|
17 |
Pipeline processorの設計 (12) |
Posts Tagged with "pipeline processor"
既に発行済みのブログであっても適宜修正・追加することがあります。We may make changes and additions to blogs already published.
|
16 |
Pipeline processorの設計 (11) |
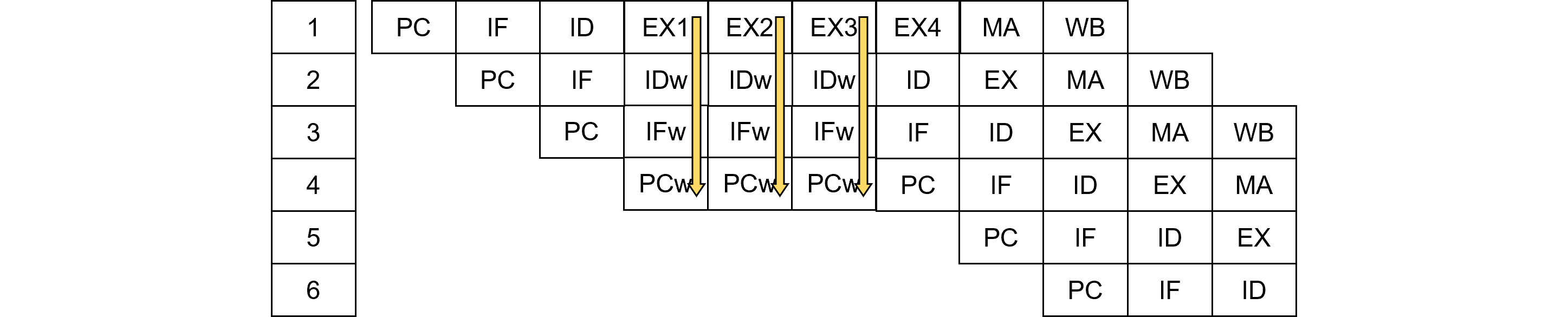
マルチサイクル命令ウエイト
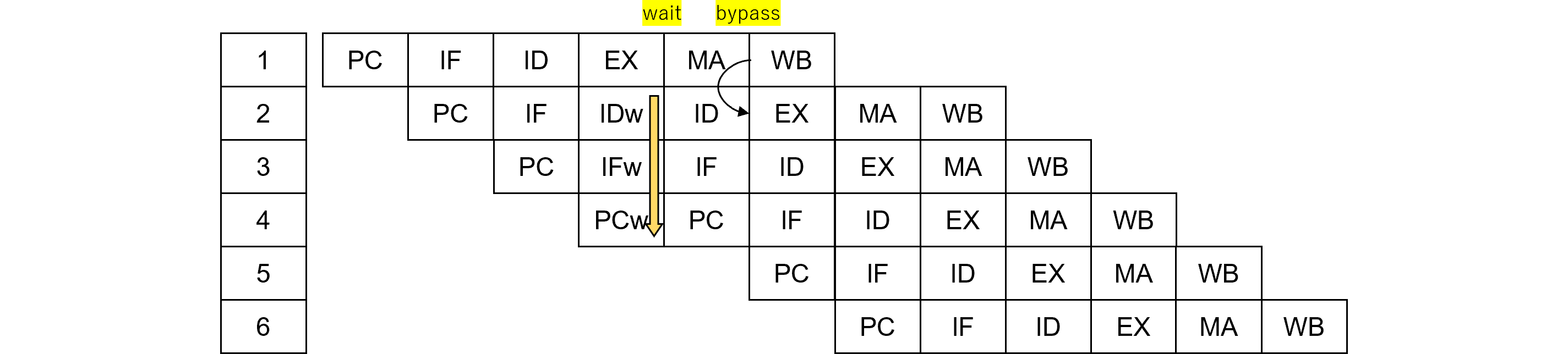
前稿ではマルチサイクル命令ウエイトをご紹介しましたが、パイプライン図を示します。これは例えばRead Modify Write等のように、1命令が1サイクルで終わらない複数ストリームを使用する命令で、いわばCISC命令です。ロード命令、演算命令、ストア命令のRISC命令を並べて実行しないのは、RISC命令だとその間に割り込みが入り、アトミック性が保たれないためです。
黄色は内部的に増殖したサイクルです。
図461.2は図461.1をステージで並び替えたもので、通常のウエイトではパイプライン下段にバブルが発生しますが、マルチサイクル命令ウエイトは例外的に、内部的に命令を発生(増殖)させパイプラインを埋めるので、バブルは発生しません。
|
15 |
Pipeline processorの設計 (10) |
レジスタ干渉ハザード
レジスタ干渉によるハザードは2種類あります。前稿でも触れたWARハザードとロードユースハザードです。
- WARハザード: 前の演算命令のデスティネーションレジスタが後続の命令のソースレジスタと同じ場合にレジスタ干渉ハザードが起きます。しかしながら、レジスタ番号マッチ機構によりバイパスさせ、実質ノーウエイト=ゼロペナルティでパイプライン実行可能です。バイパスパスは<EX>出力⇒<EX>入力です。

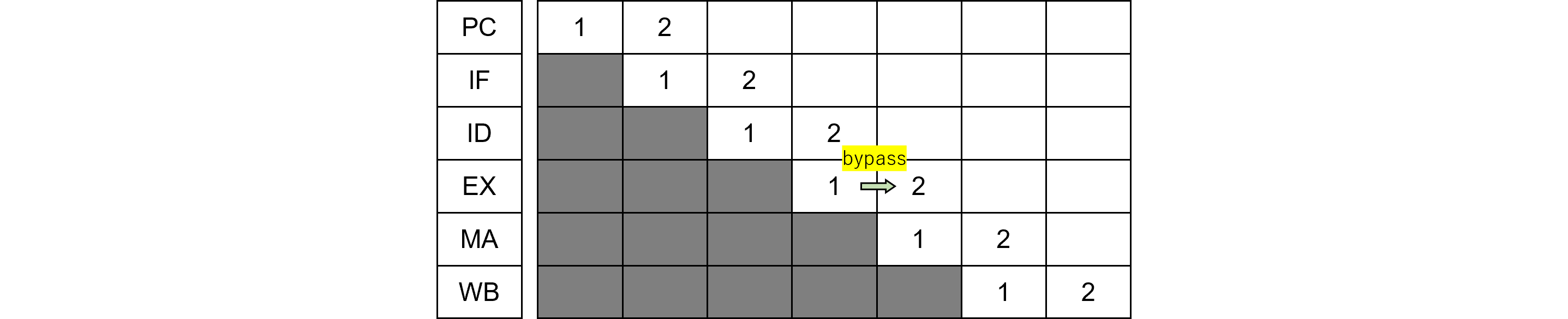
ロードユーズハザード
- ロードユーズハザード: 前のロード命令のデスティネーションレジスタが後続の命令のソースレジスタと同じ場合にロードユーズハザードが起きます。この場合待ち合わせのために1ウェイトが必要であり、かつレジスタ番号マッチ機構によりバイパスさせます。バイパスパスは<MA>出力⇒<EX>入力です。
|
14 |
Pipeline processorの設計 (9) |
