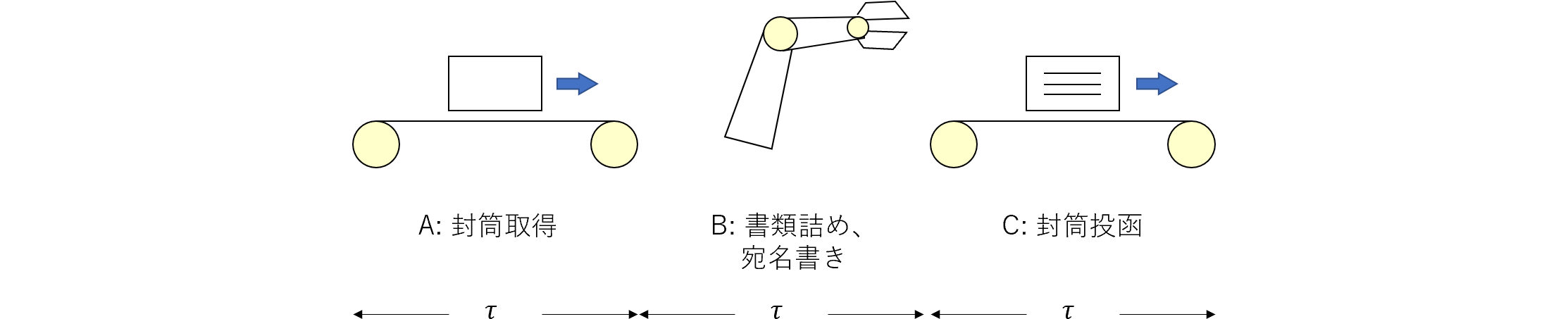
|
9 |
Pipeline processorの設計 (6) |
レジスタフォワーディング
レジスタフォワーディングは単にフォワーディング、またはバイパスと呼ばれることがあります。これは前述のRAWハザードのペナルティ(無駄時間、バブル)を軽減もしくは無化するためのものです。
以下のような命令ストリームがあった時、
1: <PC><IF><ID><EX><MA><WB> 2: <PC><IF><ID><EX><MA><WB> 3: <PC><IF><ID><EX><MA><WB> 4: <PC><IF><ID><EX><MA><WB> 5: <PC><IF><ID><EX><MA><WB>
1:のデスティネーションレジスタは<WB>ステージで書き込まれますが、直後の2の命令ストリームの<ID>で読もうとすると、5の命令のタイミングまでウエイトしなければなりません。つまり2、3、4の命令実行時間の$3\tau$が無駄になります。
これを高速化するのがレジスタフォワーディングで、2の命令デコード時に先行命令のデスティネーションレジスタ番号と自分の命令のソースレジスタ番号の比較を行います。この時同じレジスタであれば、デスティネーションレジスタから読み出すのではなく、演算器の出力をレジスタの結果とみなします。1の命令の<EX>の出力確定は2の命令の<ID>のレジスタ読み出しと同一タイミングなので、レジスタフォワーディング制御としては<EX>の出力を<EX>の入力にフィードバックします。
このバイパス機構を設けることで、本来$3\tau$のバブルが発生するところをバブル無しとなり、RAWハザードを解消することができます。
機構的にはソースレジスタとデスティネーションレジスタの番号をパイプラインで流し、番号が前後の命令で一致するかを見る比較器を設け、一致した場合は命令コードが示すレジスタの内容ではなく、演算器の出力パスをマルチプレクサで選択します。