|
27 |
BSVによるSpace Invadersの変更 (9) |
Posts Tagged with "Design"
既に発行済みのブログであっても適宜修正・追加することがあります。We may make changes and additions to blogs already published.
|
26 |
BSVによるSpace Invadersの変更 (8) |
Y字リプレースアニメーションのソース
Y字リプレースアニメーションのソースを示します。Y字リプレースアニメーションもFボタンにより中断するため、各所でFボタンを見ています。
function Stmt replaceY;
return (seq
// from right to left
for (i <= 228; i >= 142; i <= i - 2) seq
copyArea((pack(i)[1] == 1'b1) ? 68 : 84 , 32, i, 67, 10, 8);
wait_timer(`TICK_WAIT3);
if (fbutton) break;
endseq // for
if (fbutton) break;
// from left to right
for (i <= 136; i <= 226; i <= i + 2) seq
copyArea((pack(i)[1] == 1'b1) ? 75 : 91 , 107, i, 67, 16, 8);
wait_timer(`TICK_WAIT3);
if (fbutton) break;
endseq // for
eraseArea(226, 67, 16, 8);
wait_timer(`TICK_WAIT32);
if (fbutton) break;
// from right to left
for (i <= 226; i >= 136; i <= i - 2) seq
copyArea((pack(i)[1] == 1'b1) ? 77 : 93 , 117, i, 67, 16, 8);
wait_timer(`TICK_WAIT3);
if (fbutton) break;
endseq // for
wait_timer(`TICK_WAIT32);
if (fbutton) break;
eraseArea(141, 67, 9, 8);
wait_timer(`TICK_WAIT32);
if (fbutton) break;
endseq);
endfunction
これだけでなく、タイマールーチンの中でもFボタンによる中断を見ていますが、ちょっとやり過ぎのようです。実際には多少間引いても体感に影響しないと思います。
|
23 |
BSVによるSpace Invadersの変更 (7) |
オープニングアニメーションのソース
オープニングアニメーションのソースを示します。オープニングアニメーションはFボタン(コイン投入の模擬)により中断するため、各所でFボタンを見ています。
function Stmt openingAnimation;
return (seq
// Opening Animation
foa <= True;
eraseArea( 0, 41, 255, 199); // erase screen
eraseArea(25,242, 5, 7); // erase zanki
stringS1; // PLAY ...
if (fbutton) break;
wait_timer(`TICK_WAIT64);
if (fbutton) break;
stringS2; // *SCORE ...
if (fbutton) break;
wait_timer(`TICK_WAIT32);