パイプラインウエイトの種別
前稿ではパイプラインウエイトの原因を2種類説明しました。ここでステージ毎のパイプラインウエイトの原因をまとめます。
- <PC>: PCの計算にウエイトがかかることは、下段からのウエイトを除きありません。
- <IF>: 命令をメモリからフェッチする際にメモリレイテンシ-1のウエイトが加算されます。これを命令フェッチウエイトと分類します。
- <ID>: 命令デコードにウエイトがかかることはありません。ただしマルチサイクル命令という例外があるので、次項で述べます。
- <EX>: 演算にウエイトがかかる場合はマルチサイクル命令です。上記マルチサイクル命令とはパイプライン制御法が異なるので、併せて次項で述べます。
- <MA>: オペランドメモリのリードライトの際にメモリレイテンシ-1のウエイトが加算されます。これをメモリアクセスウエイトと分類します。
- <WB>: レジスタライトに対してウエイトがかかることはありません。
マルチサイクル命令
前記のように<ID>と<EX>ではマルチサイクル命令ウエイトが発生する可能性があります。
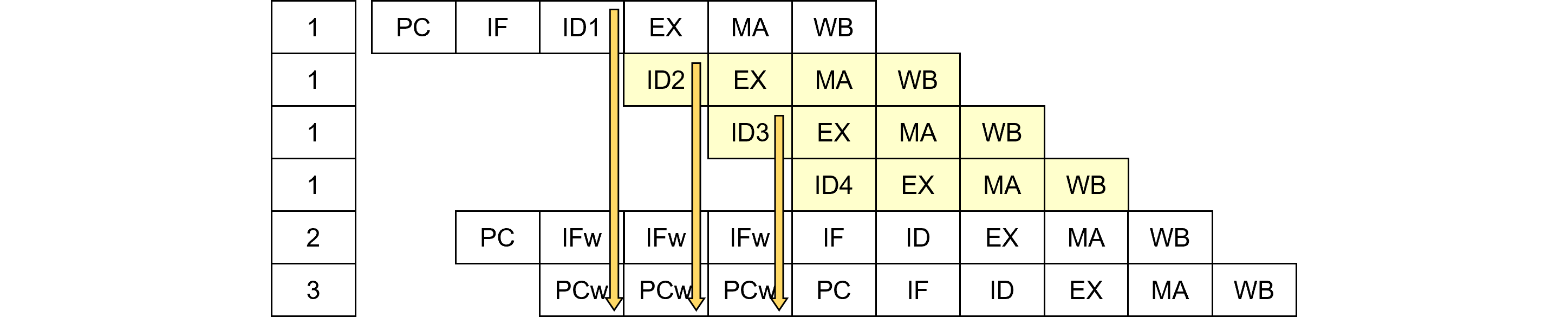
- <ID>: マルチサイクル命令ウエイトと分類します。命令デコードでのマルチサイクル命令は、上段へのウエイト伝搬はパイプラインウエイトと同様、即時に伝えます。一方、下段への無効化を流す操作は行いません。これはあたかも<ID>において命令が内部的に命令ストリームが増殖し、パイプラインを埋めるためです。具体的にはメモリに対するリードモディファイライトがあります。このためには<ID>で動作するステートマシンを起動する必要があります。アーキテクチャにより、無い場合もあります。その理由はCISCっぽい命令となるためです。
- <EX>: マルチサイクル演算ウエイトと分類します。演算にウエイトがかかる場合はマルチサイクル命令ですが、マルチサイクル命令ウエイトと異なり、内部的にパイプラインが増殖することはないため、通常のウエイト制御と同じパイプライン制御を行います。例えば乗算命令に関して32bit×32bitの乗算器を用意すると面積が大きくなるので、32bit×8bitの乗算器を4サイクル回す場合等です。
|
11 |
Pipeline processorの設計 (8) |
命令フェッチウエイト
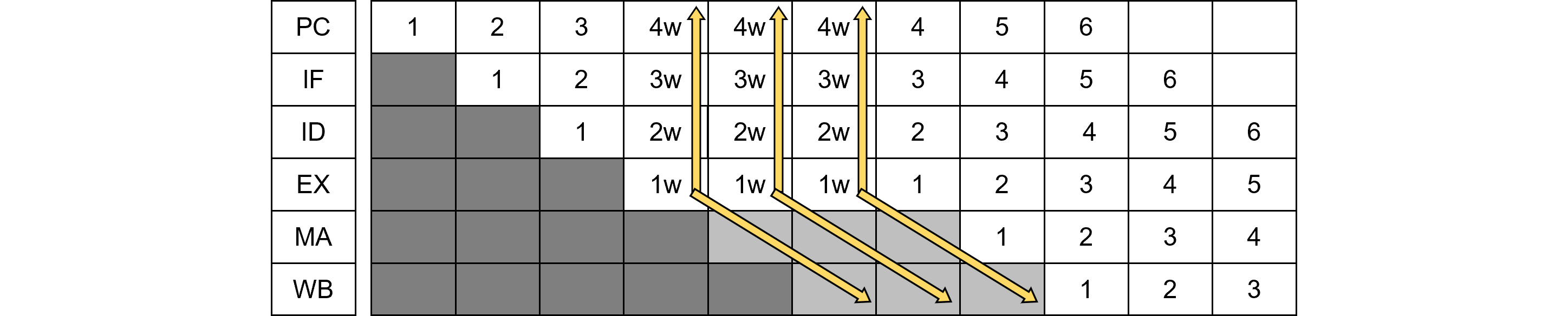
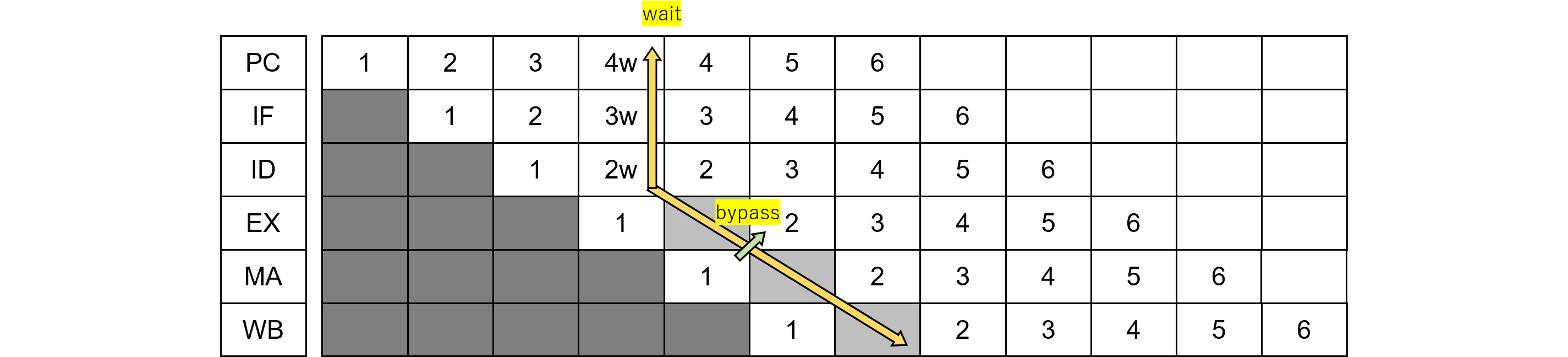
