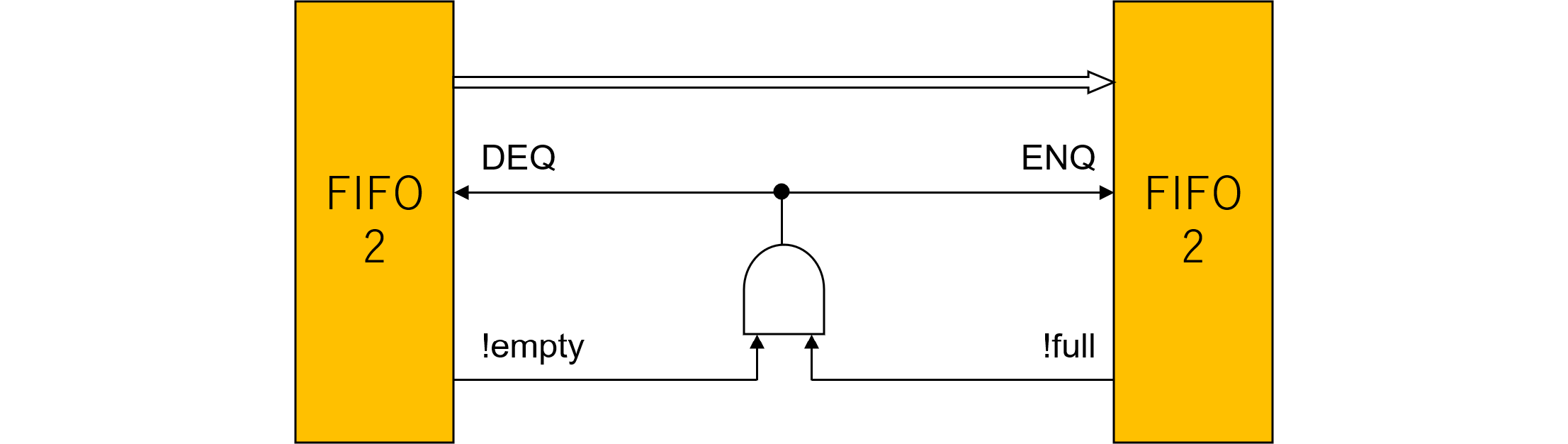
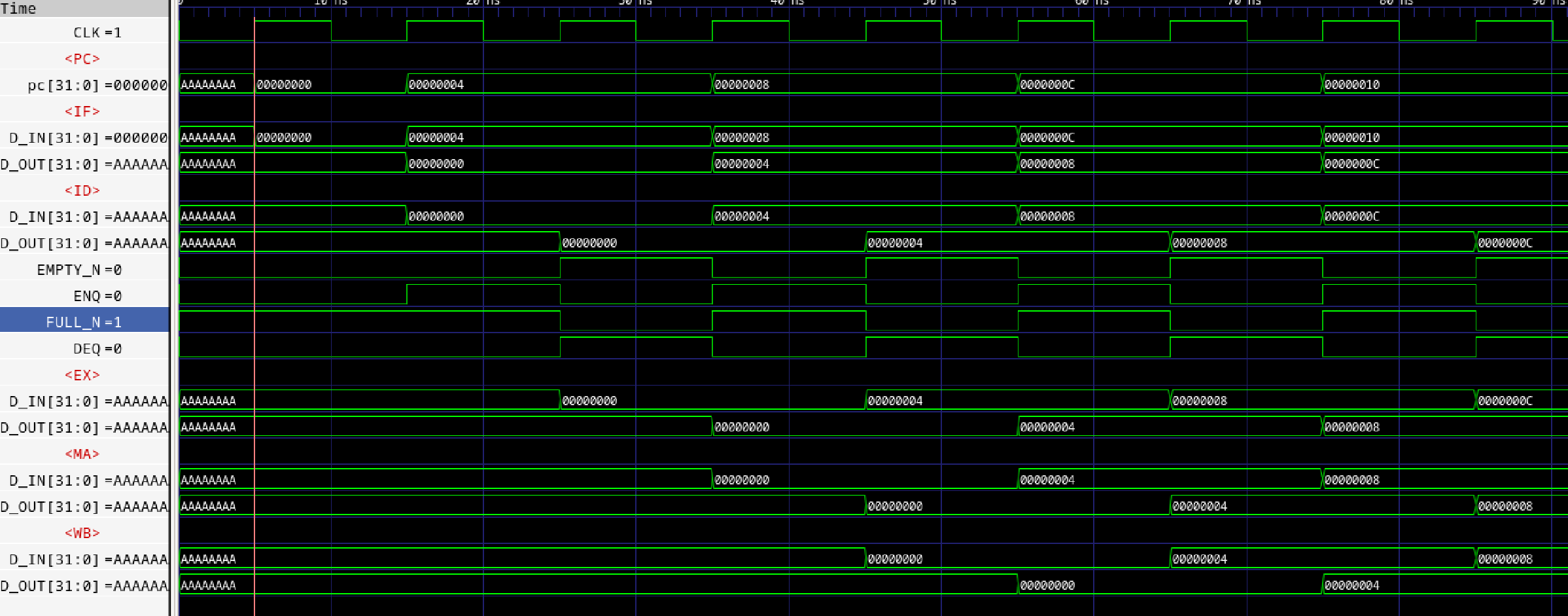
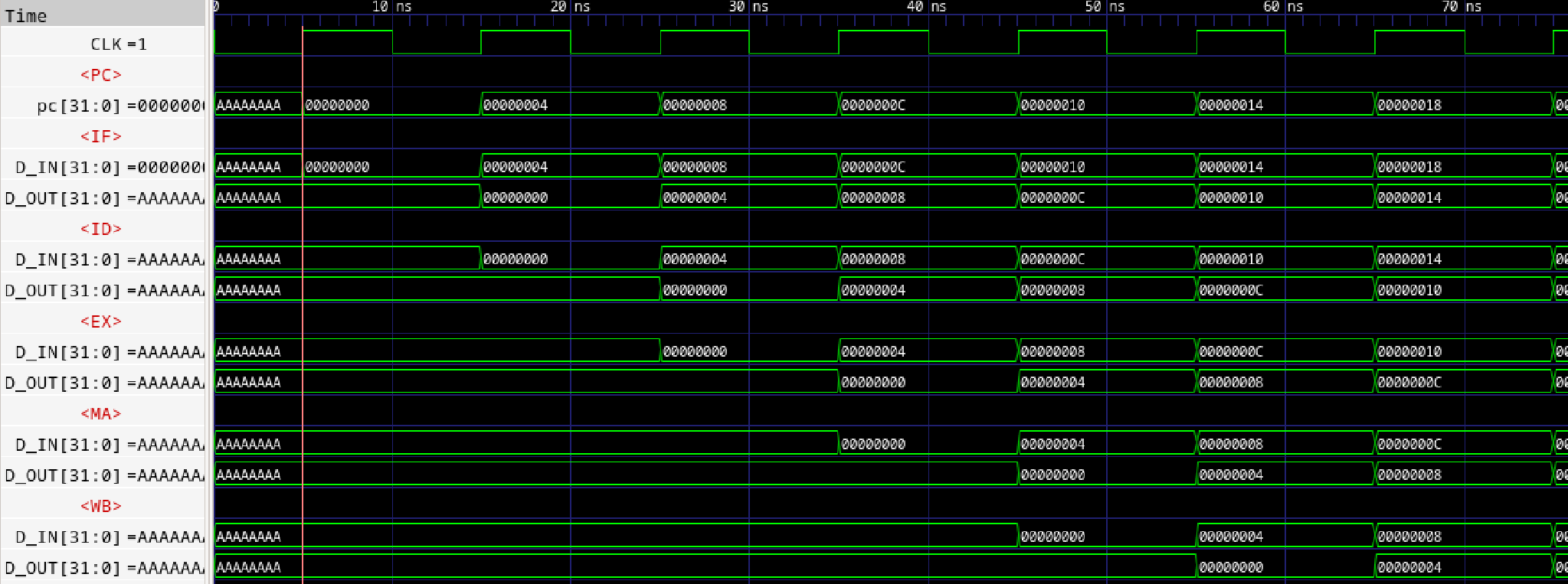
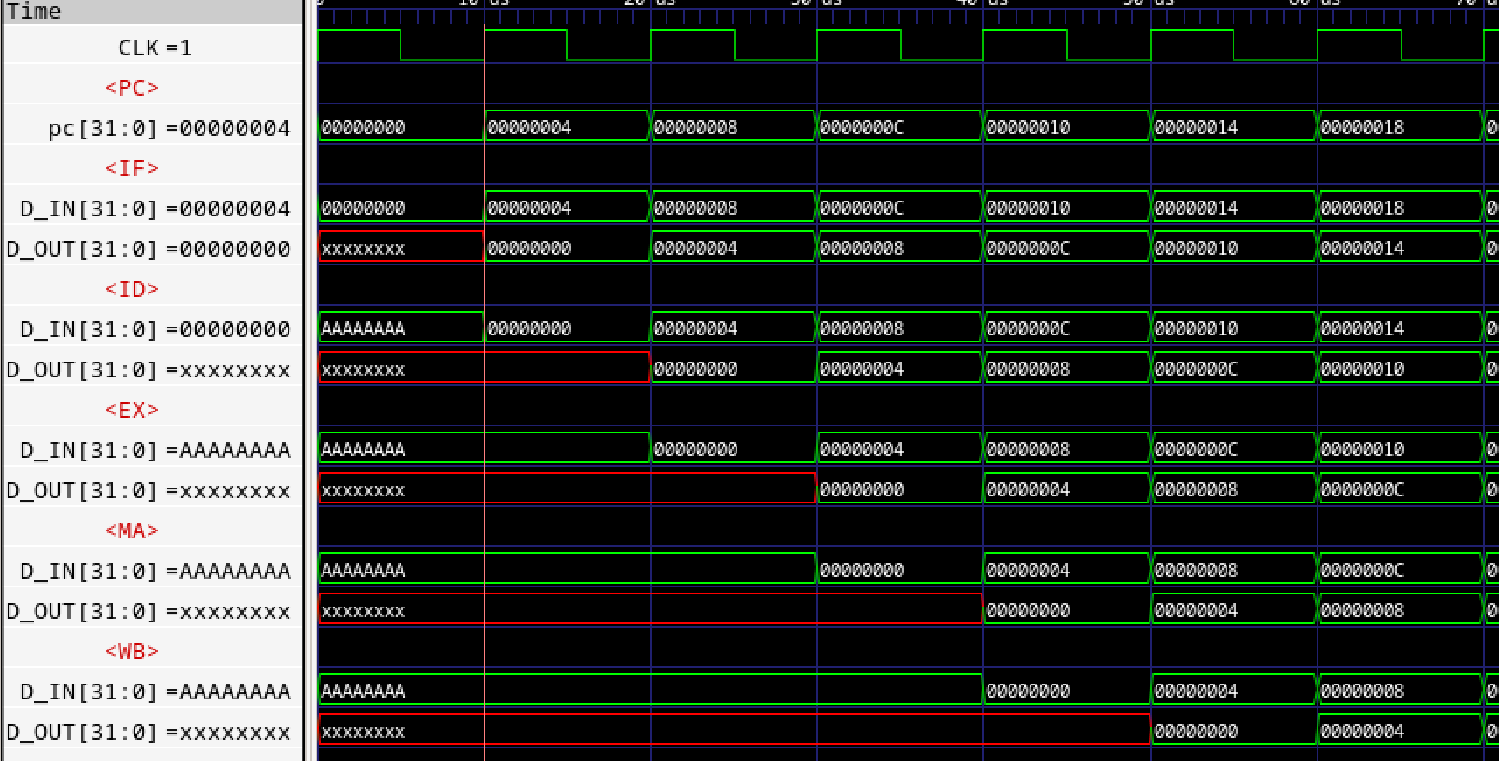
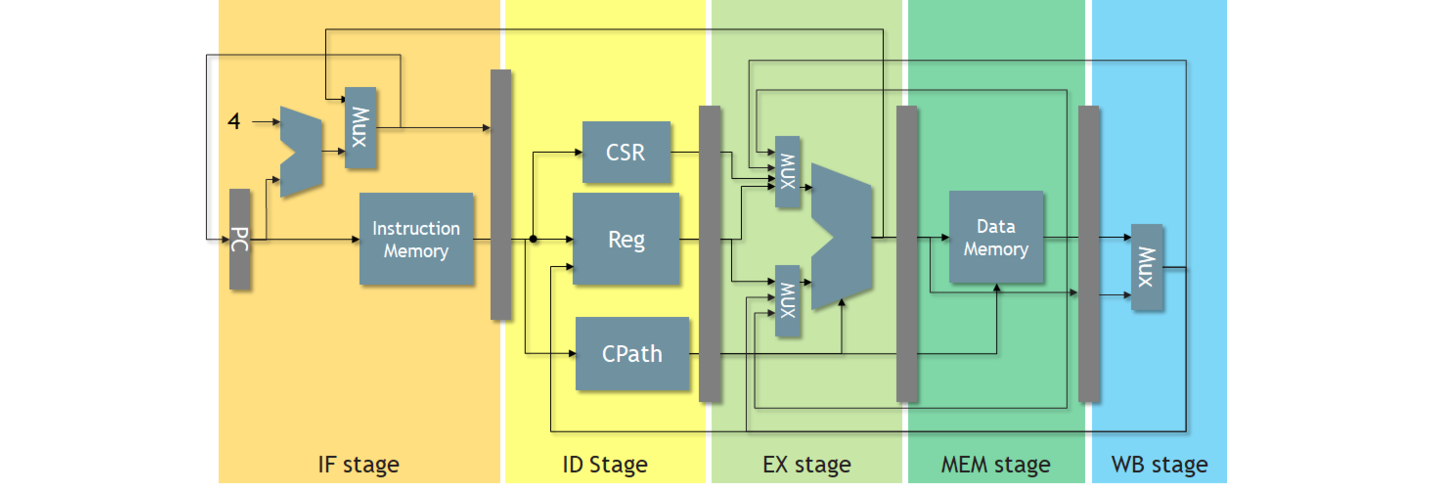
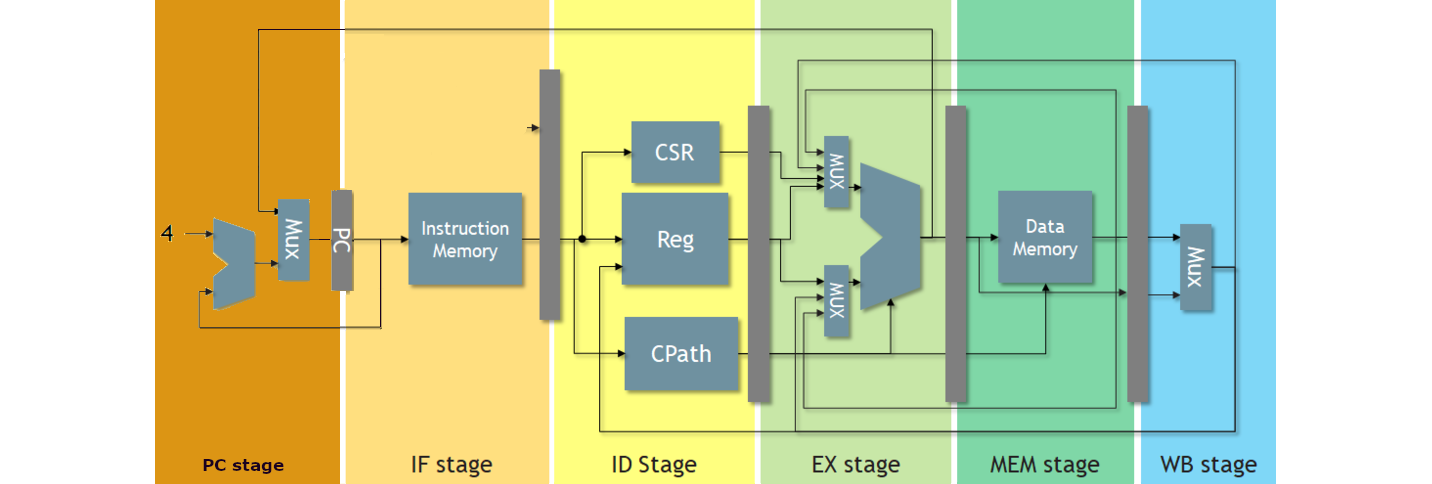
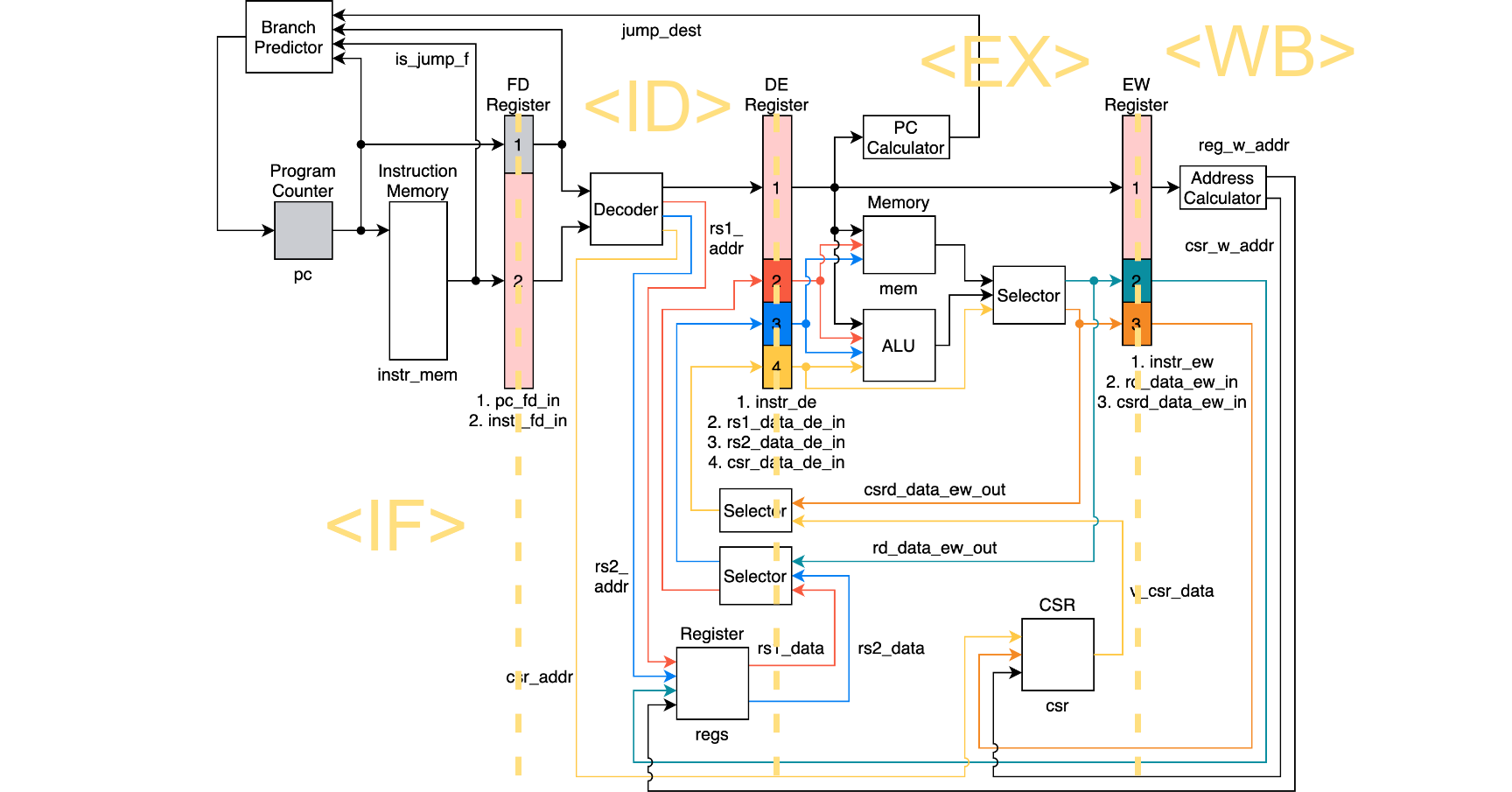
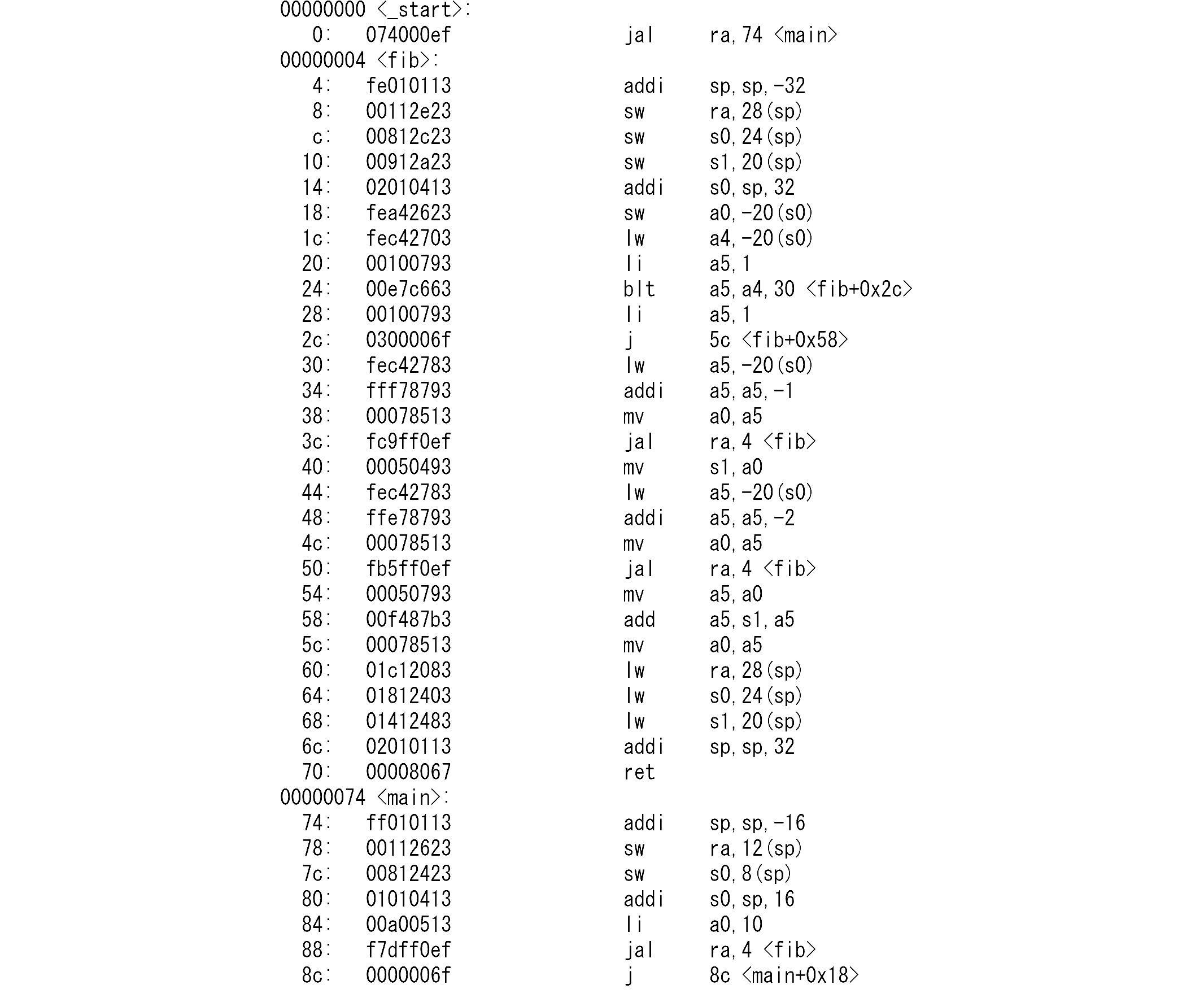
デコーダのソースの一部を示します。
genRules(
switch(in_instr,
when(pat(n(7'b0000000), v, v, n(3'b000), v, n(7'b0110011)), fadd),