if (fbutton) break;
stringS3; // =? MYSTERY ...
if (fbutton) break;
wait_timer(`TICK_WAIT64);
if (fbutton) break;
replaceY; // ^ -> Y
if (fbutton) break;
wait_timer(`TICK_WAIT64);
if (fbutton) break;
foa <= False;
endseq);
endfunction
|
22 |
BSVによるSpace Invadersの変更 (6) |
オープニングアニメーションの追加
テスト用のソースを示します。コンパイル時間短縮のため、ゲーム部分をカットしています。
// メインフロー
Stmt main = seq
while (True) seq
while (!fbutton) seq
openingAnimation; // Fボタンによりブレーク
endseq // while
openingDisplay; // 表示のみ、ボタンを待たない
await(sbutton); // Sボタンによりブレーク
openingDisplay2; // タイマーによりブレーク
// game start
endseq // while
endseq;
// CREDIT 01, "PUSH ONLY 1PLAYER BUTTON"
function Stmt openingDisplay;
return (seq
eraseArea( 0, 41, 255, 199); // erase screen
stringS5; // PUSH ONLY ...
copyArea(10, 162, 217, 241, 5, 7); // CREDIT 00->01
endseq);
endfunction
// CREDIT 00, "PLAY PLAYER<1>, 00000"
function Stmt openingDisplay2;
return (seq
eraseArea( 0, 41, 255, 199); // erase screen
stringS6; // PLAY PLAYER<1>
copyArea(2, 162, 217, 241, 5, 7); // CREDIT 01->00
for (i <= 1; i < 15; i <= i + 1) seq
// erase zero
eraseArea(40, 25, 37, 7);
wait_timer(`TICK_WAIT4); // wait 66.66msec
stringS7; // 00000
wait_timer(`TICK_WAIT4); // wait 66.66msec
endseq // for
endseq);
endfunction
|
21 |
BSVによるSpace Invadersの変更 (5) |
オープニングアニメーションの追加
この動画の最初の部分を参考にして、オープニングアニメーションを作成します。
- インベーダの種類や点数の紹介、と同時に逆さYを引っ張って行き正立Yに入れ替えます。アニメーションがメインなので、これをopeningAnimationシーケンスと呼び、同名の関数により実行します。Fボタンによりコイン投入を模擬します。
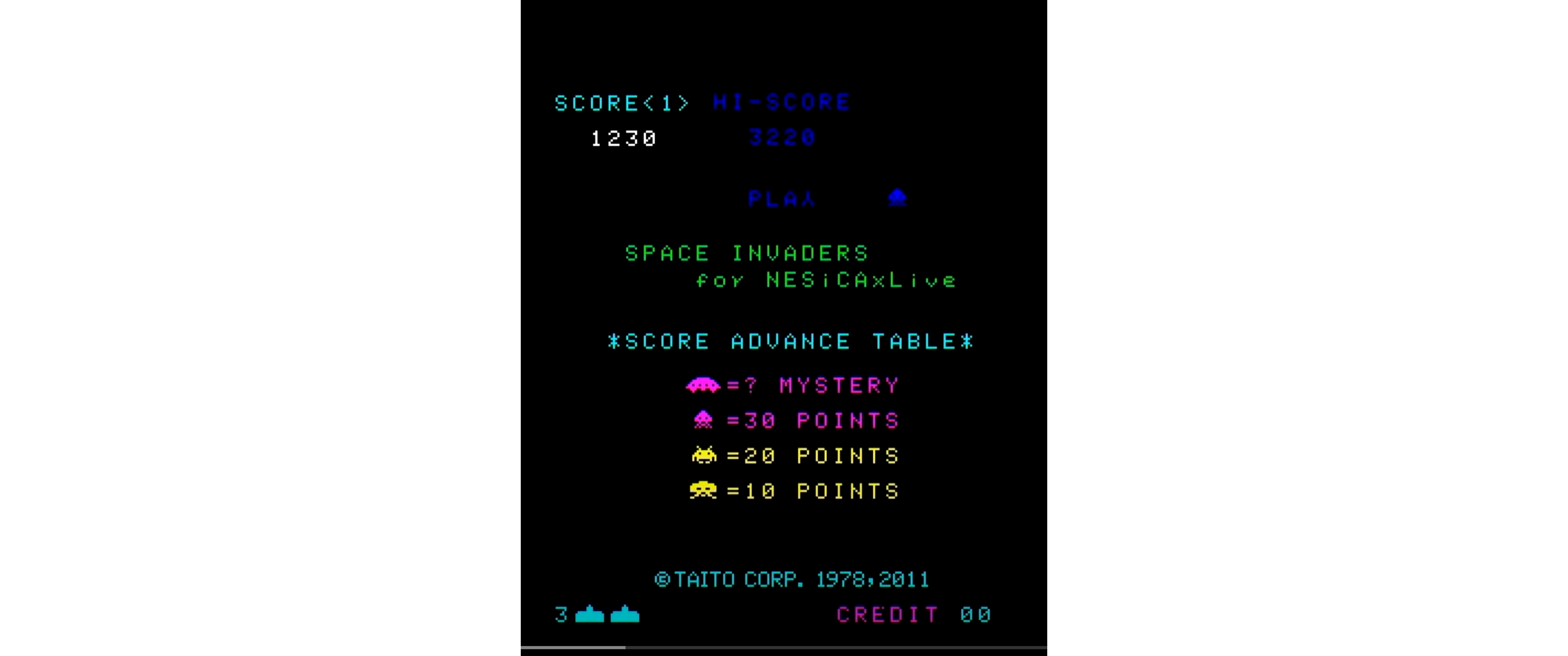
図513.1 openingAnimation画面 - コインを投入すると、"PUSH ONLY 1PLAYER BUTTON"と表示され、CREDITが+1されます。アニメーションは無いため、これをopeningDisplayシーケンスと呼び、同名の関数により実行します。Sボタンを待ちます。