次に命令フェッチ時に2ウエイトがかかった場合のタイミングを示します。

命令1の<IF>にウエイトが入ると、後続命令を直ちに止める必要があるため、前稿と同様、ウエイト信号は即時に上ステージに伝える(下向き矢印)ように制御します。
図458.2はそれを並べ替えたものです。メリットは図458.1では省略されているパイプラインバブルが見えることです。濃いグレーは初期の無効フラグであり、パイプラインバブルは薄いグレーで示しています。

パイプラインウエイトは上段に向かって即時(同一サイクル内)に流す(上向き矢印)だけでなく、下段に向かってバブルを発生します(右下斜矢印)。下段へは即時ではなくパイプラインに沿って流します。
実装は<IF>で起動するFSMにより実装します。例えば命令キャッシュをFSMで構成すると、キャッシュヒット時は1サイクルで結果が返りますが、キャッシュミス時は複数サイクルのFSMにより、命令がフェッチされます。
|
10 |
Pipeline processorの設計 (7) |
パイプラインウエイト
パイプラインの設計も佳境となるのがパイプラインハザードであり、それを実行するのがパイプラインウエイト制御です。本来ウエイトさせるべきタイミングでウエイトされないと、「パイプラインステージが滑る」バグとなります。
パイプラインステージ制御には原則があり、パイプラインステージは増殖してはいけません。パイプラインステージを止める場合は、その出力の更新を止めることでサイクルを繰り返す制御を行い、かつ、後段には無効信号を流す必要があります。
つまり、パイプラインステージ制御信号にはValid信号が必要です。一方パイプラインデータ信号にはValid信号は不要です。パイプラインで無効データが流れても、最後の<WB>で書き込まなければ問題ないためです。
メモリアクセスウエイト
次にロードストア命令の<MA>でのウエイトの場合を示します。
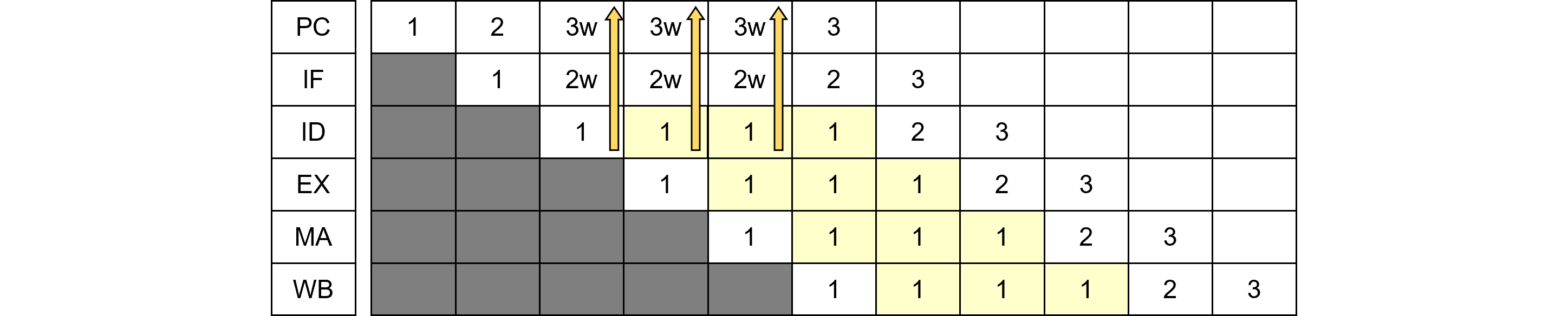
通常のパイプライン図を457.1に示します。命令の実行順に、縦に命令を1, 2, ..., 6と並べています。横軸は時間軸で、箱の中にステージ名が書かれています。命令処理を命令流すなわち、命令ストリームあるいはパイプラインストリームと呼ぶこともあります。

図457.1は例えば命令1のメモリアクセスステージ<MA>でメモリウエイトが2サイクル入った場合の例です。命令1の<MA>にウエイトが入ると、後続命令を直ちに止める必要があるため、ウエイト信号は即時に上ステージに伝える(下向き矢印)ように制御します。