when(pat(n(7'b0100000), v, v, n(3'b000), v, n(7'b0110011)), fsub),
when(pat( v, v, n(3'b000), v, n(7'b0010011)), faddi),
when(pat(n(7'b0000000), v, v, n(3'b111), v, n(7'b0110011)), fand),
when(pat(n(7'b0000000), v, v, n(3'b110), v, n(7'b0110011)), ffor),
when(pat(n(7'b0000000), v, v, n(3'b100), v, n(7'b0110011)), fxor),
when(pat( v, v, n(3'b111), v, n(7'b0010011)), fandi),
when(pat( v, v, n(3'b110), v, n(7'b0010011)), fori),
when(pat( v, v, n(3'b100), v, n(7'b0010011)), fxori),
when(pat( v, v, n(3'b010), v, n(7'b0000011)), flw),
when(pat( v, v, v, n(3'b010), v, n(7'b0100011)), fsw),
when(pat(n(7'b0000000), v, v, n(3'b001), v, n(7'b0110011)), fsll),
when(pat(n(7'b0000000), v, v, n(3'b101), v, n(7'b0110011)), fsrl),
when(pat(n(7'b0100000), v, v, n(3'b101), v, n(7'b0110011)), fsra),
when(pat(n(7'b0000000), v, v, n(3'b001), v, n(7'b0010011)), fslli),
when(pat(n(7'b0000000), v, v, n(3'b101), v, n(7'b0010011)), fsrli),
when(pat(n(7'b0100000), v, v, n(3'b101), v, n(7'b0010011)), fsrai),
when(pat(n(7'b0000000), v, v, n(3'b010), v, n(7'b0110011)), fslt),
when(pat(n(7'b0000000), v, v, n(3'b011), v, n(7'b0110011)), fsltu),
when(pat( v, v, n(3'b010), v, n(7'b0010011)), fslti),
when(pat( v, v, n(3'b011), v, n(7'b0010011)), fsltiu),