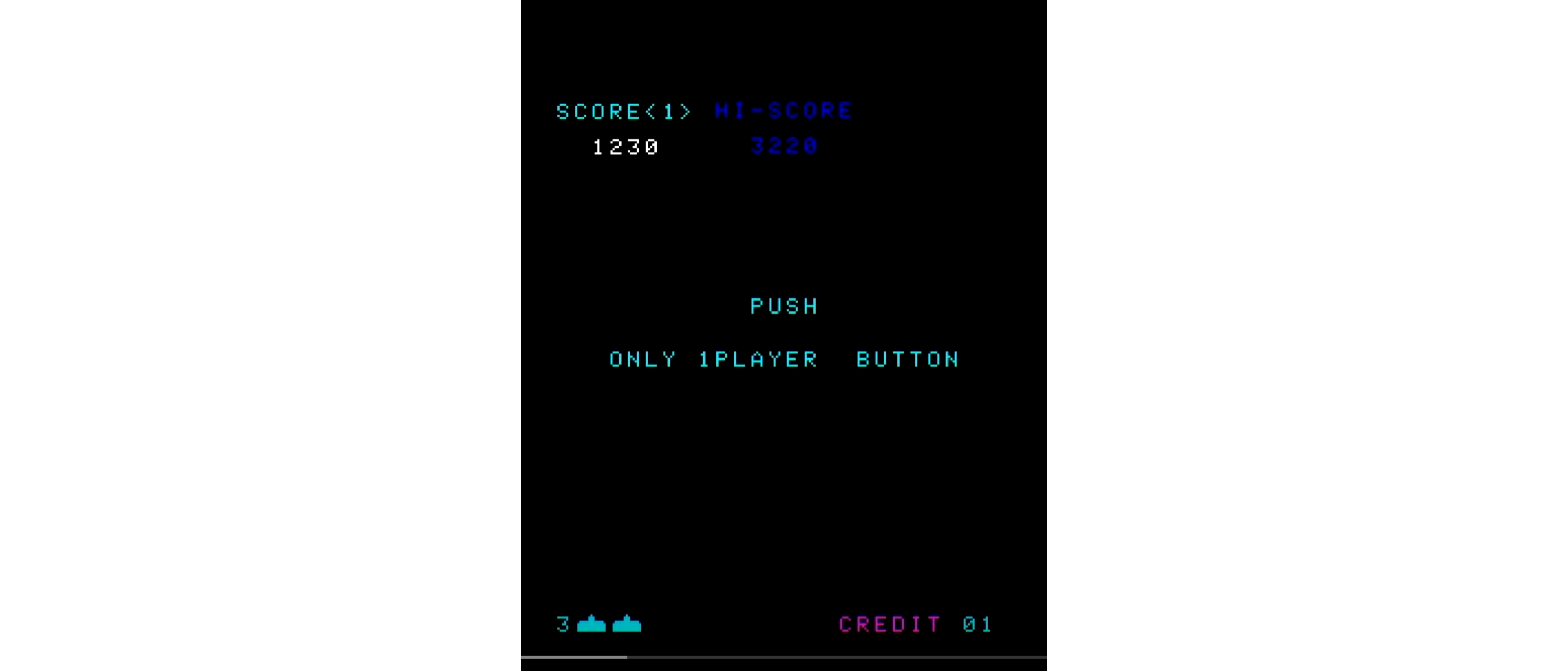
図513.2 openingDisplay画面 - Sボタンを押すと、"PLAY PLAYER<1>"と表示され、CREDITが-1されます。同時に得点が"00000"となり、点滅します。これをopeningDisplay2シーケンスと呼び、同名の関数により実行します。
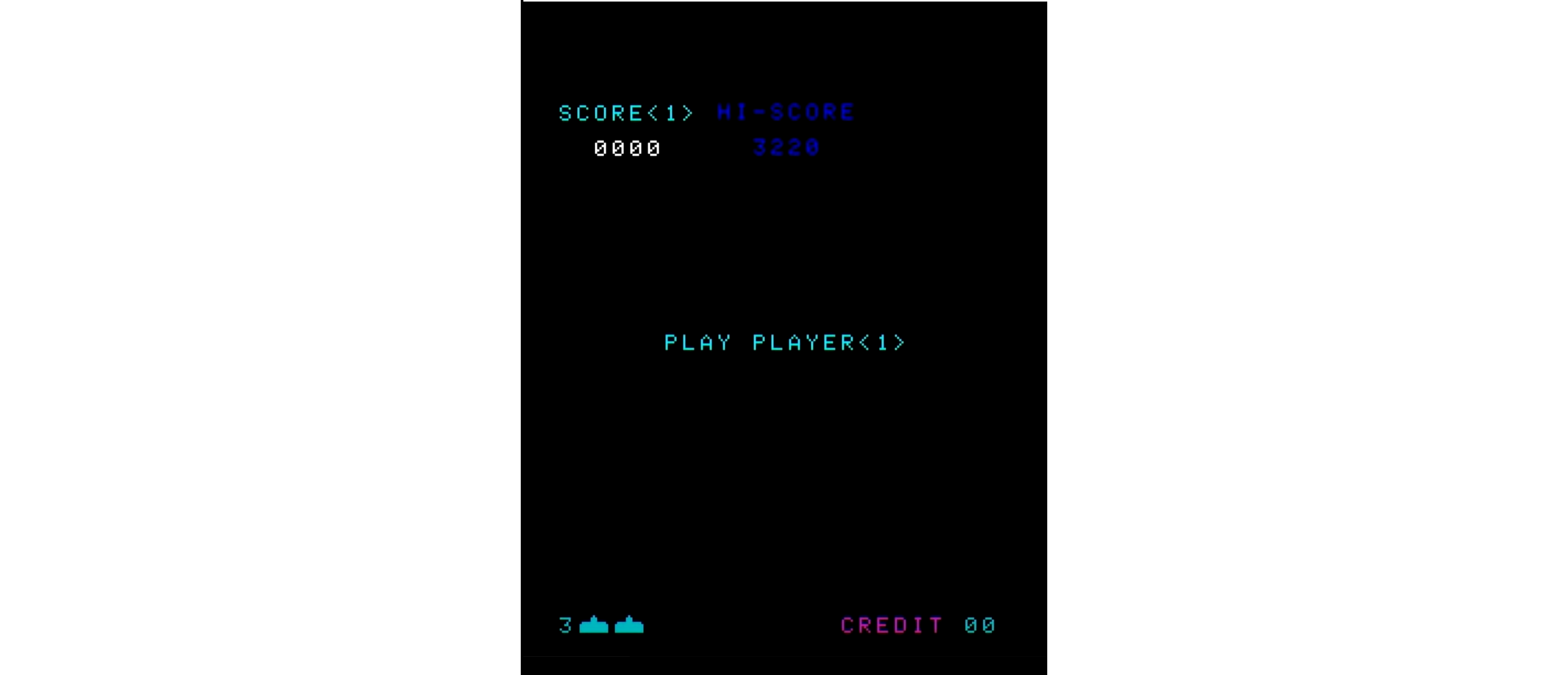
図513.3 openingDisplay画面1 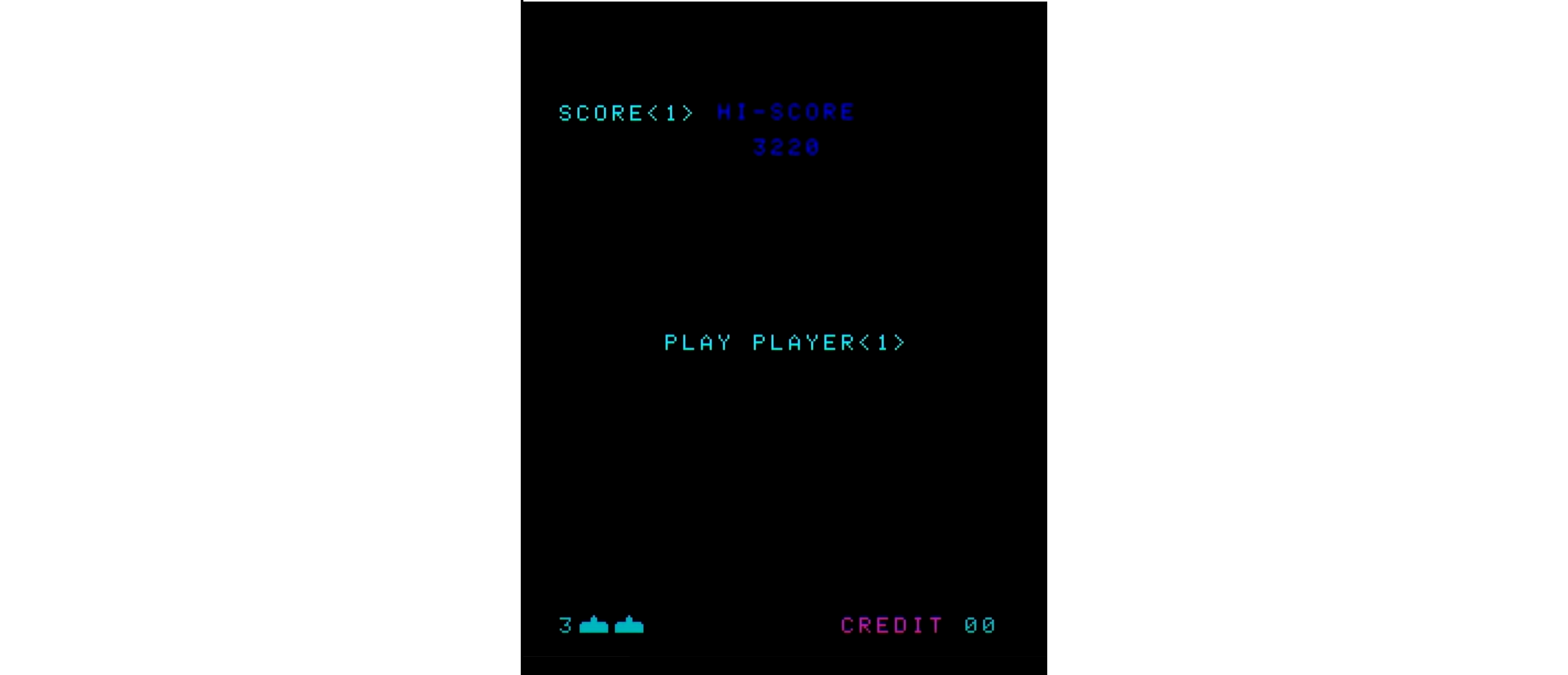
図513.4 openingDisplay画面2 - ゼロ点滅を規定回数実行すると自動的にゲームを開始します。
図513.5にSボタンとFボタンの配置を示します。

|
20 |
BSVによるUARTの再設計 (2) |
テストベンチ
テストベンチは変わりません。
Tb.bsv
import StmtFSM::*;
import Uart::*;
(* synthesize *)
module mkTb();
Uart_ifc uart <- mkUart();
Stmt s = seq
delay(8);
uart.load(8'h55);
uart.load(8'haa);
uart.load(8'hc3);
uart.load(8'h3c);
await(uart.done());
$finish;
endseq;
mkAutoFSM(s);
endmodule
Bsimシミュレーション
Bsimシミュレーションのコマンドは次のとおりです。
$ bsc -u -sim Tb.bsv; bsc -sim -e mkTb -o Tb.exec; ./Tb.exec -V bsim.vcd; gtkwave -A bsim.vcd
以下にBsimシミュレーション結果を示します。意外なことに明示的にdone信号を書いたにも関わらず、シミュレーションのダンプの中にdone信号がありませんでした。
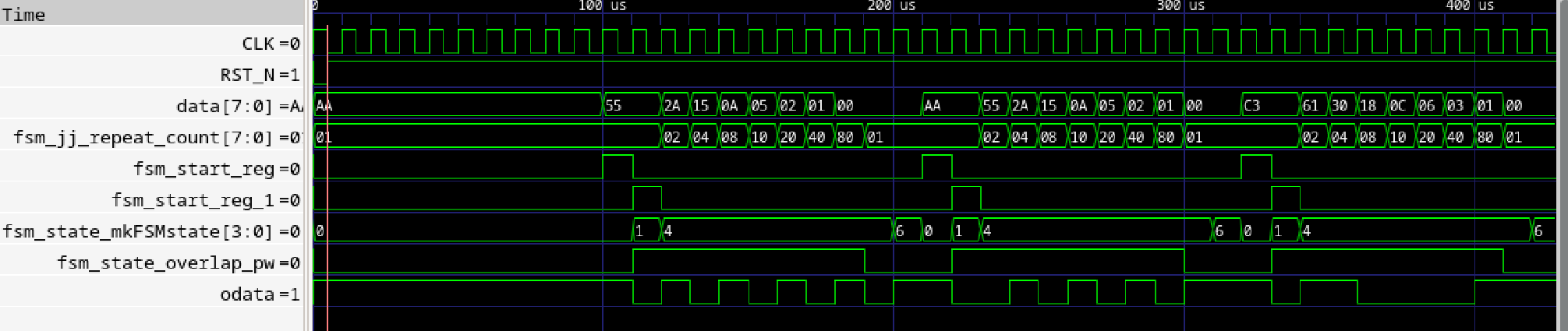
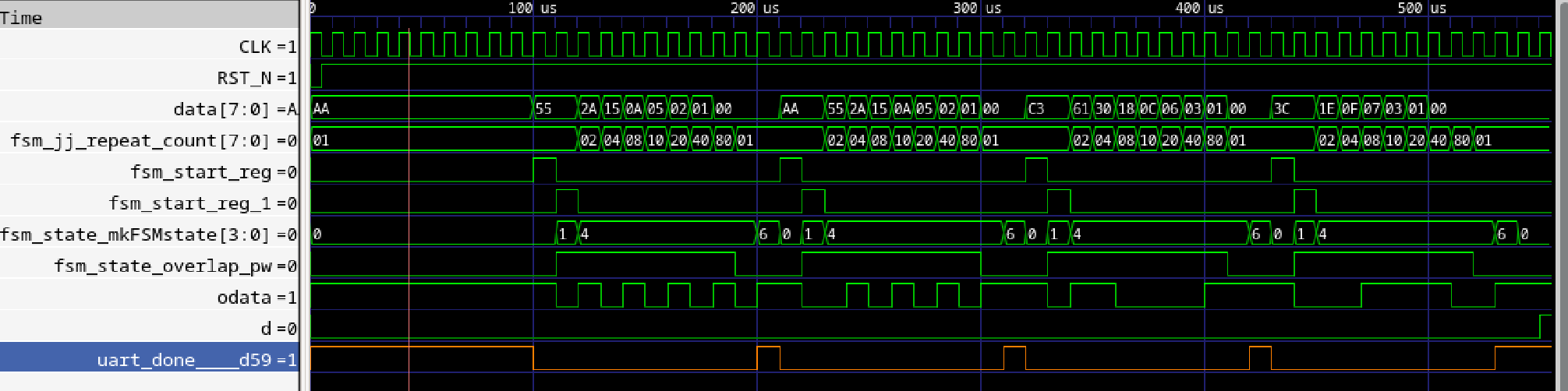
テストベンチ内でレジスタにuart.doneを格納するようにしたら、インタフェースにuart.doneが現れました。awaitで使用するくらいでは削除され、レジスタに取って初めて残すようです。
Verilogシミュレーション
Verilogシミュレーションにおいては、モジュール(mkUart.v)、それをドライブするテストベンチ(mkTb.v)の上位に最上位(top.v)を配備します。これはクロックやリセットを供給するモジュールですが、Bsimの場合はシステムから暗黙にクロックやリセットが供給される一方、Verilogでは供給されないためです。
top.v
`timescale 1ns/1ns
module top();
/*AUTOREGINPUT*/
// Beginning of automatic reg inputs (for undeclared instantiated-module inputs)
reg CLK; // To mkTb_inst of mkTb.v
reg RST_N; // To mkTb_inst of mkTb.v
// End of automatics
/*AUTOWIRE*/
mkTb mkTb_inst(/*AUTOINST*/
// Inputs
.CLK (CLK),
.RST_N (RST_N));
initial begin
RST_N = 1'b0;
#10;
RST_N = 1'b1;
end