図457.1をパイプラインステージ順に並べ替えたものが図457.2です。図457.1と同様に横軸は時間軸です。箱の中には命令の順番の番号が入っています。こちらのほうが有利なのは、図457.1では省略されているパイプラインバブルが見えることです。バブルは薄いグレーで示しています。初期の無効状態は濃いグレーで示しています。

パイプラインウエイトは上段に向かって即時(同一サイクル内)に流す(上向き矢印)だけでなく、下段に向かってバブルを発生します(右下斜め矢印)。下段へは即時ではなくパイプラインに沿って流します。バブルとは、具体的にはパイプラインのValid信号をインバリデート(無効, false)にすることです。
例えば1の命令が<MA>でウエイトする場合(5クロック目)、パイプラインを下段方向に止めるのではなく、下段は止めずにその代わり無効信号を流します。これは重要なパイプライン制御のテクニックであり、下段も止めてしまうと、誤ったインターロック(お互いに止めあうこと)が発生することがあります。
余談ですが、20?年前に課内でパイプライン制御を説明したとき、先輩のTさんと後輩のK君は「全部止めたらいいんじゃないか」と言いましたが、上記の理由からそれは誤っています。
実装は<MA>で起動するFSMにより実装します。例えばデータキャッシュをFSMで構成すると、キャッシュヒット時は1サイクルでデータが返りますが、キャッシュミス時は複数サイクルのFSMによりデータがフェッチされます。
|
9 |
Pipeline processorの設計 (6) |
レジスタフォワーディング
レジスタフォワーディングは単にフォワーディング、またはバイパスと呼ばれることがあります。これは前述のRAWハザードのペナルティ(無駄時間、バブル)を軽減もしくは無化するためのものです。
以下のような命令ストリームがあった時、
1: <PC><IF><ID><EX><MA><WB> 2: <PC><IF><ID><EX><MA><WB> 3: <PC><IF><ID><EX><MA><WB> 4: <PC><IF><ID><EX><MA><WB> 5: <PC><IF><ID><EX><MA><WB>
1:のデスティネーションレジスタは<WB>ステージで書き込まれますが、直後の2の命令ストリームの<ID>で読もうとすると、5の命令のタイミングまでウエイトしなければなりません。つまり2、3、4の命令実行時間の$3\tau$が無駄になります。