when(pat(v, v, v, v, n(3'b000), v, v, n(7'b1100011)), fbeq),
when(pat(v, v, v, v, n(3'b001), v, v, n(7'b1100011)), fbne),
when(pat(v, v, v, v, n(3'b100), v, v, n(7'b1100011)), fblt),
when(pat(v, v, v, v, n(3'b101), v, v, n(7'b1100011)), fbge),
when(pat(v, v, v, v, n(3'b110), v, v, n(7'b1100011)), fbltu),
when(pat(v, v, v, v, n(3'b111), v, v, n(7'b1100011)), fbgeu),
when(pat(v, v, v, v, v, n(7'b1101111)), fjal),
when(pat( v, v, n(3'b000), v, n(7'b1100111)), fjalr),
when(pat( v, v, n(7'b0110111)), flui),
when(pat( v, v, n(7'b0010111)), fauipc),
when(pat( v, v, n(3'b001), v, n(7'b1110011)), fcsrrw),
when(pat( v, v, n(3'b101), v, n(7'b1110011)), fcsrrwi),
when(pat( v, v, n(3'b010), v, n(7'b1110011)), fcsrrs),
when(pat( v, v, n(3'b110), v, n(7'b1110011)), fcsrrsi),
when(pat( v, v, n(3'b011), v, n(7'b1110011)), fcsrrc),