initial begin
CLK = 1'b0;
forever begin
#5 CLK = ~CLK;
end
end
initial begin
$dumpfile("verilog.vcd");
$dumpvars;
end
endmodule // top
Verilogシミュレーションのコマンドは次のとおりです。
$ bsc -u -verilog Tb.bsv; iverilog top.v mkTb.v mkUart.v -o ./mkTb.exev; ./mkTb.exev; gtkwave -A verilog.gtkw
Verilogシミュレーションのほうには当然ですが、uart.done信号が存在します。
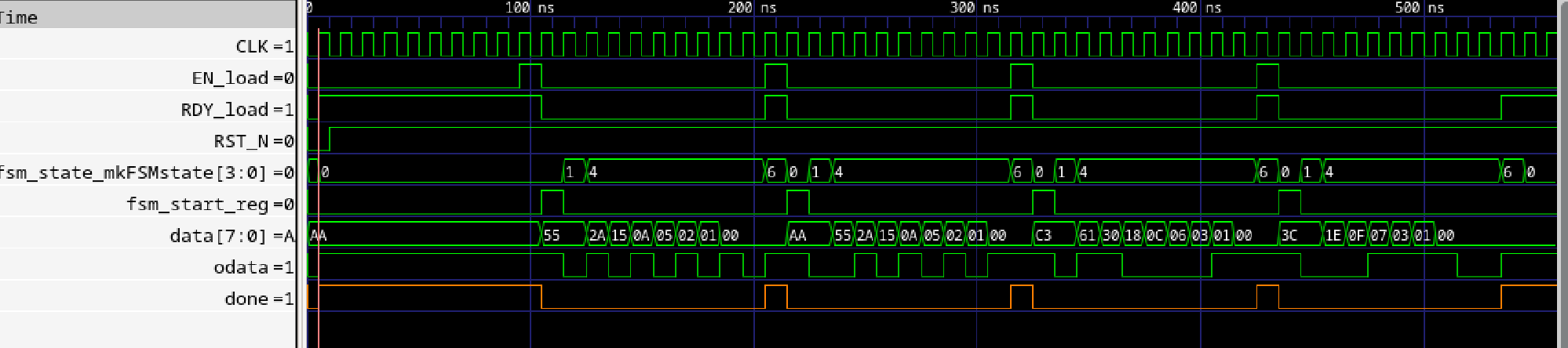
|
19 |
BSVによるUARTの再設計 |
UARTの改良点
過去記事においてUARTを設計しましたが、見直したところ改良点が見つかりました。 改良点はdoneフラグの生成です。実はハンドシェークは自動的にenableとreadyの2線で行われるので、doneが無くても良いのですが、test benchで終了を知りたい場合には必要です。
Uart.bsv
import StmtFSM::*;
interface Uart_ifc;
method Bit#(1) read();
method Action load(Bit#(8) newdata);
method Bool done();
endinterface
(* synthesize, always_ready="read, done" *)
module mkUart(Uart_ifc);
Reg#(Bit#(8)) data <- mkRegU;
Reg#(Bit#(1)) odata <- mkReg(1'h1); // stop bit
Stmt s= seq
odata <= 1'h0; // start bit
repeat (8) action
odata <= data[0];
data <= (data >> 1);
endaction
odata <= 1'h1; // stop bit
endseq;
FSM fsm <- mkFSM(s);
method Bit#(1) read();
return odata;
endmethod
method Bool done();
return fsm.done();
endmethod
method Action load(Bit#(8) newdata);
action
data <= newdata;
fsm.start();
endaction
endmethod
endmodule
この記述のように、従来設けてあったレジスタのdoneフラグを削除し、ステートマシンのdoneを上位に返すことで実現します。さらに、インタフェースのreadとdoneは常にreadyであるため、それらのready信号は不要なので削除しています。
|
16 |
BSVによるSpace Invadersの変更 (4) |
Graphic Controlerの再設計
完成したIP diagramを510.1に示します。3個のサブモジュールをまとめたので、graphic階層はなくなりました。
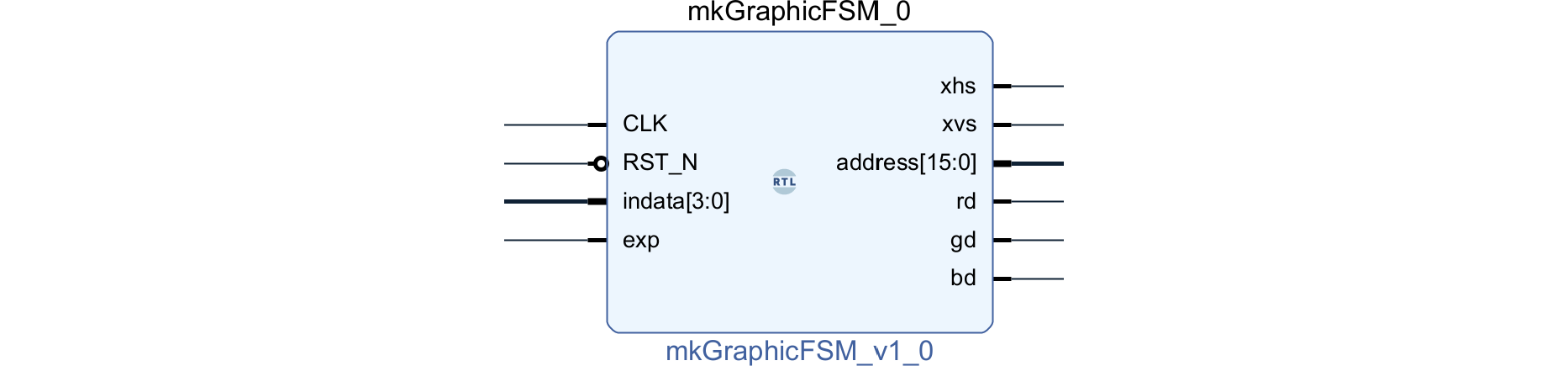
BSVソース
GraphicFSM.bsv:
// グラフィックディスプレイコントローラー、BSVによる実装
import StmtFSM::*;
// 各種タイミングパラメータの定義
`define HD 800 // 水平解像度
`define HFP 16 // 水平フロントポーチ
`define HSP 80 // 水平同期期間
