|
20 |
RISC-Vプロセッサの設計 (3) |
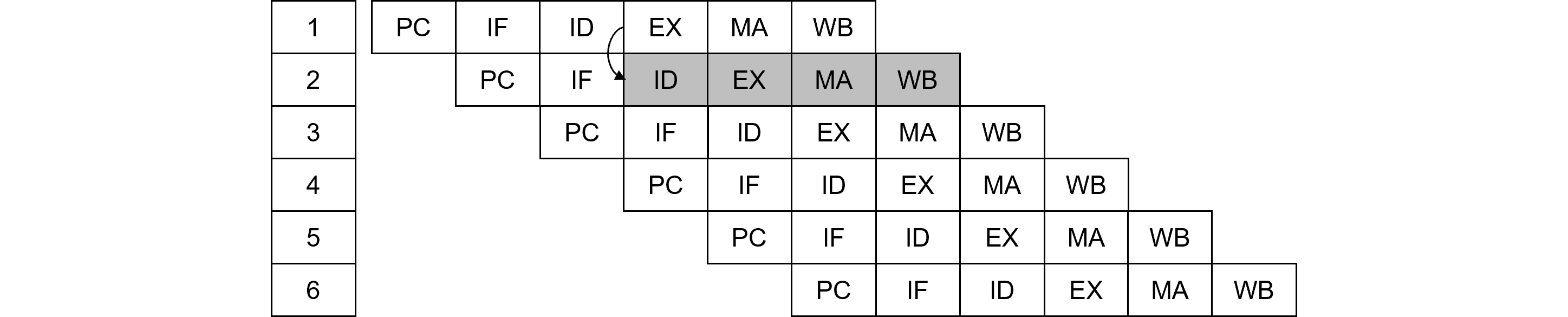
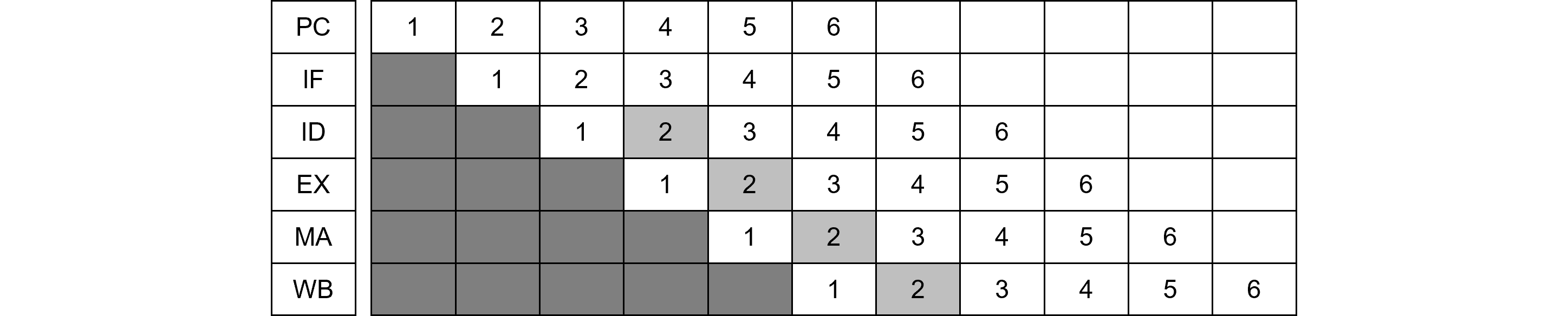
「ハードウェアインタプリター」に食わせる機械語列が必要です。そこで、この記事を参考に、Fibonacciプログラムをコンパイルし機械語化しました。試みにFibonacciが通るための「インタプリター」を書いていきます。前述のとおりこの「インタプリター」は実行ステージが逆アセンブル相当の表示をするだけのものです。
入力するFibonacciのソースは以下のように短いプログラムです。
fibo.c:
int fib(int n) {
if(n <= 1) return 1;
return fib(n-1) + fib(n-2);
}
int main() {
fib(10);
for(;;) {}
return 0;
}
これをクロスコンパイルしてRISC-Vの命令を作成し、BSVの入力とします。シーケンサの自動生成を利用して1サイクル毎に、命令デコーダに命令を供給します。
Stmt main = seq
instr <= 32'h074000ef;
instr <= 32'hfe010113;
instr <= 32'h00112e23;
instr <= 32'h00812c23;
instr <= 32'h00912a23;
instr <= 32'h02010413;
instr <= 32'hfea42623;
instr <= 32'hfec42703;
instr <= 32'h00100793;
instr <= 32'h00e7c663;
instr <= 32'h00100793;
instr <= 32'h0300006f;
instr <= 32'hfec42783;
instr <= 32'hfff78793;
instr <= 32'h00078513;
instr <= 32'hfc9ff0ef;
instr <= 32'h00050493;
instr <= 32'hfec42783;
instr <= 32'hffe78793;
instr <= 32'h00078513;
instr <= 32'hfb5ff0ef;
instr <= 32'h00050793;
instr <= 32'h00f487b3;
instr <= 32'h00078513;
instr <= 32'h01c12083;
instr <= 32'h01812403;
instr <= 32'h01412483;
instr <= 32'h02010113;
instr <= 32'h00008067;
instr <= 32'hff010113;
instr <= 32'h00112623;
instr <= 32'h00812423;
instr <= 32'h01010413;
instr <= 32'h00a00513;
instr <= 32'hf7dff0ef;
instr <= 32'h0000006f;
endseq;
今回はまだデコーダのテストだけなので、PCは実装していません。