when(pat( v, v, n(3'b111), v, n(7'b1110011)), fcsrrci),
when(pat(n(25'b0), n(7'b1110011)), fecall)
) // switch
);
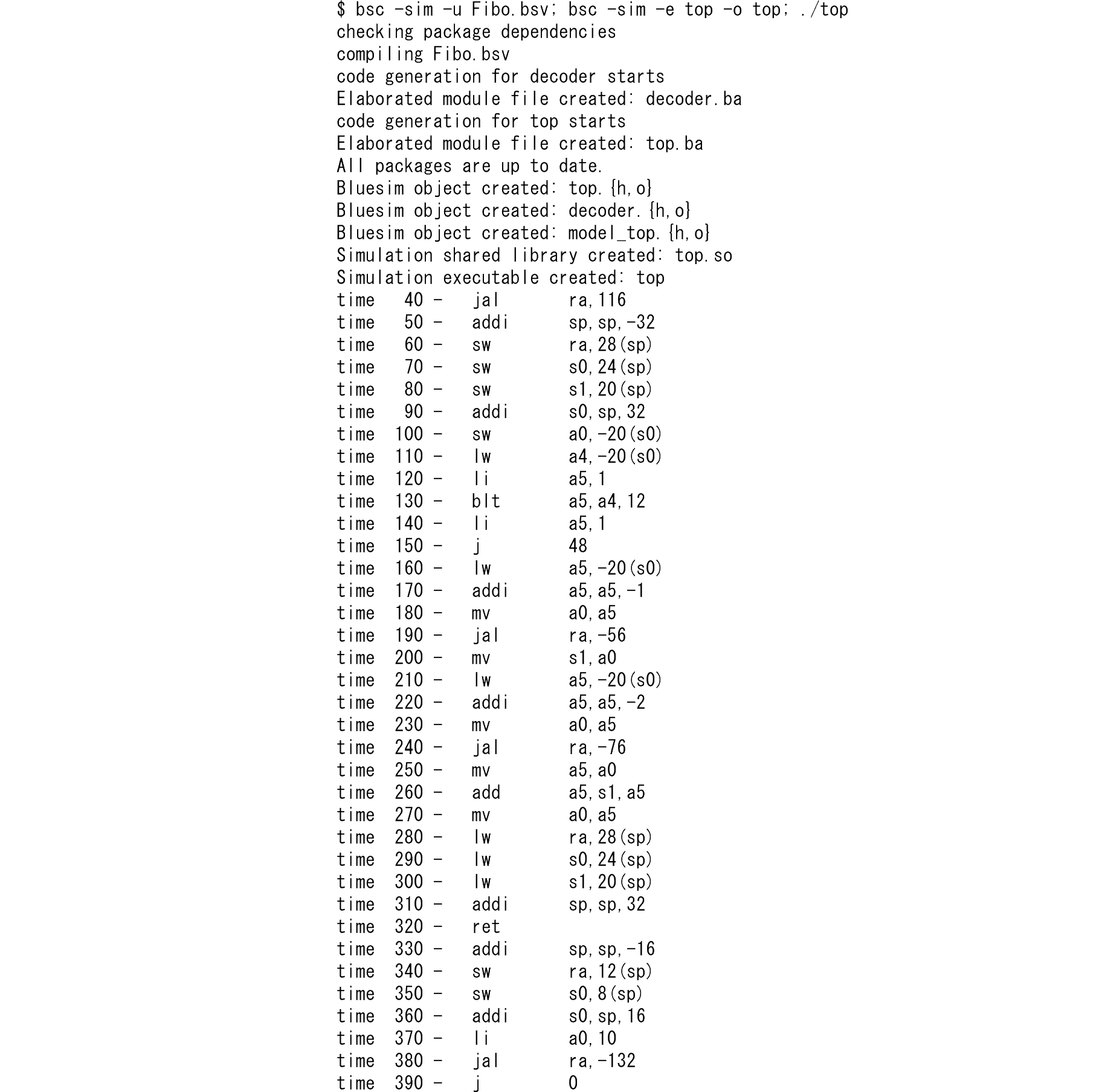
これは1ステップ目のデコーダステップであり、ここでビットパターン、例えばaddi命令とのマッチが取れれば、2ステップ目として個別の関数、例えばfaddiが呼び出されます。一例であるfaddiを示せば、
function Action faddi(Bit#(12) imm, Bit#(5) rs1, Bit#(5) rd) =
action
Int#(32) immSext = signExtend(unpack(imm));
if (immSext == 0)
$display("time %4t - mv\t%s,%s", $time, regname(rd), regname(rs1));
else if (rs1 == 0)
$display("time %4t - li\t%s,%0d", $time, regname(rd), immSext);
else
$display("time %4t - addi\t%s,%s,%0d", $time, regname(rd), regname(rs1), immSext);
endaction;
RISC-Vにおいてaddi命令はイミディエイトがゼロの場合はmv命令として使用され、逆にソースレジスタにゼロレジスタを指定すれば、イミディエイトロード(li)命令として働きます。これらはプロセッサの設計的には不要な処理ですが、逆アセンブラのシンタックスシュガーとして実装しました。
2ステップ目の処理として、各種関数を命令数だけ並べる必要があります。
 前のブログ
次のブログ
前のブログ
次のブログ