`define HBP 160 // 水平バックポーチ
`define HO `HFP + `HSP + `HBP // 水平オフセット
`define HL `HD + `HO // 一行当たりのピクセル数
`define VD 600 // 垂直解像度
`define VFP 1 // 垂直フロントポーチ
`define VSP 3 // 垂直同期期間
`define VBP 21 // 垂直バックポーチ
`define VO `VFP + `VSP + `VBP // 垂直オフセット
`define VL `VD + `VO // 一画面当たりの行数
// その他の定義
`define EHD 512 // 有効水平解像度
`define EVD 512 // 有効垂直解像度
// ログ幅の定義
`define HW 11 // log2(1056) = 10.04439
`define VW 10 // log2(628) = 9.294621
// アドレス型の定義
typedef Bit#(16) Addr_t;
// インターフェースの定義
interface GraphicFSM_ifc;
method Bool xhs(); // 水平同期信号出力
method Bool xvs(); // 垂直同期信号出力
method Addr_t address(); // VRAMアドレス出力
(* prefix="" *)
method Action idata(Bit#(4) indata); // VRAMデータ入力
(* prefix="" *)
method Action expl(Bool exp); // 爆発入力
method Bit#(1) rd(); // 赤出力
method Bit#(1) gd(); // 緑出力
method Bit#(1) bd(); // 青出力
endinterface
// モジュールの定義
(* synthesize,always_ready,always_enabled *)
module mkGraphicFSM(GraphicFSM_ifc);
Reg#(UInt#(`HW)) x <- mkRegU; // 水平方向のカウンタ
Reg#(UInt#(`VW)) y <- mkRegU; // 垂直方向のカウンタ
Reg#(Bool) in_xhs <- mkReg(False), // 水平同期信号フラグ
in_xvs <- mkReg(False), // 垂直同期信号フラグ
in_hdt <- mkReg(False),
in_vdt <- mkReg(False);
UInt#(`HW) ehoff = (`HD-`EHD)/2;
UInt#(`VW) evoff = (`VD-`EVD)/2;
Reg#(Bit#(4)) in_data <-mkRegU; // VRAMデータ
Reg#(Bool) in_exp <- mkReg(False); // 爆発フラグ
// メインループの定義
Stmt main = seq
while(True) seq
// for (y <= 0; y < `VL; y <= y+1) seq
y <= 0;
while (y < `VL) seq
// for (x <= 0; x < `HL; x <= x+1) action --- for consumes two cycles, then we like to use while
x <= 0;
while (x < `HL) action
if (((`HD+`HFP)<=x)&&(x<(`HD+`HFP+`HSP))) in_xhs <= False;
else in_xhs <= True;
