|
17 |
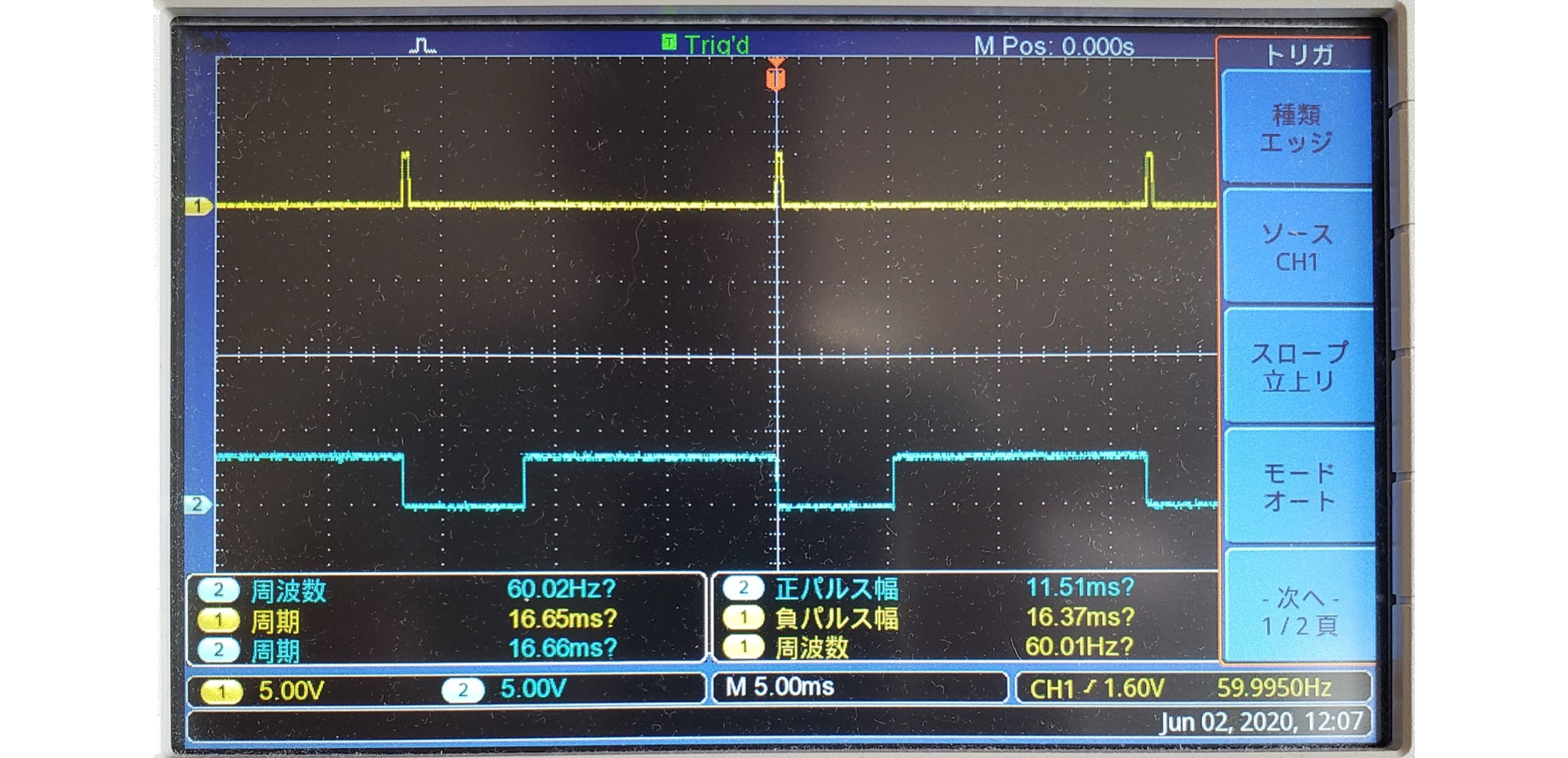
RISC-Vの調査 (6) |
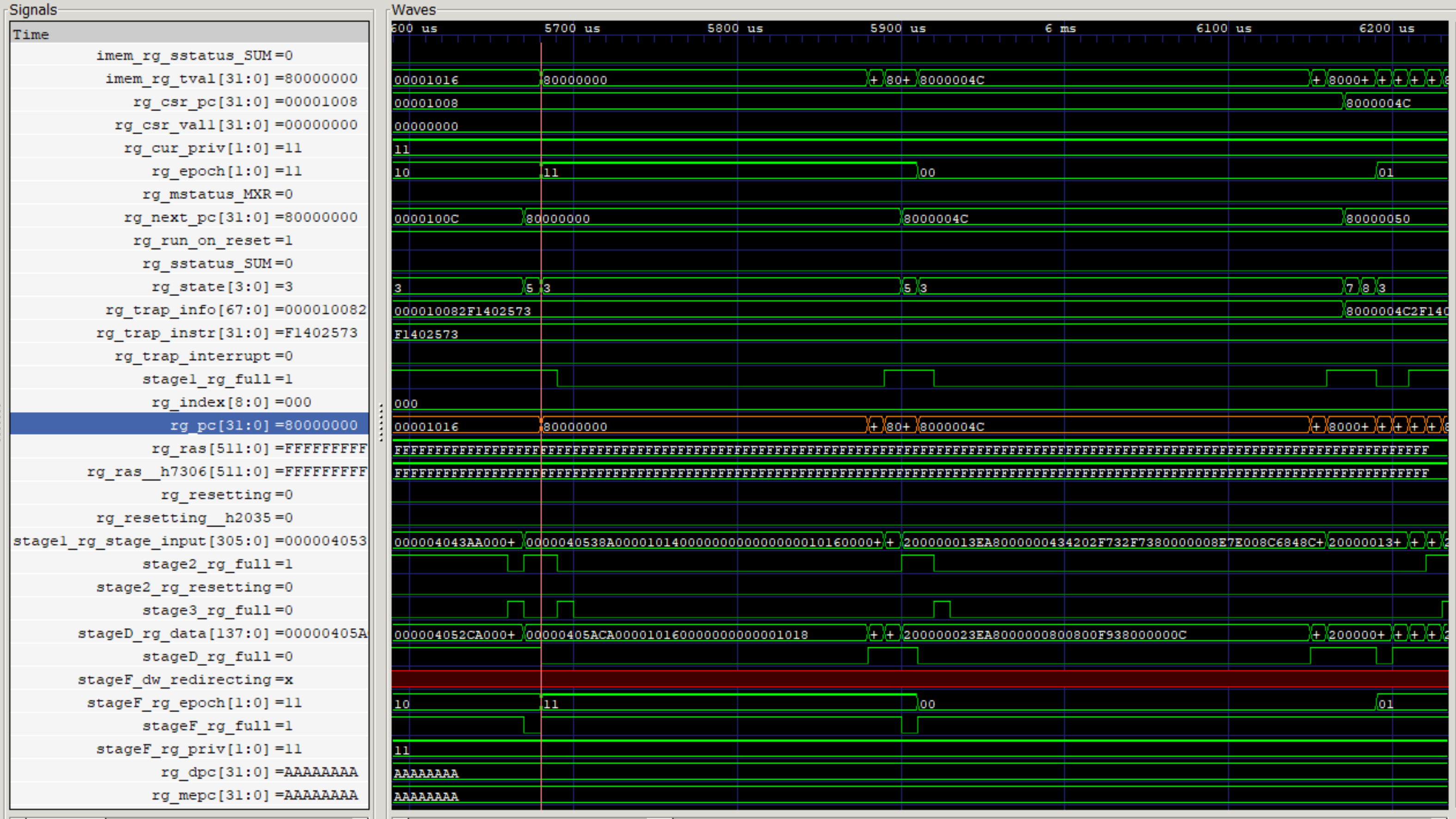
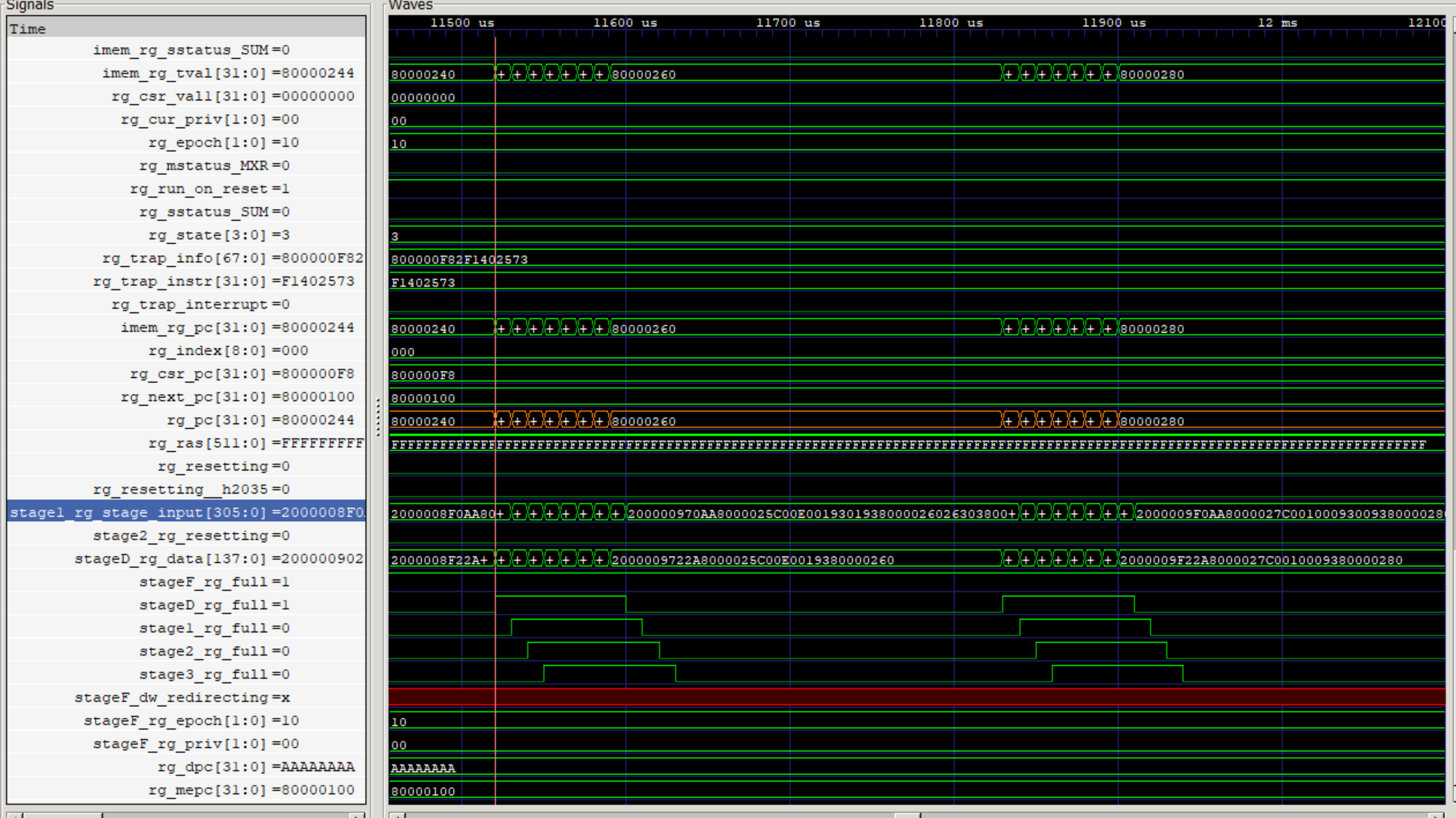
Bsimによるシミュレーション
QemuのシミュレーションからBsimのシミュレーションに切り替えます。ここで、Flute SoCではUARTのアドレスが異なっているため、テストプログラムのUARTアドレスを
<volatile char* UART0_ADDR = (char*)0x10000000;
>volatile char* UART0_ADDR = (char*)0xc0000000;
と変更した上でコンパイルします。
$ riscv32-unknown-elf-gcc -march=rv32i -mabi=ilp32 -nostartfiles -Tlink.lds -Wall -O2 hello.c -o hello.elf
ここで、リンカへの指示であるlink.ldsは以下のようにしています。
OUTPUT_ARCH("riscv")
ENTRY(main)
SECTIONS
{
. = 0x80000000;
.text.startup : { *(.text.startup) }
.text : {
_start = .;
*(.text);
_text_end = .;
exit = .;
}
.rodata : { *(.rodata) }
.sdata : { *(.sdata) }
.bss : { *.(.bss) }
/DISCARD/ : { *(.comment);