これを高速化するのがレジスタフォワーディングで、2の命令デコード時に先行命令のデスティネーションレジスタ番号と自分の命令のソースレジスタ番号の比較を行います。この時同じレジスタであれば、デスティネーションレジスタから読み出すのではなく、演算器の出力をレジスタの結果とみなします。1の命令の<EX>の出力確定は2の命令の<ID>のレジスタ読み出しと同一タイミングなので、レジスタフォワーディング制御としては<EX>の出力を<EX>の入力にフィードバックします。
このバイパス機構を設けることで、本来$3\tau$のバブルが発生するところをバブル無しとなり、RAWハザードを解消することができます。
機構的にはソースレジスタとデスティネーションレジスタの番号をパイプラインで流し、番号が前後の命令で一致するかを見る比較器を設け、一致した場合は命令コードが示すレジスタの内容ではなく、演算器の出力パスをマルチプレクサで選択します。
|
8 |
Pipeline processorの設計 (5) |
パイプラインステージ
プロセッサに話を戻して、一連の処理を複数のパイプラインステージに分解します。一般的にみられるのは、 ステージを<>で表示する約束として、
- <IF>: 命令フェッチステージ
- <ID>: 命令デコード, レジスタリードステージ
- <EX>: 演算ステージ
- <MA>: メモリアクセスステージ
- <WB>: ライトバックステージ
の5段に分割するものです。
このような5段のパイプラインの説明が一般的ですが、いきなり命令フェッチすることはできないので、実は<IF>の前段にはプログラムカウンタ演算の
- <PC>: PC演算ステージ
が必要になります。<PC>の前はといえば、それはその前の<PC>なので、パイプラインの開始はやはり<PC>からです。命令パイプラインなのでプログラムカウンタが原点です。
従って、<PC><IF><ID><EX><MA><WB>の6段ステージと考えるほうが考えやすいです。
1: <PC><IF><ID><EX><MA><WB> 2: <PC><IF><ID><EX><MA><WB> 3: <PC><IF><ID><EX><MA><WB> 4: <PC><IF><ID><EX><MA><WB>
各命令の<PC>は通常PCの+4インクリメントを実行します。ここで1の命令が無条件相対分岐命令だった時、分岐命令とオフセットが判明するのが1の<ID>の最後です。従って、それからPC計算を実行すれば、分岐先は4の命令ストリームとなります。