if ((ehoff<=x)&&(x while
y <= y + 1;
endseq // for -> while
$display("%3d %3d", y, x);
endseq // while(True)
endseq; // Stmt // xから水平オフセット(ehoff)を減算してパックし、右に1ビットシフトする。
Bit#(`HW)xx = pack(x-ehoff)>>1;
// yから垂直オフセット(evoff)を減算してパックし、右に1ビットシフトする。
Bit#(`VW)yy = pack(y-evoff)>>1;
// xxとyyを8ビットに切り詰める。
Bit#(8)xxx = truncate(xx);
Bit#(8)yyy = truncate(yy);
// xxxとyyyを合成して16ビットのアドレスを作成。
Bit#(16) in_addr = {yyy, xxx};
// 水平データタイミング(in_hdt)と垂直データタイミング(in_vdt)をANDで合成。
Bool in_dt = in_hdt && in_vdt;
// 爆発フラグ(in_exp)に基づいて赤色成分のデータを処理。
Bit#(1) in_rd = !in_exp ? in_data[2] & pack(in_dt) : (in_data[2] | in_data[1] | in_data[0]) & pack(in_dt);
// 爆発フラグ(in_exp)に基づいて緑色成分のデータを処理。
Bit#(1) in_gd = !in_exp ? in_data[1] & pack(in_dt) : 1'b0;
// 爆発フラグ(in_exp)に基づいて青色成分のデータを処理。
Bit#(1) in_bd = !in_exp ? in_data[0] & pack(in_dt) : 1'b0;
// ステートマシン生成
mkAutoFSM(main);
// メソッド定義
method Bool xhs();
return in_xhs;
endmethod
method Bool xvs();
return in_xvs;
endmethod
method Addr_t address();
return in_addr;
endmethod
method Action idata(Bit#(4) indata);
in_data <= indata;
endmethod
method Action expl(Bool exp);
in_exp <= exp;
endmethod
method Bit#(1) rd();
return in_rd;
endmethod
method Bit#(1) gd();
return in_gd;
endmethod
method Bit#(1) bd();
return in_bd;
endmethod
endmodule: mkGraphicFSM
- actionからendactionまでは1サイクル実行です。
- verilogと同様、"<="はノンブロッキング代入でDFFが、"="はブロッキング代入で組み合わせ回路がそれぞれ生成されます。
当初、水平のオフセットを表す定数EHOFFは、上記のような
UInt#(`HW) ehoff = (`HD-`EHD)/2;
という変数ではなく、define文により
`define EHOFF (`HD-`EHD)/2
のように定義していたのですが、defineの中でカッコや乗除算は使用できないようなので、変数としました。
ところが、生成されたVerilogを確認したところ、bscの最適化により定数となっており、レジスタは存在しませんでした。結論として、マクロで定数定義してもレジスタ宣言しても、オーバヘッドは変わりません。