*(.riscv.attributes);
*(.strtab*);
*(.shstrtab);
}
. = ALIGN(8);
= . + 0x4000;
sp_top = .;
}
前稿で作成したelfを、Bsimによるシミュレーションが可能なhexファイルに変換します。これはFlute/Tests/elf_to_hex/elf_to_hexで行います。
$ ../Flute/Tests/elf_to_hex/elf_to_hex hello.elf Mem.hex
c_mem_load_elf: hello.elf is a 32-bit ELF file
Section .text.startup : addr 80000000 to addr 8000006c; size 0x 6c (= 108) bytes
Section .sdata : addr 80000068 to addr 80000070; size 0x 8 (= 8) bytes
Section .comment : Ignored
Section .riscv.attributes: Ignored
Section .symtab : Searching for addresses of '_start', 'exit' and 'tohost' symbols
Writing symbols to: symbol_table.txt
No 'exit' label found
No 'tohost' symbol found
Section .strtab : Ignored
Section .shstrtab : Ignored
Min addr: 80000000 (hex)
Max addr: 80000073 (hex)
Writing mem hex to file 'Mem.hex'
Subtracting 0x80000000 base from addresses
作成されたhello.hexの内容は以下のようになっています。逆アセンブルリストと比較して概ね良さそうです。
@0000000 // raw_mem addr; byte addr: 00000000
00c6802306c007130707a68300d7002306500613068006930707a703800007b7 // raw_mem addr 00000000; byte addr 00000000
0707a70300d7002306f006930707a70300e680230707a68300e680230707a683 // raw_mem addr 00000001; byte addr 00000020
000057b706c7a703800007b700e7802300a007130707a78300d7002302100693 // raw_mem addr 00000002; byte addr 00000040
00000000000000000000000010000000001000000000806700f7102355578793 // raw_mem addr 00000003; byte addr 00000060
@07fffff // last raw_mem addr; byte addr: 0fffffe0
000000000000000000000000000000000000000000000000000000000000000 // raw_mem addr 007fffff; byte addr 0fffffe0