マイクロアーキテクチャによっては、IFの中でPC計算を実施する場合もあります。その場合は<PC>は<IF>に隠蔽され5段パイプラインとなります。このあたりは、マイクロアーキテクチャの考え方で、32bitの加算に$1\tau$かかるのであれば、<PC>も$1\tau$かかるのが妥当ということになります。
投機的実行
従って1の分岐命令は3サイクル命令となります。つまり1の分岐命令のレイテンシは$3\tau$となってしまうので、裏技的な手法を使います。それは、1の命令を<IF>でフェッチしたら、次の<ID>のデコードと同時に投機的に分岐命令だと思って分岐先を計算します。こうすれば分岐先は3の命令から始めることができ、分岐命令のレイテンシは$2\tau$となります。この場合、ほとんどは分岐命令でないので、その場合は<PC>で実行した投機的な実行結果を捨てます。
<PC>では本来次の命令アドレスであるPC+4か、または分岐命令の場合はPC+オフセットのいずれかを計算すれば良いのですが、このように、常に両方計算することで高速化を図ります。
パイプラインプロセッサにはこのような投機的な(ある意味無駄な)実行は良く使われ、例えばレジスタリードも同様です。<ID>でリードするのですが、本来はレジスタ演算命令の場合だけリードすれば良く、レジスタをリードしない命令でレジスタをリードする必要はありません。
投機的実行の場合は<ID>と同時にレジスタリードを行い、<ID>の完了後に不要だった場合は実行結果を捨てます。このためにレジスタリードのための命令のビットフィールドは固定されています。
|
7 |
Pipeline processorの設計 (4) |
プロセッサパイプライン
本稿ではコンピュータの設計が主題なので、社内メール処理ではなく、プロセッサパイプラインについて解説します。プロセッサの命令にはRISC形式、CISC形式が存在しますが、ここではRISC形式を取り上げます。
RISCとCISC
このRISC/CISCの別は、実はパイプライン構造から発しており、パイプラインステージ中にメモリアクセスが1回のものをRISC、2回以上のものをCISCと呼びます。元々はメモリ上のデータを書き換えるのがプロセッサの役目なので、CISCが先に発明されたのですが、パイプライン化を考えた場合にパイプラインステージ中に複数のメモリアクセスステージが存在すると、パイプラインハザードが起こりやすくなるのが欠点でした。