|
15 |
BSVによるSpace Invadersの変更 (3) |
Graphic Controlerの再設計
引き続き、従来設計ではVerilogで設計していたものを勉強の目的からBSVに置き換えます。Graphic ControllerはVRAMへアドレスを出力し、VRAMデータを読み出し、また水平同期、垂直同期、表示期間等のタイミング信号を作成するモジュールです。
ついでにSVGAのタイミング変更をします。SVGAタイミング(魚拓)によれば、SVGA Signal 800 x 600 @ 75 Hz timingは以下のとおり。
| Screen refresh rate | 75 Hz |
|---|---|
| Vertical refresh | 46.875 kHz |
| Pixel freq. | 49.5 MHz |
- Horizontal timing (line)
| Scanline part | Pixels | Time [µs] |
|---|---|---|
| Visible area | 800 | 16.161616161616 |
| Front porch | 16 | 0.32323232323232 |
| Sync pulse | 80 | 1.6161616161616 |
| Back porch | 160 | 3.2323232323232 |
| Whole line | 1056 | 21.333333333333 |
- Vertical timing (frame)
| Frame part | Lines | Time [ms] |
|---|---|---|
| Visible area | 600 | 12.8 |
| Front porch | 1 | 0.021333333333333 |
| Sync pulse | 3 | 0.064 |
| Back porch | 21 | 0.448 |
| Whole frame | 625 | 13.333333333333 |
Verilogによる設計(過去記事)では、水平カウンタ、垂直カウンタを別々に設け、水平のタイミングデコーダと垂直のタイミングデコーダにより同期信号等を作成していました。また、自機が破壊された場合に全画面を赤色表示にするモジュールを図414.2のように、後段に接続していました。また、VRAMデータ4bitのうちRGBを表す3bitを取り出すために、xisliceモジュールを用いていました。
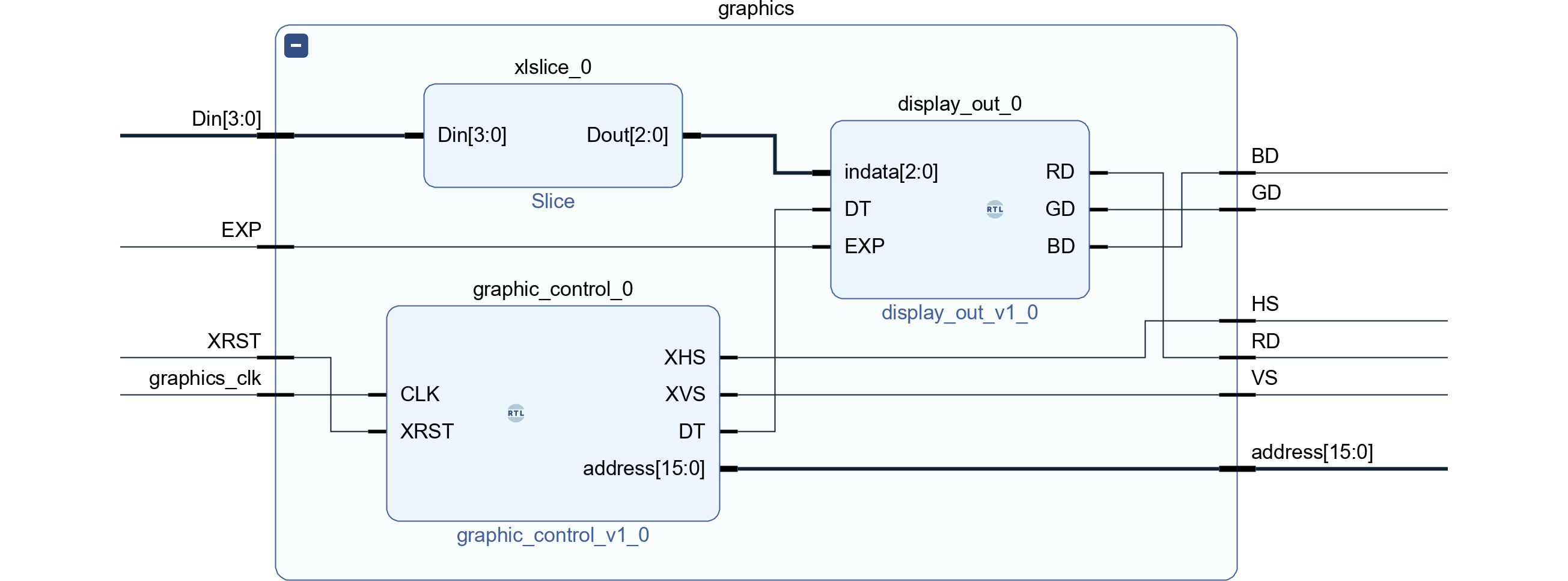
今回BSVで再設計するにあたり、3個に分かれていたモジュール構成を1個にまとめます。
アルゴリズム説明
Graphics.bsvの中心部分:
y <= 0;
while (y < `VL) seq
// for (y <= 0; y < `VL; y <= y+1) seq
x <= 0;
// for (x <= 0; x < `HL; x <= x+1) action --- "for statement" consumes two cycles, so we like to use "while"
while (x < `HL) action
if (((`HD+`HFP) while
y <= y + 1;
endseq // for -> while
このように、y方向とx方向の2次元方向にドットクロックを数えます。コメントされている行のように、本来for文を2重で回したいのですが、資料事例で学ぶ BSVからの引用の図509.1に示すように、Stmt文内のfor文は2サイクルかかることに注意します。

