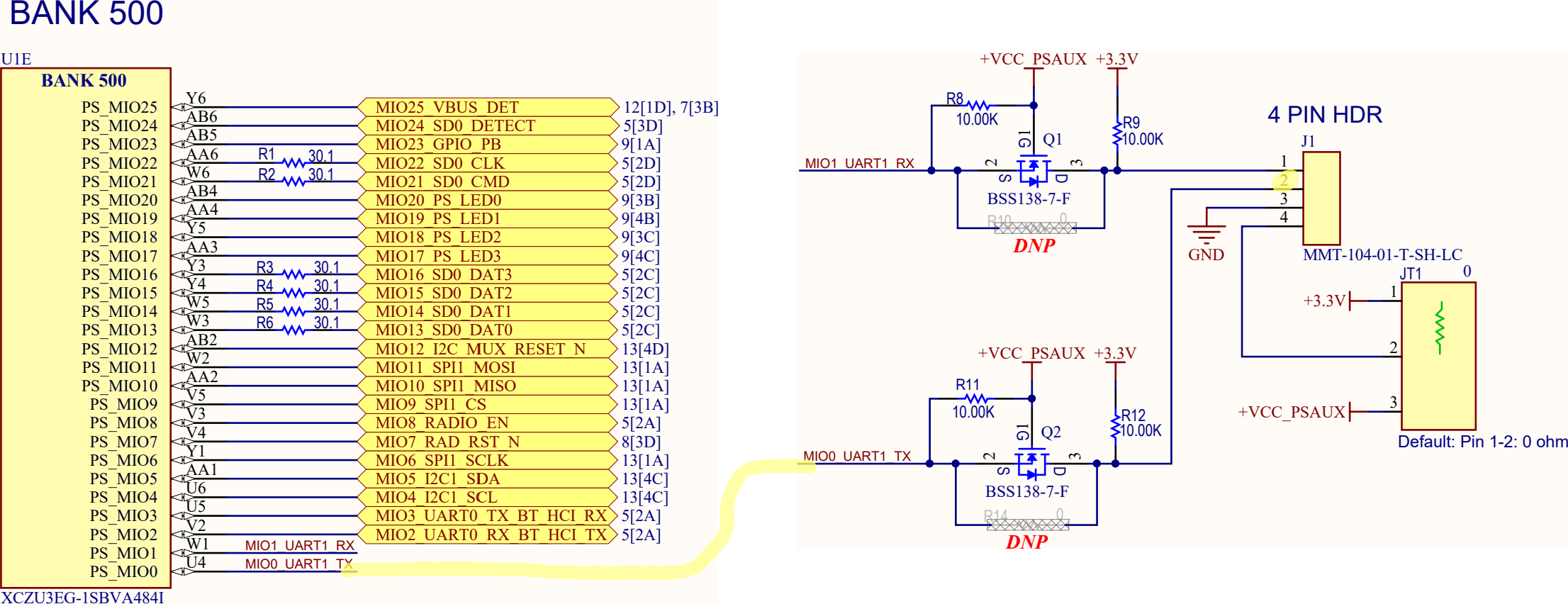
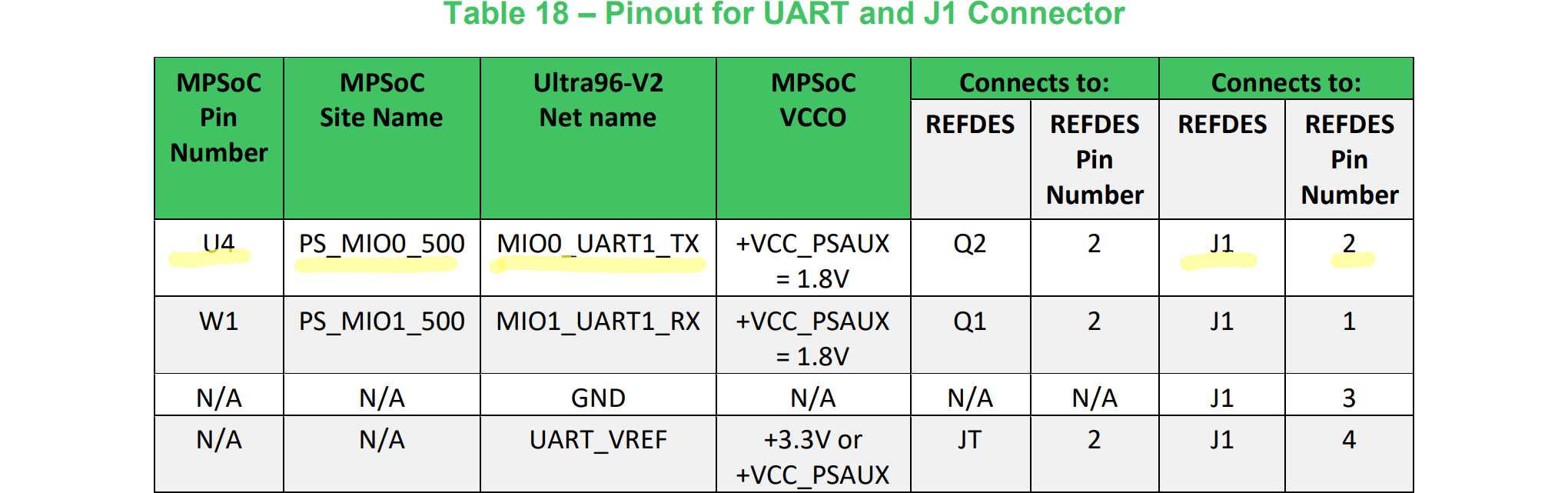
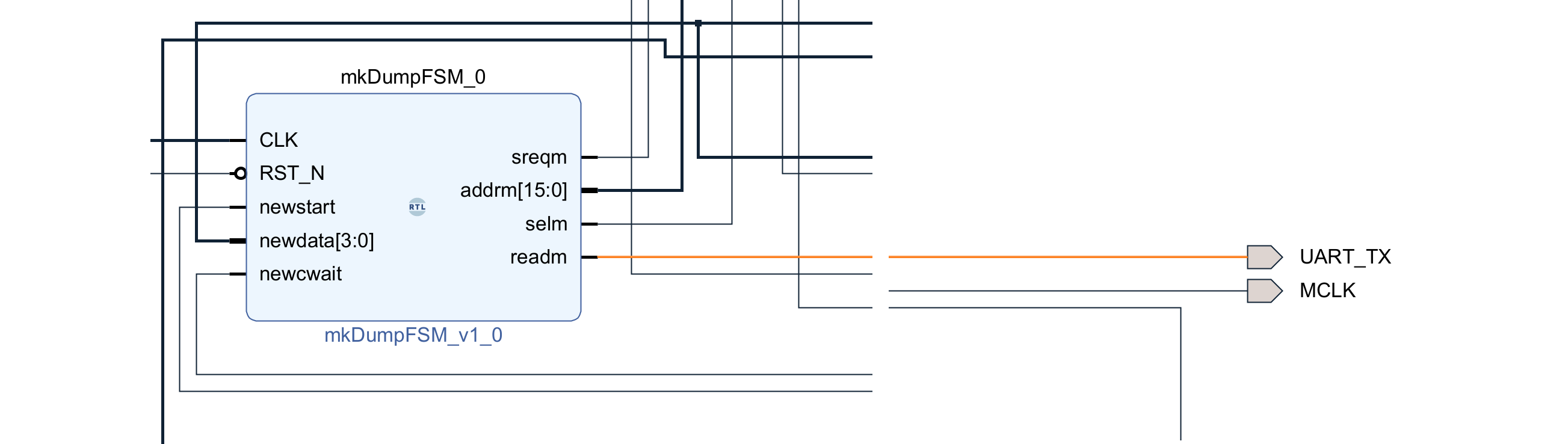
2段FIFOの修正
さらにFIFO2に変えて各ステージにウエイトを入れる修正を行いました。<WB>だけはウエイト要因が無いためウエイト信号はありません。他のステージでも検討の結果無くなる可能性はあります。
- <PC>: pc_wait
- <IF>: if_wait
- <ID>: id_wait
- <EX>: ex_wait
- <MA>: ma_wait
これをシミュレーションした結果、あるステージでウエイトがかかると当然そのステージの上位からENQできなくなるはずですが、FIFOが2段のため、もう1個は受け付けるようになります。これは制御が複雑になるものの性能は向上しないので過去記事で検討したように、あるステージからは上位にウエイトを上げるような接続にします。それぞれのステージ固有のウエイト信号です。
- <PC>: pc_wait
- <IF>: if_wait
- <ID>: id_wait
- <EX>: ex_wait
- <MA>: ma_wait
これらを下記のように上位へ伝える結線を行います。
let mas_wait = ma_wait;
let exs_wait = ex_wait || mas_wait;
let ids_wait = id_wait || exs_wait;
let ifs_wait = if_wait || ids_wait;
let pcs_wait = pc_wait || ifs_wait;
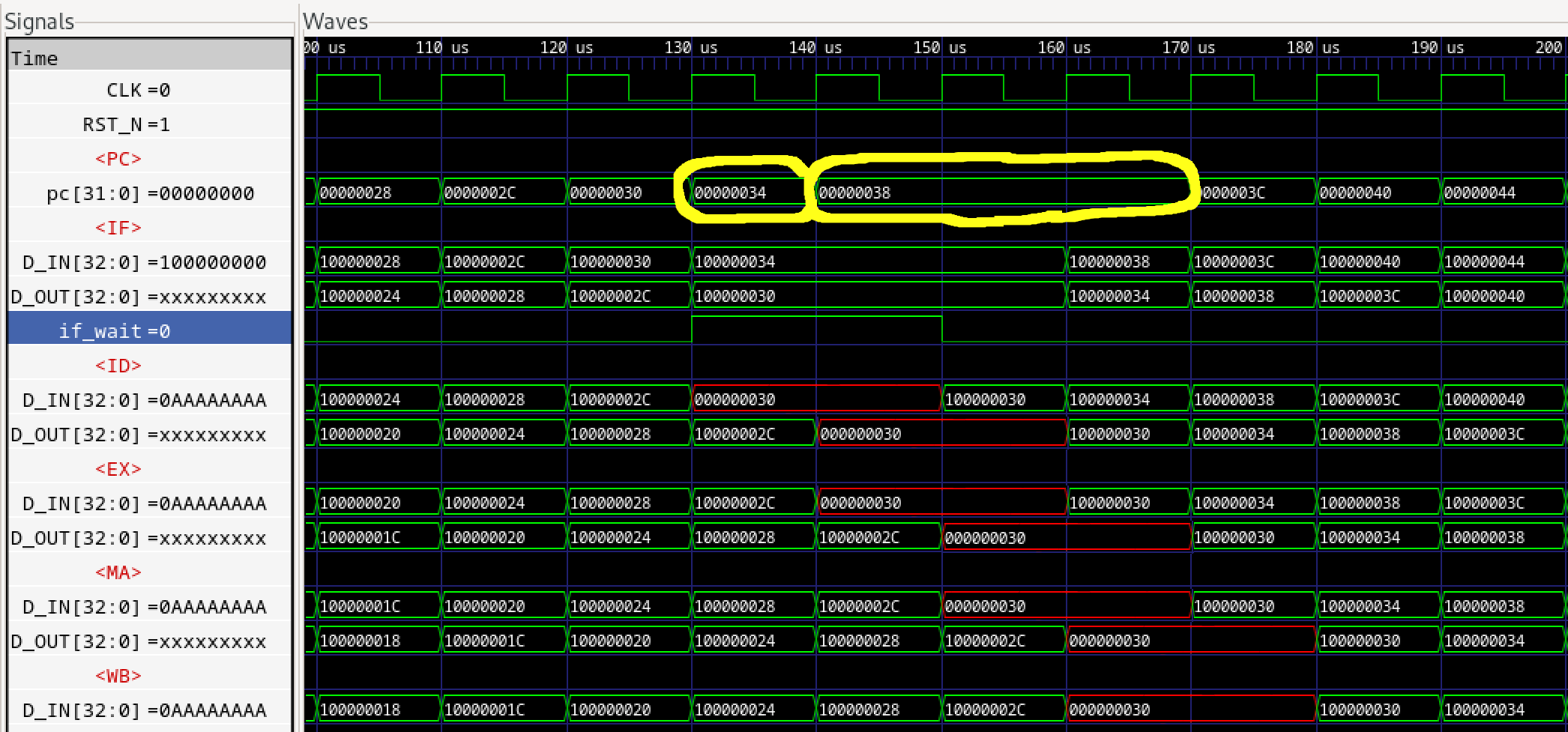
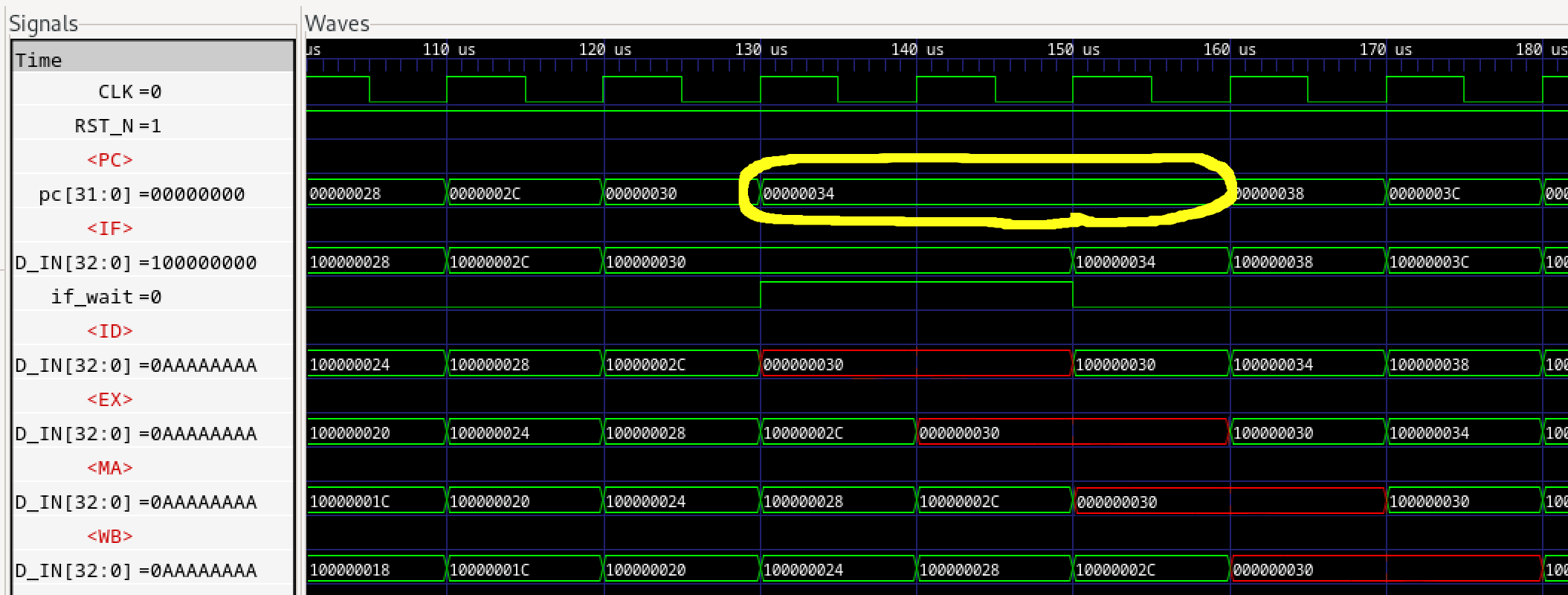
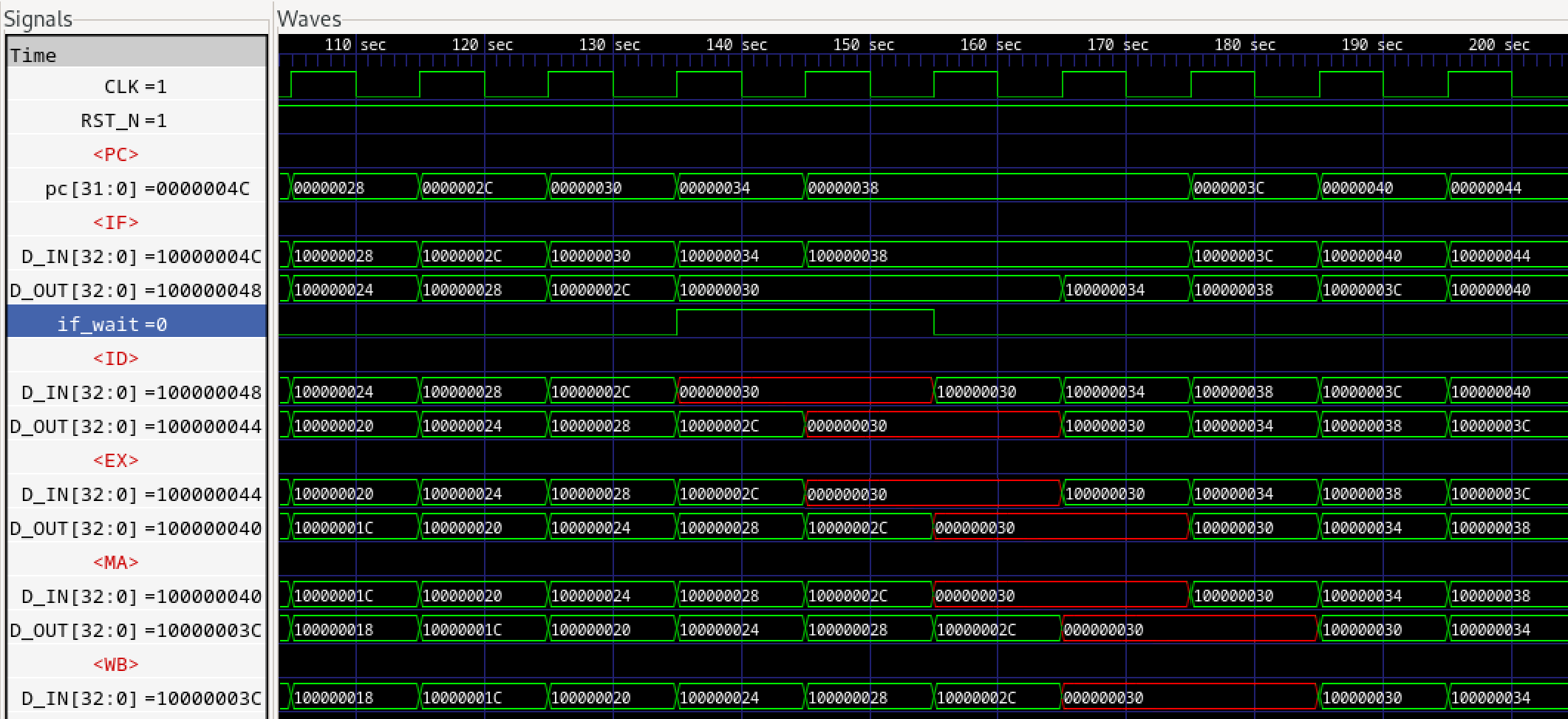
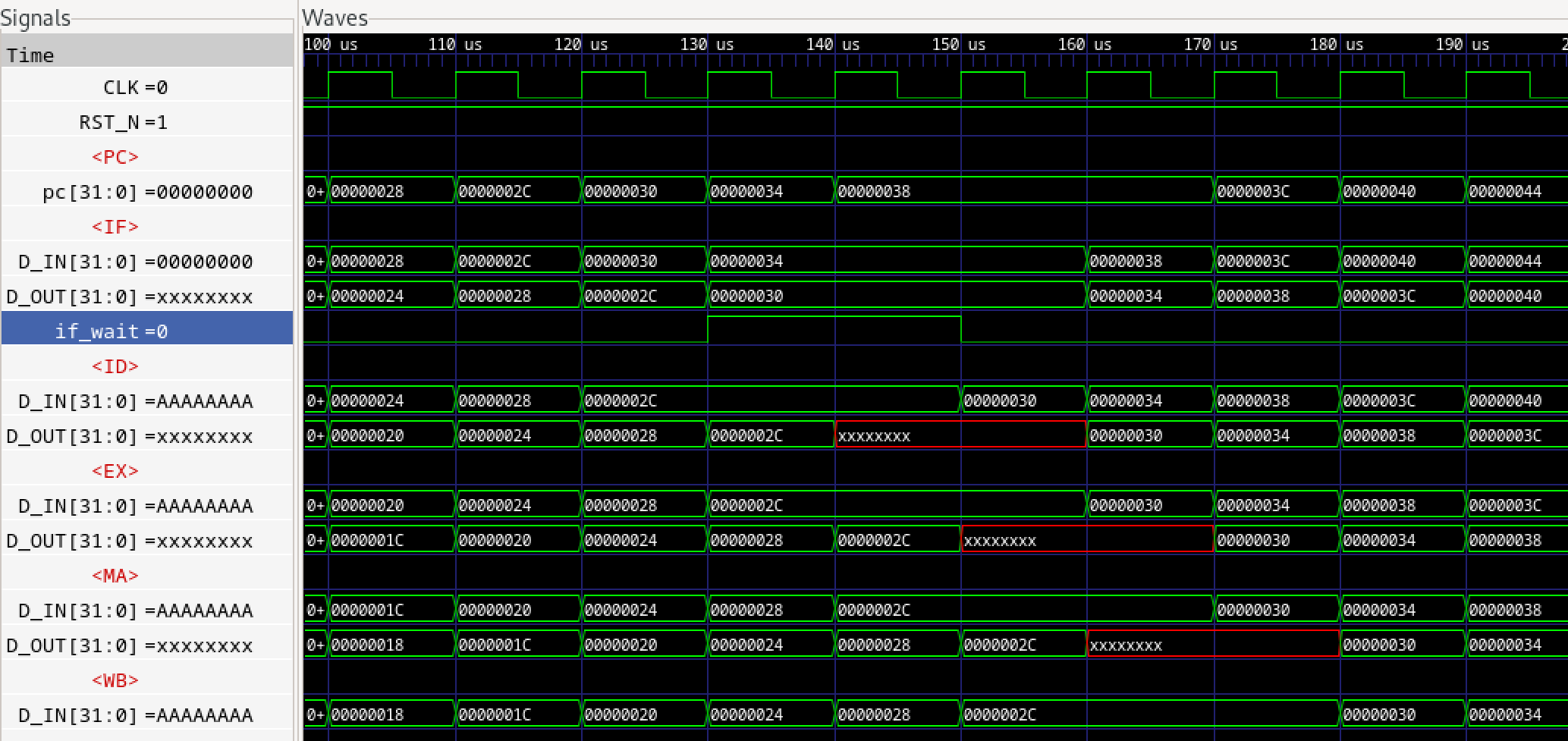
これによりBluespec謹製FIFO2.vと修正版FIFO2.vでシミュレーションを実行しました。これは<ID>にウエイトが2サイクル入った場合のタイミングですが、微妙な差が出ています。まずBluespec謹製版です。
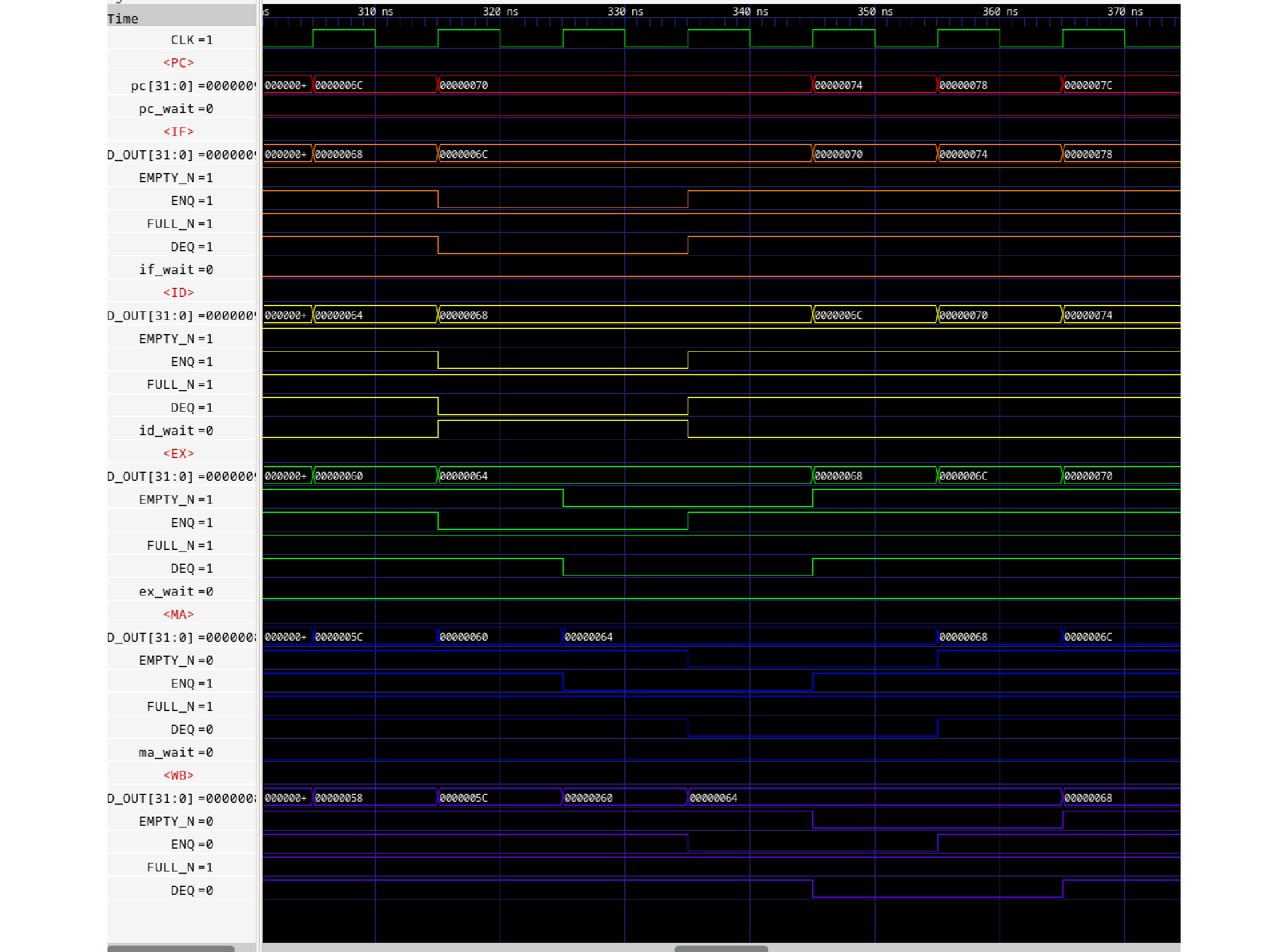 図574.1 パイプラインシミュレーション
図574.1 パイプラインシミュレーション
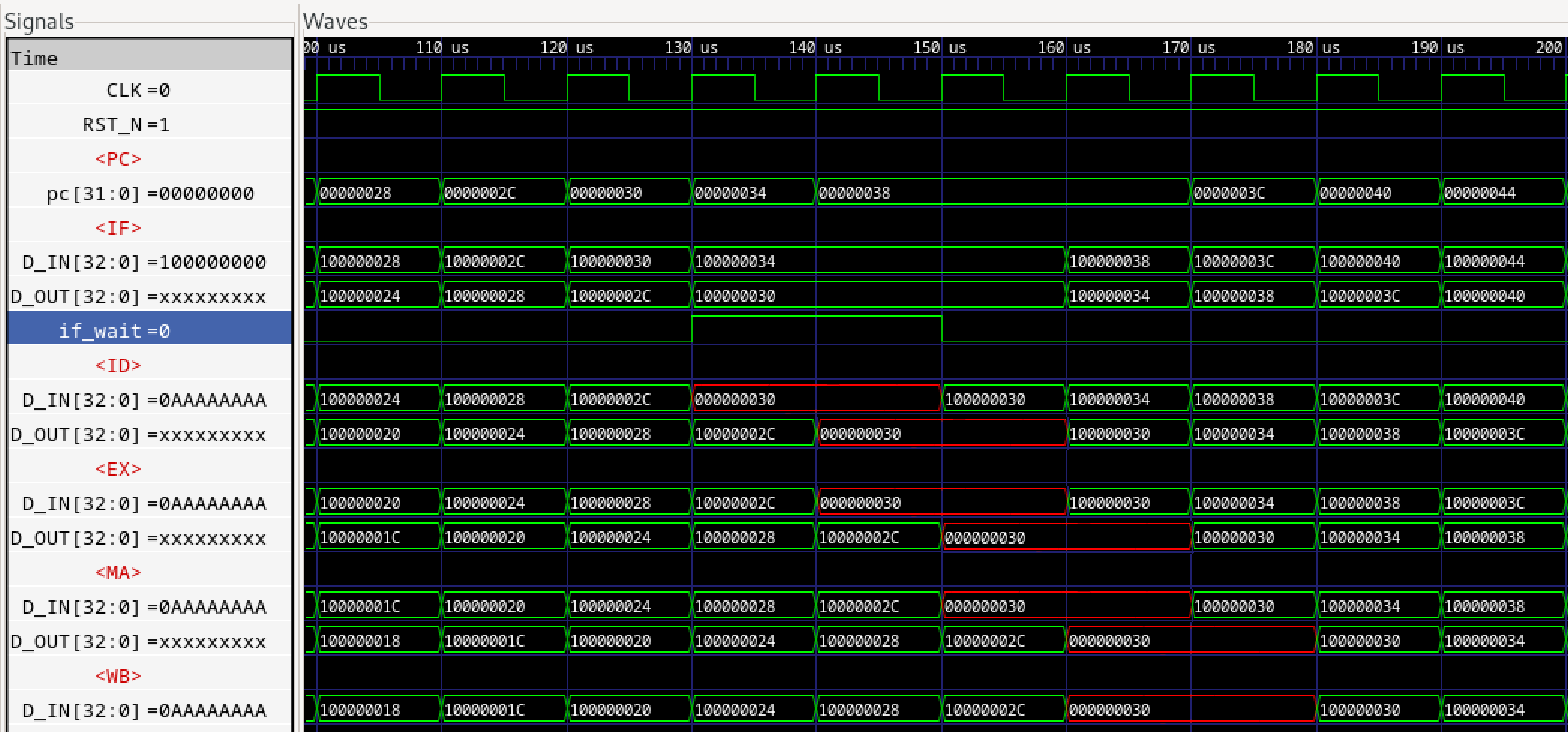
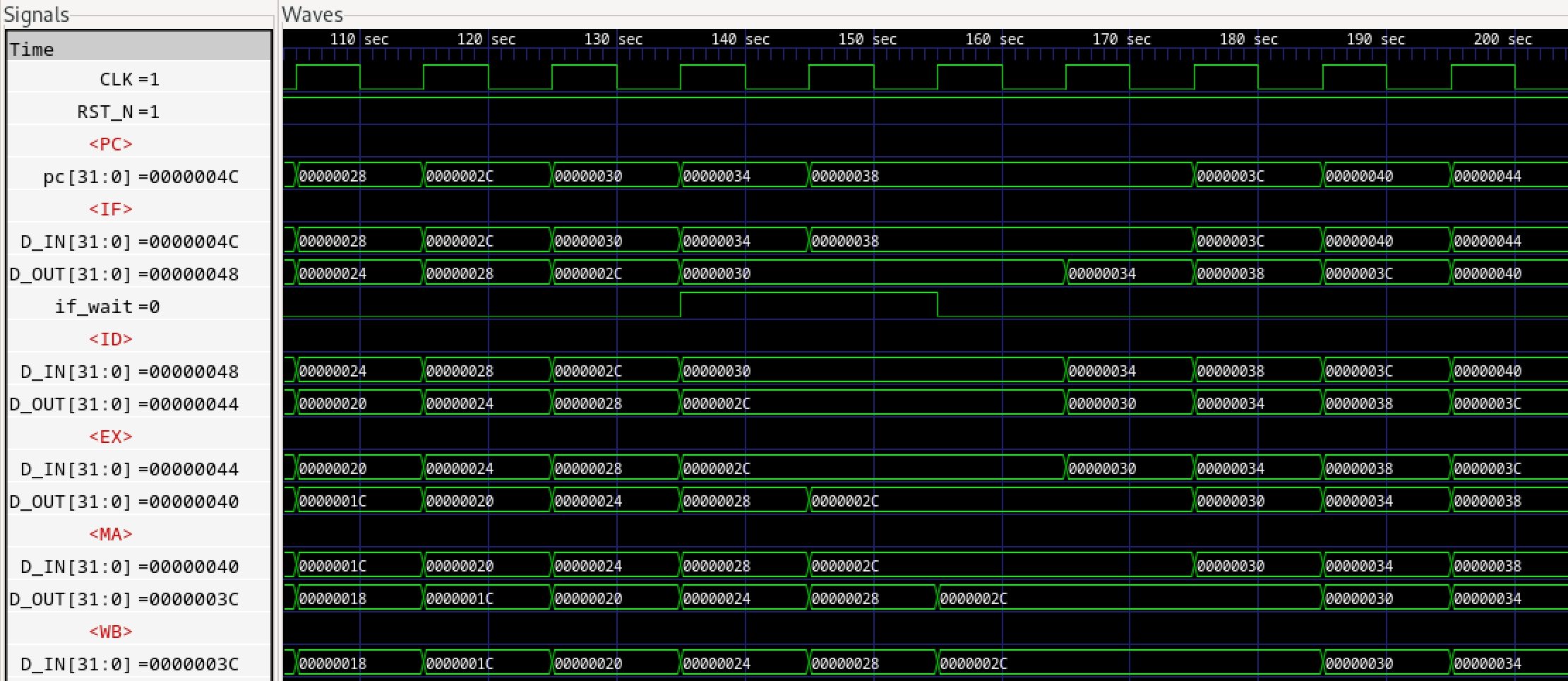
次に弊社での修正版です。
 図574.2 パイプラインシミュレーション
図574.2 パイプラインシミュレーション
読み取りにくいので、表にしてみます。まずBluespec版です。<ID>の2, 3サイクル目に2サイクルのid_wait信号がアサートされた場合です。直接アサートされたサイクルをライトグリーンで、それが同一サイクル内で上流に伝わったステージをライトブルーで塗っています。
表574.1 PCアドレス表
| ステージ |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
| PC |
006c |
0070 |
0070 |
0070 |
0074 |
0078 |
007c |
| IF |
0068 |
006c |
006c |
006c |
0070 |
0074 |
0078 |
| ID |
0064 |
0068 |
0068 |
0068 |
006c |
0070 |
0074 |
| EX |
0060 |
0064 |
0064 |
0064 |
0068 |
006c |
0070 |
| MA |
005c |
0060 |
0064 |
0064 |
0064 |
0068 |
006c |
| WB |
0058 |
005c |
0060 |
0064 |
0064 |
0064 |
0068 |
次に弊社版です。表574.1と相違する部分をライトグレーで塗りました。
表574.2 PCアドレス表
| ステージ |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
| PC |
006c |
0070 |
0070 |
0070 |
0074 |
0078 |
007c |
| IF |
0068 |
006c |
006c |
006c |
0070 |
0074 |
0078 |
| ID |
0064 |
0068 |
0068 |
0068 |
006c |
0070 |
0074 |
| EX |
0060 |
0064 |
0068 |
0000 |
0068 |
006c |
0070 |
| MA |
005c |
0060 |
0064 |
0068 |
0000 |
0068 |
006c |
| WB |
0058 |
005c |
0060 |
0064 |
0068 |
0000 |
0068 |
これで見るとわかるように、ウエイトが入った場合に下流のPC値が相違しています。
本来、パイプラインストールで停止したステージの下流のステージはいわゆるパイプラインバブルとなり、PC値は保証されないはずです。別に設ける予定のバリッドビットが値の妥当性を決めるため、PC値は不定で良いはずです。
パイプラインステージの再実行かと言えば、例えば64番地の命令は繰り返す必要は有りませんし、繰り返してはいけません。例えば64番地の<EX>がデータインクリメント(+1)だった場合には3回の再実行により+3を加算することになり、明らかに誤りです。再実行されるのは、パイプラインウェイトが入ったステージとその上流である68番地以降の再実行となります。
プロセッサではウエイトが入った場合は結果が保証されないのですが、シストリックアレイのような応用ではデキューされた後の状態が同じ状態であって欲しいのかもしれません。そうなると、1, 3, 4, 7も保持(d0)する必要があるかもしれません。試しにd0hに1, 3, 4, 7のケースを加え、反対にd0diに3, 7を加えていたものを引けば、Bluespecと一致する論理となりました。
結論としては推測となりますが、BluespecのFIFO2はデキューしても元の値を保持するのが仕様のようです。
 前のブログ
次のブログ
前のブログ
次のブログ