|
26 |
PICによるLEDドライバボードの設計 |
Studio 500 3D Pop Up Wall Artの修理をすることになりました。LEDが点滅しなくなったので、点滅回路を作成します。

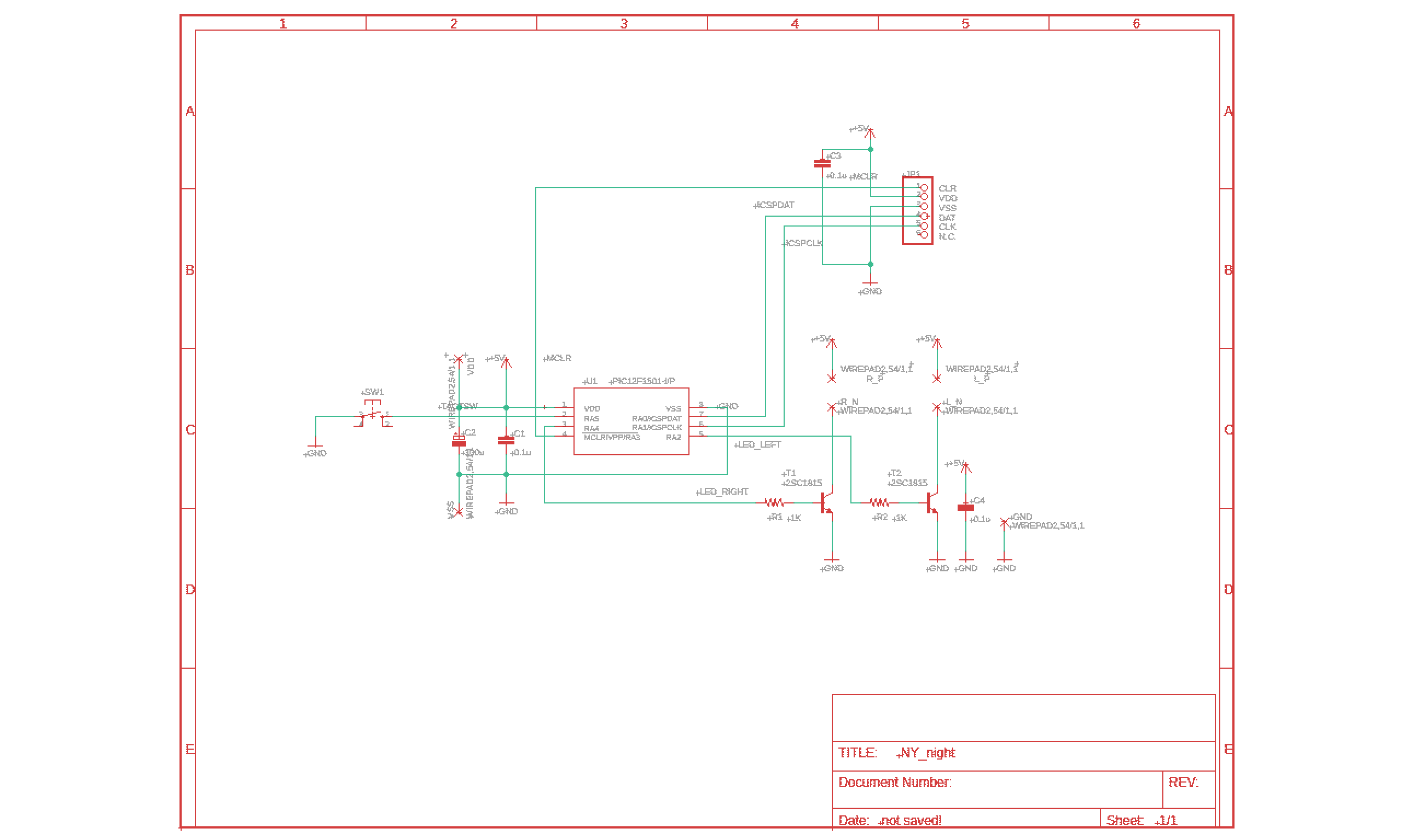
まずPICを用いて点滅シーケンスを再現します。EAGLEで作成した回路図は以下のようになります。上部のコネクタはin-circuitでPICプログラミングするためのコネクタです。
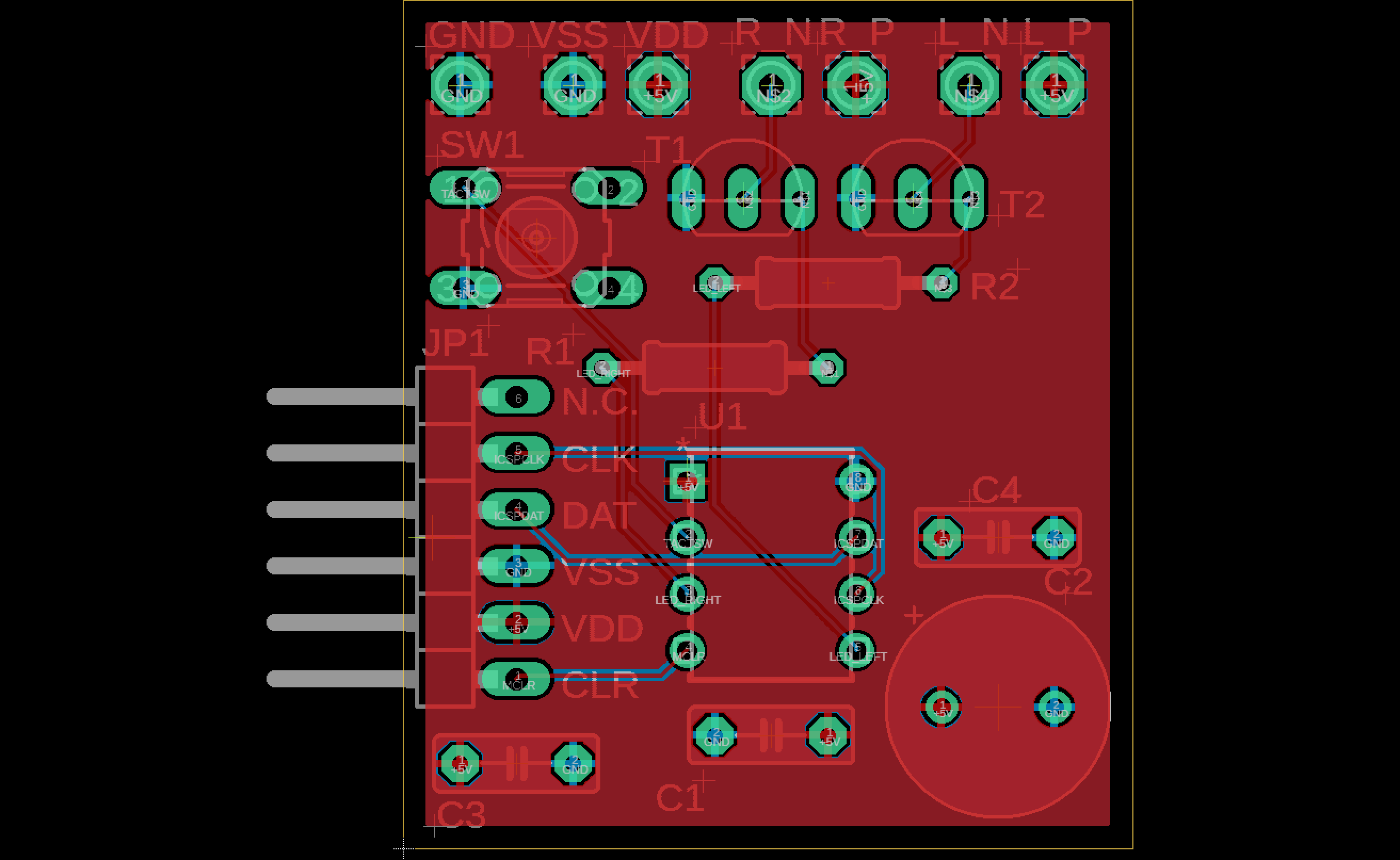
以下にレイアウト図を示します。
|
26 |
PICによるLEDドライバボードの設計 |
Studio 500 3D Pop Up Wall Artの修理をすることになりました。LEDが点滅しなくなったので、点滅回路を作成します。
まずPICを用いて点滅シーケンスを再現します。EAGLEで作成した回路図は以下のようになります。上部のコネクタはin-circuitでPICプログラミングするためのコネクタです。
以下にレイアウト図を示します。