一方、while文は初期化に1サイクルかかるものの、インナーループでのチェックとアクションを1サイクルで実行できます。
for文のインナーループが2サイクルになるということは、2倍の周波数でFSMを駆動しなければならないことになります。現行では49.5MHzなので2倍では99MHzとなり、FPGAの上限に近くなってしまいます。
念のため99MHzで動作するfor文を用いたケースを合成し、正常動作を確認しましたが、タイミングクロージャや発熱等を考えると、回路はなるべく低速で回した方が望ましいです。
一方whileループであればインナーループが1サイクルで良いため、一旦for文で書いてから等価なwhile文に書き換えます。
|
14 |
BSVによるSpace Invadersの変更 (2) |
アルゴリズム説明
アルゴリズムの中心部分を説明します。一度に変換すると、bscによるデータサイズの推定がうまく行かなかったため、ステップに分解してデータタイプのヒントを与えています。ステップに分解しても結局組み合わせ回路が合成されるため、回路オーバヘッドはありません。
Bit#(8) xa = a[15:8];
横方向アドレスであるxaは縦方向アドレス(上位8bit)をそのまま使用します。
Int#(10) yax = 256 - signExtend(unpack(a[7:0]));
一方、縦方向アドレスyaは横方向アドレス(下位8bit)をunpackにより整数化し、符号拡張した上で256から引きます。
Bit#(8) ya = truncate(pack(yax));
その後unpackによりビットベクターとし、最後にtruncateで8bitベクターに戻します。データタイプ変換関数はここに掲載されています。
if (sel) return b;
else if (sw) return {ya, xa};
else return a; // normal state
最後にselがtrueならb(メモリダンプFSMによるアドレス)、falseでswがtrueならxとyの入れ替え&yの反転(90°回転)、falseならオリジナルのa(ゲームFSMによるアドレス)を選択します。
実行結果
図508.1に実行結果を示します。首を左に90度傾けた上で正しく実行できました。

変更後のソース
変更したMux.bsv:
typedef Bit#(16) Addr_t;
interface Mux_ifc;
(* prefix="" *)
method Addr_t outp(Bool sw, Bool sel, Addr_t a, Addr_t b);
endinterface
(* synthesize, always_ready = "outp", no_default_clock, no_default_reset *)
module mkMux(Mux_ifc);
method Addr_t outp(Bool sw, Bool sel, Addr_t a, Addr_t b);
Bit#(8) xa = a[15:8];
Int#(10) yax = 256 - signExtend(unpack(a[7:0]));
Bit#(8) ya = truncate(pack(yax));
if (sel) return b;
else if (sw) return {ya, xa};
else return a; // normal state
endmethod
endmodule
変更箇所はこのアドレスの縦横入れ替えと、VRAM初期値のデータの縦横入れ替えの2点となります。後者はプログラムでも可能ですが、csvに変換した上でexcelのコピーのオプションの行列の入れ替え機能で実施しました。
追記:改良版の記事はここ
ページ:
