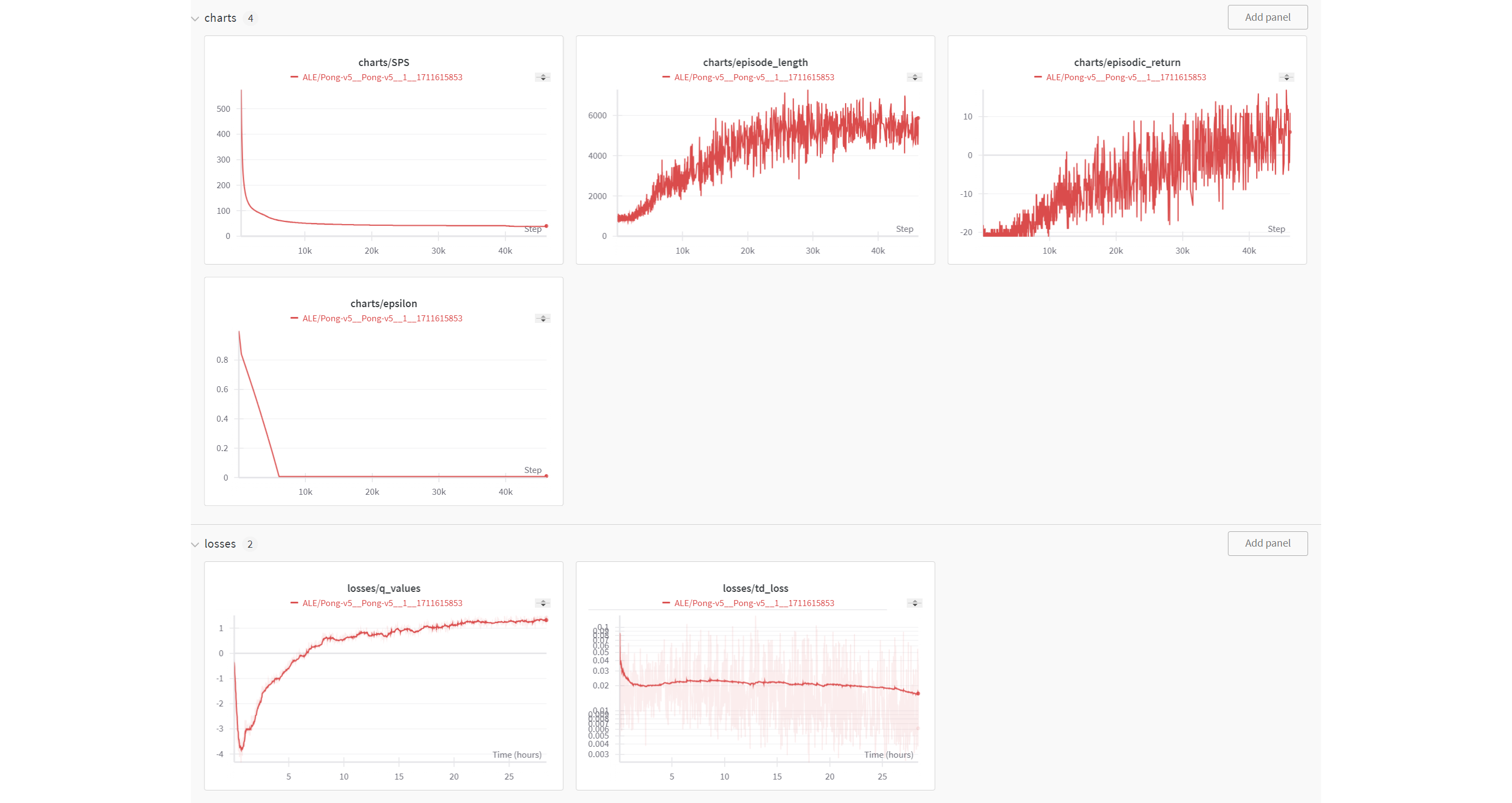
コードの続きの説明です。
このコードブロックは、Deep Q-Network (DQN) アルゴリズムにおけるQ値の更新プロセスの実装部分です。エージェントが十分なステップ数学習した後に、定期的に経験再生バッファからサンプルを取得し、Qネットワークの重みを更新するための損失を計算しています。このプロセスは、エージェントの方策を改善するために重要です。以下に、コードの各部分を詳しく説明します。
コードの詳細解説
1. 学習開始の条件:
if global_step > args.learning_starts:
この条件は、エージェントが一定数のステップ (args.learning_starts) を超えた後にのみ学習プロセスを開始することを保証します。これにより、ランダムな行動から得られる初期データでバッファをある程度満たすことができ、学習の効果を向上させます。
2. 訓練頻度のチェック:
if global_step % args.train_frequency == 0:
エージェントは、指定された頻度 (args.train_frequency) ごとにネットワークを訓練します。この設定により、効率的に計算資源を利用しつつ、定期的な更新を行うことができます。
3. 経験再生バッファからのデータサンプリング:
data = rb.sample(args.batch_size)
経験再生バッファ (rb) からバッチサイズ (args.batch_size) に基づいてデータをランダムにサンプリングします。このサンプリングにより、学習に使用するデータの多様性を保持し、過学習を防ぎます。
4. ターゲットQ値の計算:
with torch.no_grad():
target_max, _ = target_network(data.next_observations).max(dim=1)
td_target = data.rewards.flatten() + args.gamma * target_max * (1 - data.dones.flatten())
torch.no_grad() コンテキストを使用して、勾配計算を行わないでターゲットネットワークを評価します。target_network で次の観測 (data.next_observations) からの最大Q値を取得し、それを使用してTD(Temporal Difference)ターゲットを計算します。この計算には割引率 (args.gamma) と終了フラグ (data.dones) を使用し、エピソードの終了時には将来の報酬がゼロになるようにします。
5. 損失の計算:
old_val = q_network(data.observations).gather(1, data.actions).squeeze()
loss = F.mse_loss(td_target, old_val)
- 現在のQネットワーク (
q_network) を使用して、取得したサンプルの観測から各アクションのQ値を計算し、実際に選択されたアクションに対応するQ値を取り出します。
- TDターゲットと現在のQ値の間の平均二乗誤差(MSE)を計算し、これが訓練プロセスで最小化される損失関数です。
役割と重要性
この学習プロセスは、エージェントが効率的に最適な方策を学習するために重要です。損失関数の最小化により、Qネットワークは正確な行動価値を予測できるようになり、エージェントのパフォーマンスが向上します。経験再生バッファの使用は、サンプルの相関を減少させ、より安定した学習が可能になるため、DQNアルゴリズムにおいて重要な役割を果たします。
 前のブログ
次のブログ
前のブログ
次のブログ