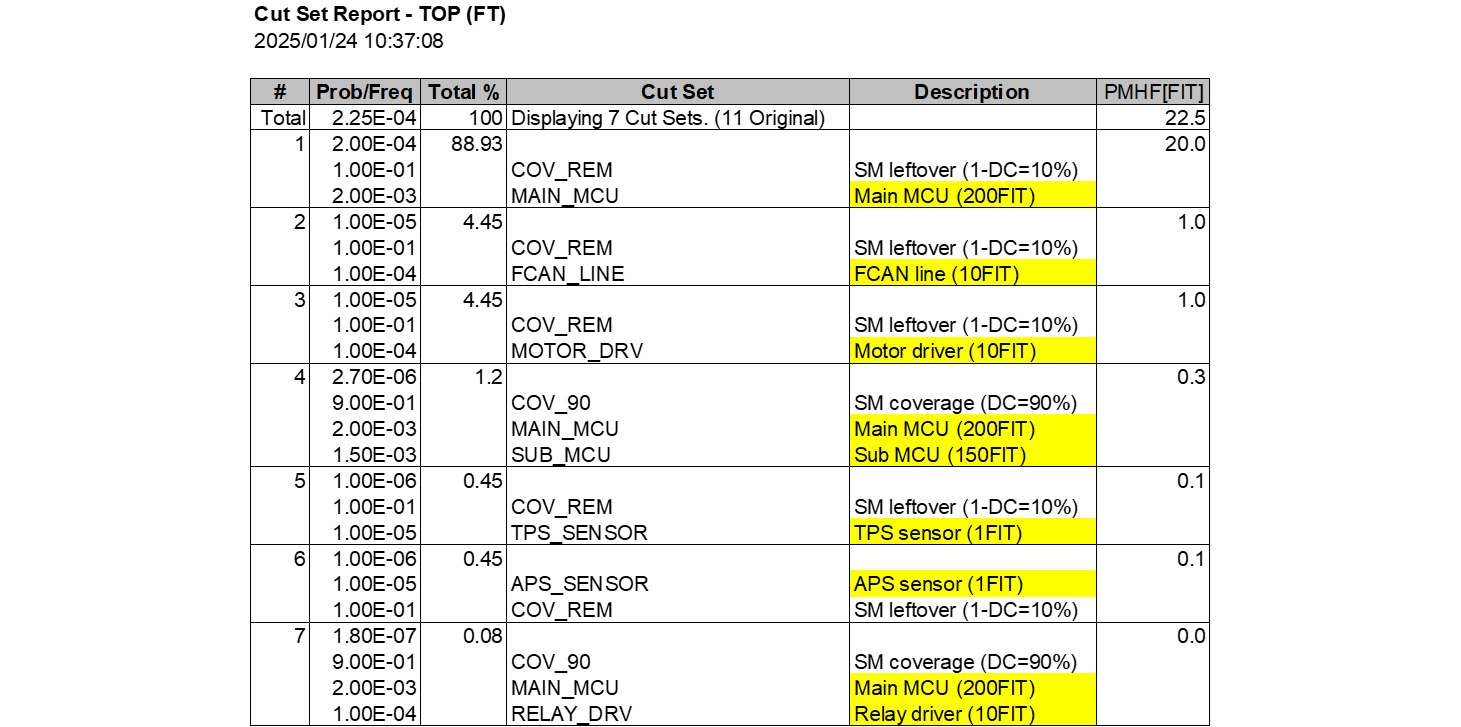
人間にとって、MCSを見ればメインマイコンの安全機構が無効であることが即座に分かり、アーキテクチャ上の問題を発見することはそれほど難しくありません。一方でAIはどうでしょうか?そこでChatGPTにMCSのTop 1, 2を見せて改善提案をしてもらいました。
添付の図が以前のEGASアーキテクチャでしたが、4つの検出ルートが全てメインマイコン、リレードライバに接続されています。一方でメインマイコンはIFのパスにも入っています。従って、MCSを取得すると、
1 1.80E-03 89.04 179.8
9.00E-01 COV_90 SM coverage (DC=90%)
2.00E-03 MAIN_MCU Main MCU (200FIT)
2 2.00E-04 9.89 20.0
1.00E-01 COV_REM SM leftover (1-DC=10%)
2.00E-03 MAIN_MCU Main MCU (200FIT)
となりました。この見方は、
積項の大きい順の順位、積項確率、全体の割合、PMHF
単項確率、項目、説明
:
です。このMCSを分析してアーキテクチャの改善を提案してください。
ChatGPT
下記のMCS(Minimal Cut Set)を見ると、上位2つの積項がいずれも「Main MCUの故障×SM側の定数(Coverage 90%またはLeftover 10%)」によって支配されている点がわかります。具体的には、
- $1.80\times10^{-3}$ (約89%)
- カバレッジ 90% ($0.9$) と Main MCU ($2.0\times10^{-3}$) の積
- $2.00\times10^{-4}$ (約10%)
- レフトオーバー 10% ($0.1$) と Main MCU ($2.0\times10^{-3}$) の積
両方ともMain MCUが故障するとSM(安全機能)を失ってしまう構造、かつ全体の約99%を占めています。
この結果から読み取れるのは、
- Main MCU がシングルポイント故障になっている
- どの検出経路を通っても最終的に Main MCU が要(かなめ)となっており、そこで一度でも故障するとSMが機能しない。
- SM本来のカバレッジ(0.9)やレフトオーバー(0.1)の影響以前に、Main MCU故障が最優先で TOP イベントを引き起こす状態です。
改善提案の方向性
Main MCU の冗長化
- 例えば、SMを作動させるための経路で「Main MCU」を1つだけに頼らず、複数のMCUを並列化(ハード冗長)するなり、あるいは別の独立したマイクロコントローラ(Sub MCU)を真に並列ルートとして挿入する。
- これにより「Main MCUが故障しても、もう1つの健康なコントローラがリレーを遮断できる」構造にすれば、このシングルポイント故障を除去できる。
SM経路から Main MCU を外す/縮小する
- 安全機能(モータ電源遮断)に必須なのがMain MCUだけになっている点を再検討し、「サブマイコン(Sub MCU)が単独でリレードライバを制御できる」といった構造を更に強化する。
- 現状、サブマイコンがDriver Diagを監視してはいるが、最終的にリレーを駆動する際にMain MCUが絶対必須になっていないかを再確認する。
レフトオーバー(1-DC=10%)の低減
- Main MCUのFIT値を下げる(設計・選定を高信頼品にする)と同時に、SMの診断カバレッジを上げて(1-DCを5%以下などにできれば)、残余故障による寄与を減らす。
- MCSを見ると2番目のカットセットにおいても(COV_REM=0.1) と Main MCU故障が組み合わさっているので、低カバレッジによるSM失敗を抑えるメリットがある。
サブマイコン(150FIT)をもっと活用する
- 図上ではサブマイコンがDriver Diagと直接配線されているが、実際にはAPS/TPSなどもサブマイコン側で検出できればMain MCU故障時のバックアップになる。
- そうすれば、検出フェーズの並列度が向上して「Main MCUが壊れてもサブマイコンがAPS/TPS異常を捉えてリレーを遮断する」ルートが確立し、Main MCU依存を下げられる。
結論
MCS結果からはMain MCUがどの経路でもシングルポイントになっているため、ほぼ全ての失敗モードが「Main MCU故障 ×(Coverage or leftover)」で占められています。
最も効果的な対策は、
(1) Main MCUを冗長化または
(2) SM制御における依存度を下げる(Sub MCUを独立経路にする)ことで、Main MCU一台の故障がSM全体を止めないようにする構造改善です。さらに
(3) レフトオーバー10%の低減も併せて行えば、PMHFを大幅に削減可能と考えられます。
ChatGPT の回答は必ずしも正しいとは限りません。重要な情報は確認するようにしてください。
回答文の表現は微妙で、DCと1-DCの相補関係が分かっているのか分かっていないのかが微妙です。
Main MCU がシングルポイント故障になっている
これが狭義のSPFであればまさにそのとおりです。狭義のSPFとはSMを持たないIFのフォールトであり、DCと1-DCを加えて1となるということは、SMが全くカバーしていないことを意味します。
ちなみに、広義のSPFは狭義のSPFとRFを会わせたものを指します
SM本来のカバレッジ(0.9)やレフトオーバー(0.1)の影響以前に、Main MCU故障が最優先で TOP イベントを引き起こす状態
ところが、影響以前もなにも、DCと1-DCなので加えれば影響はありません。影響があることを前提としているようなので、理解が間違っているようにも思われます。
改善提案の方向性
案1. Main MCU の冗長化
Main MCUが故障確率の1位なので当然ともいえる提案ですが、コストがかかるのが難点です。
案2. SM経路から Main MCU を外す/縮小する
これが人間の考えた方式と一致する案であり、正解といえます。
案3. レフトオーバー(1-DC=10%)の低減
この提案は誤りです。COV_90とCOV_REMは相補関係にあり、1-DCであるCOV_REMが減少すればDCであるCOV_90が増加します。さらに仮に独立だとしてもCOV_90のほうが9倍も大きいので減少させるならtop1のほうでしょう。
案4. サブマイコン(150FIT)をもっと活用する
サブマイコンよりもメインマイコンの故障確率が支配的なので、的を射た提案とは言えません。
なお、本稿はRAMS 2026に投稿予定のため一部を秘匿していますが、論文公開後の2026年2月頃に開示予定です。
 前のブログ
次のブログ
前のブログ
次のブログ