これに対して演算をレジスタに限り、メモリアクセスをロードストアのみに限定したのがRISCです。パイプラインステージ中にメモリアクセスが1か所で固定されているため、メモリアクセスにはRAWハザードがありません。レジスタのRAWハザードのみを考慮すれば良いことになります。
RISCのメリット・デメリット
RISCのメリットは種々あり、
- 32bit固定長命令によるデコードの簡略化
- レジスタフィールドの固定により、デコードせずにソースレジスタの読み出しが可能
- 複雑な命令の排除による命令デコーダの高速化
等がありますが、その根本はメモリ演算の廃止によるものです。メモリアクセスはロードストアのみと割り切り、演算はレジスタを対象とすることでパイプライン制御を単純化し、上記の特徴も併せて高速化が可能となりました。
一方で命令長が32bit固定でかつ複雑な命令を単純な命令の組み合わせで実行することから、命令コード効率はあまり良くありません。ワークステーション等では問題なかったこの欠点は、16/32bit混合の導入により組み込み向けの応用では改善が行われています。
|
4 |
Pipeline processorの設計 (3) |
パイプラインハザード
それでは100段でも1,000段でも細かく切れば性能は100倍、1,000倍になるかというと、そう単純には行きません。それには複数の理由があります。
- パイプラインステージは同じレイテンシ$\tau$である必要がある。
- ステージ間の箱(パイプラインレジスタ)によるレイテンシ($\alpha$)が増加する
- パイプラインハザードの存在により、性能向上できない
ひとつの大きな処理の中を均等に細かい時間間隔の$\tau$で切るのは、ハードウエア構成上限界があります。また、パイプラインレジスタのレイテンシの追加は、性能低下原因となります。最後にパイプラインハザードの存在により、後続ステージの待ち合わせが発生し、パイプライン中に隙間(バブル)が生まれます。これも性能低下原因となります。
RAWハザード
パイプラインハザードのひとつにRAW(Read After Write)ハザードがあります。これは、パイプラインステージの前半、例えばAの処理において使用する封筒に、Cの処理において投函される封筒が必要だったとします。すると、処理としてはCが終了しないとAが開始できませんが、パイプラインステージ中ではAのほうが先になっているので、図453.1の左のようには2番目の処理が開始できず、図453.1の右のように、$2\tau$のバブル(=無駄サイクル)が発生してしまいます。これをパイプラインハザードと呼びます。

ページ:
