|
10 |
RISC-Vプロセッサの設計 (30) |
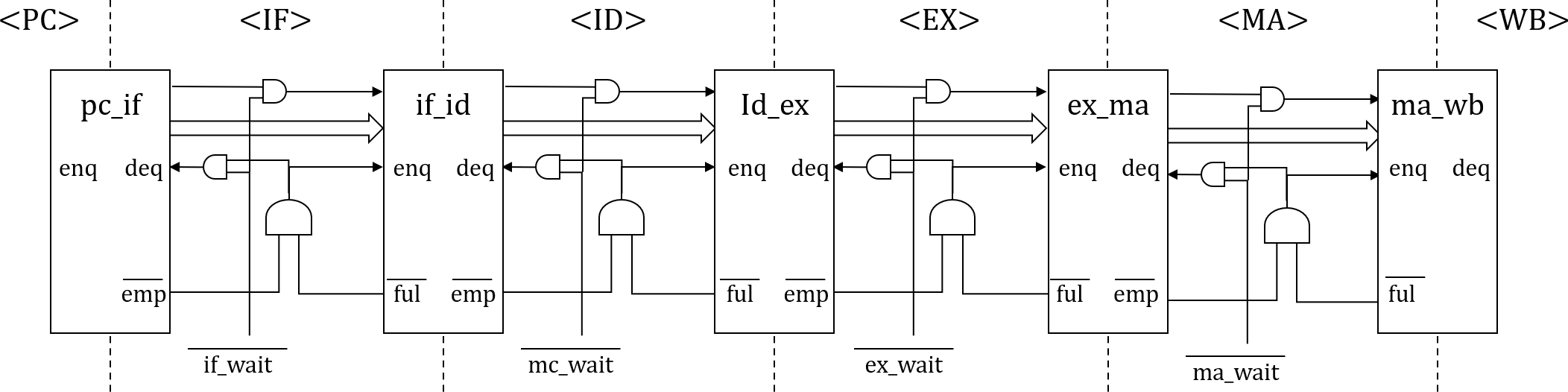
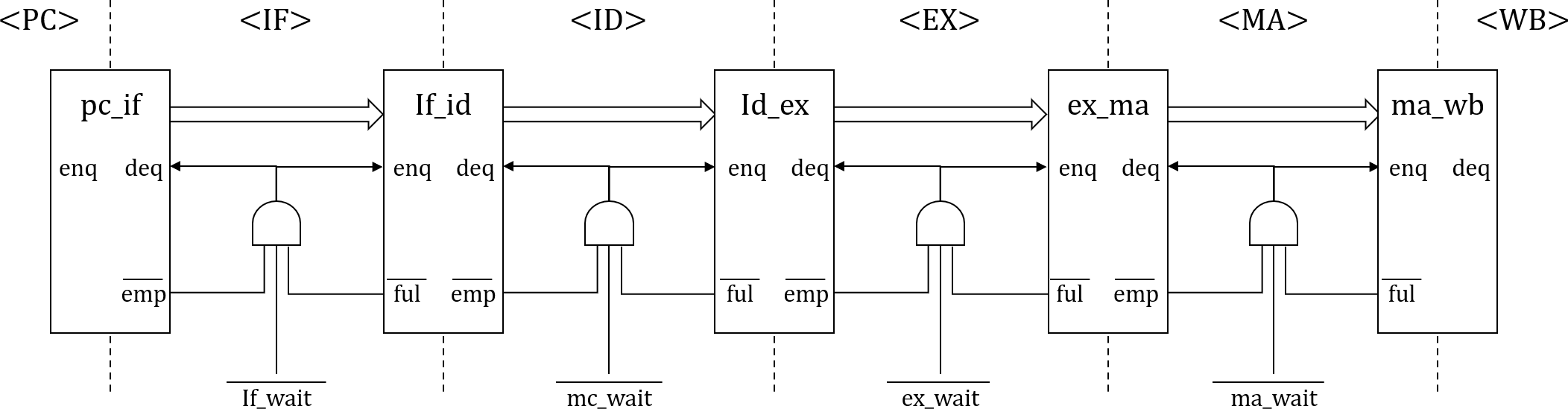
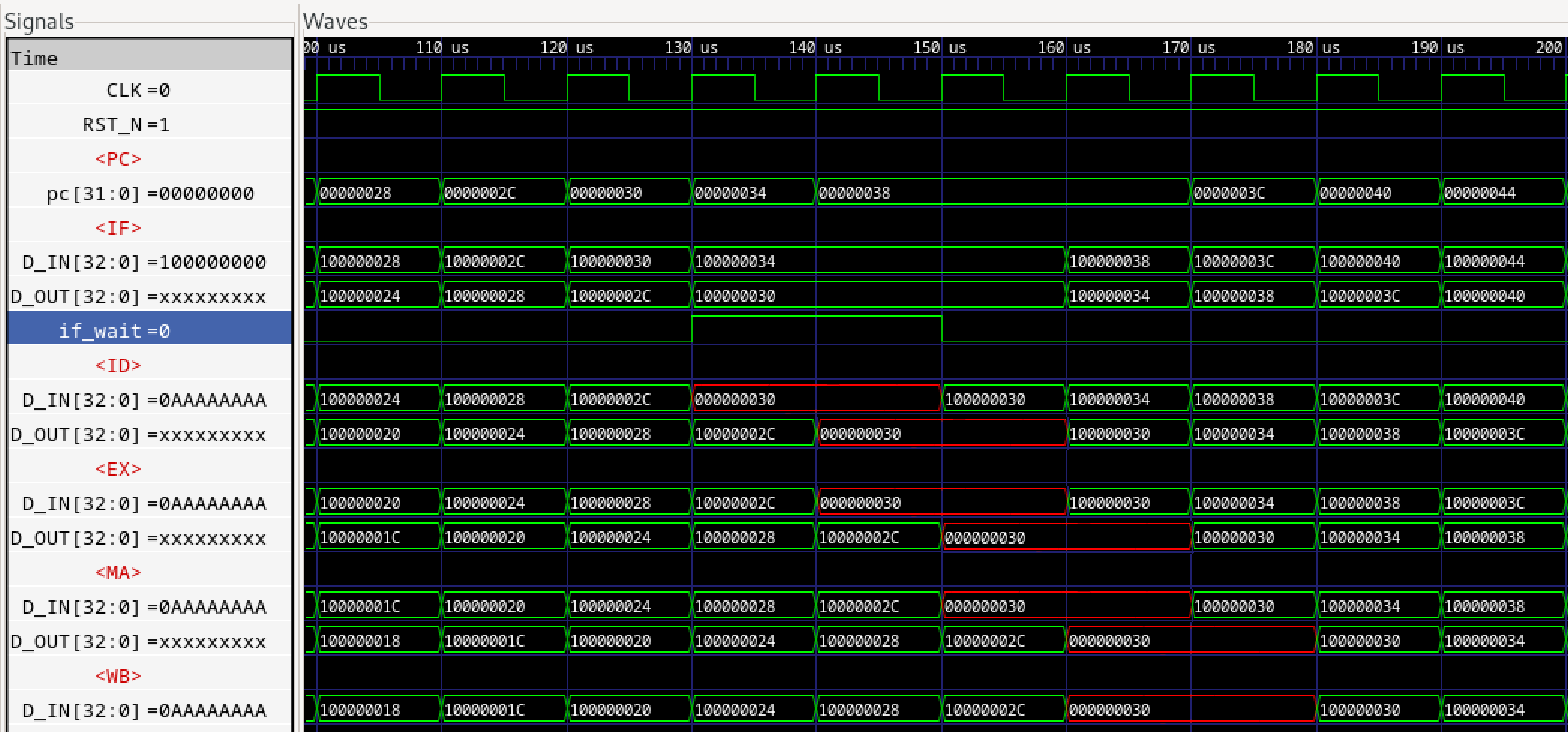
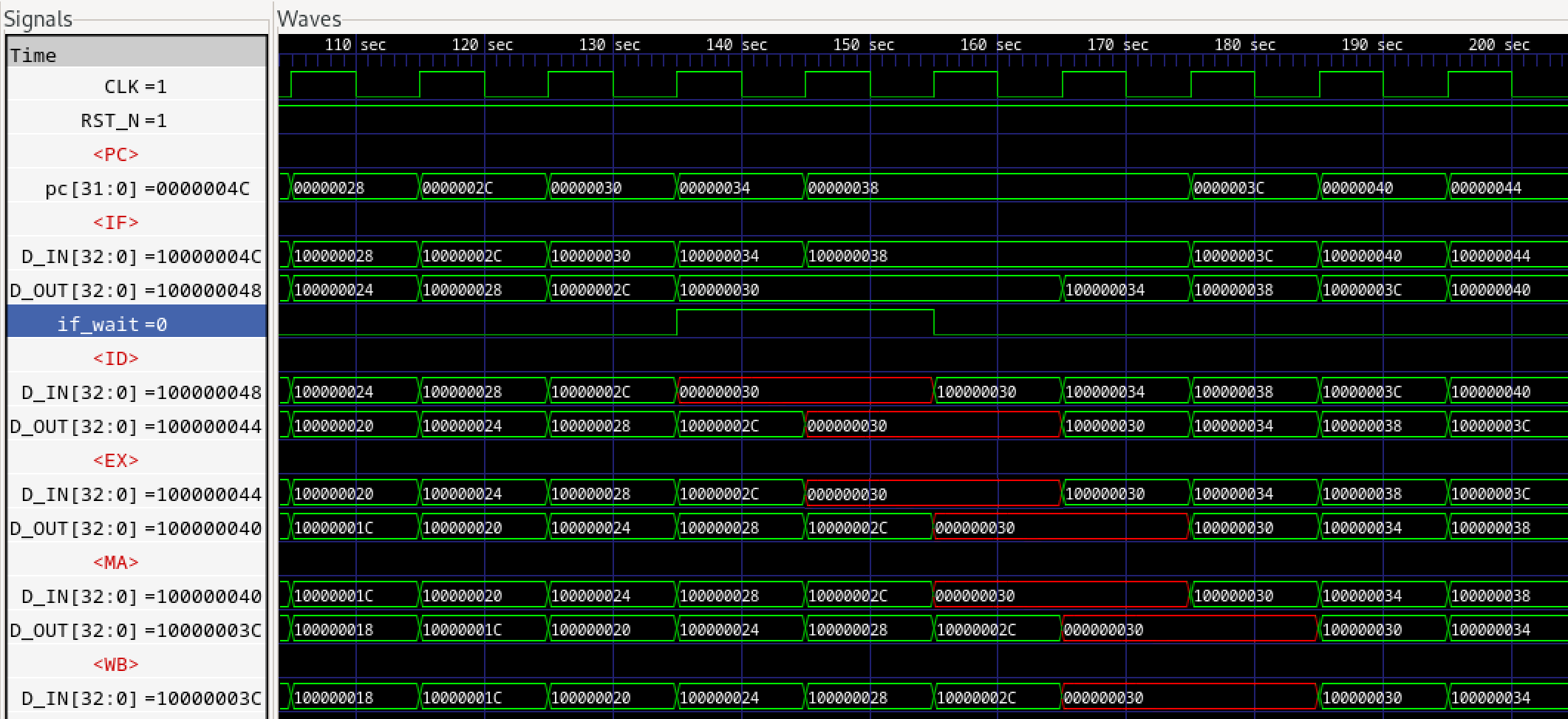
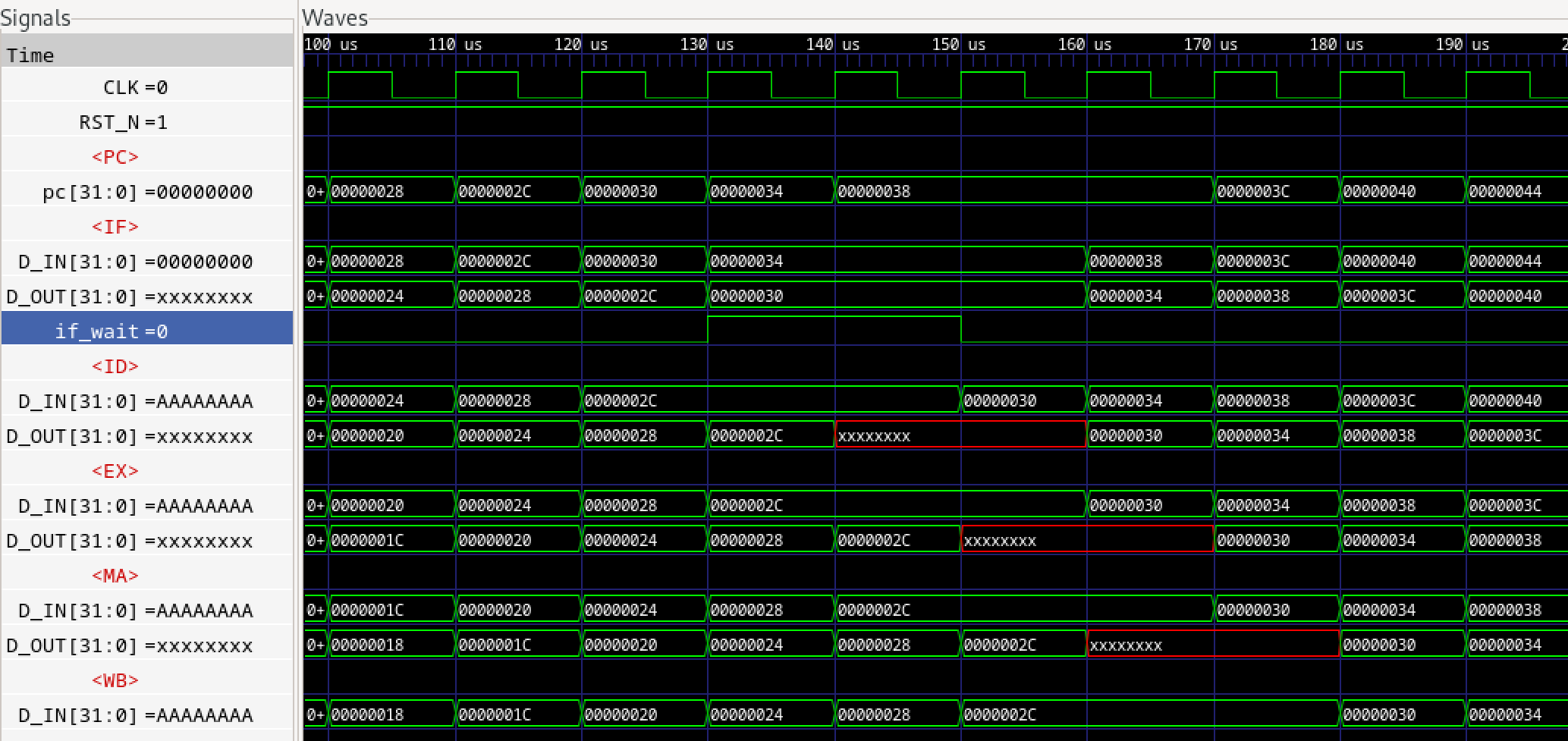
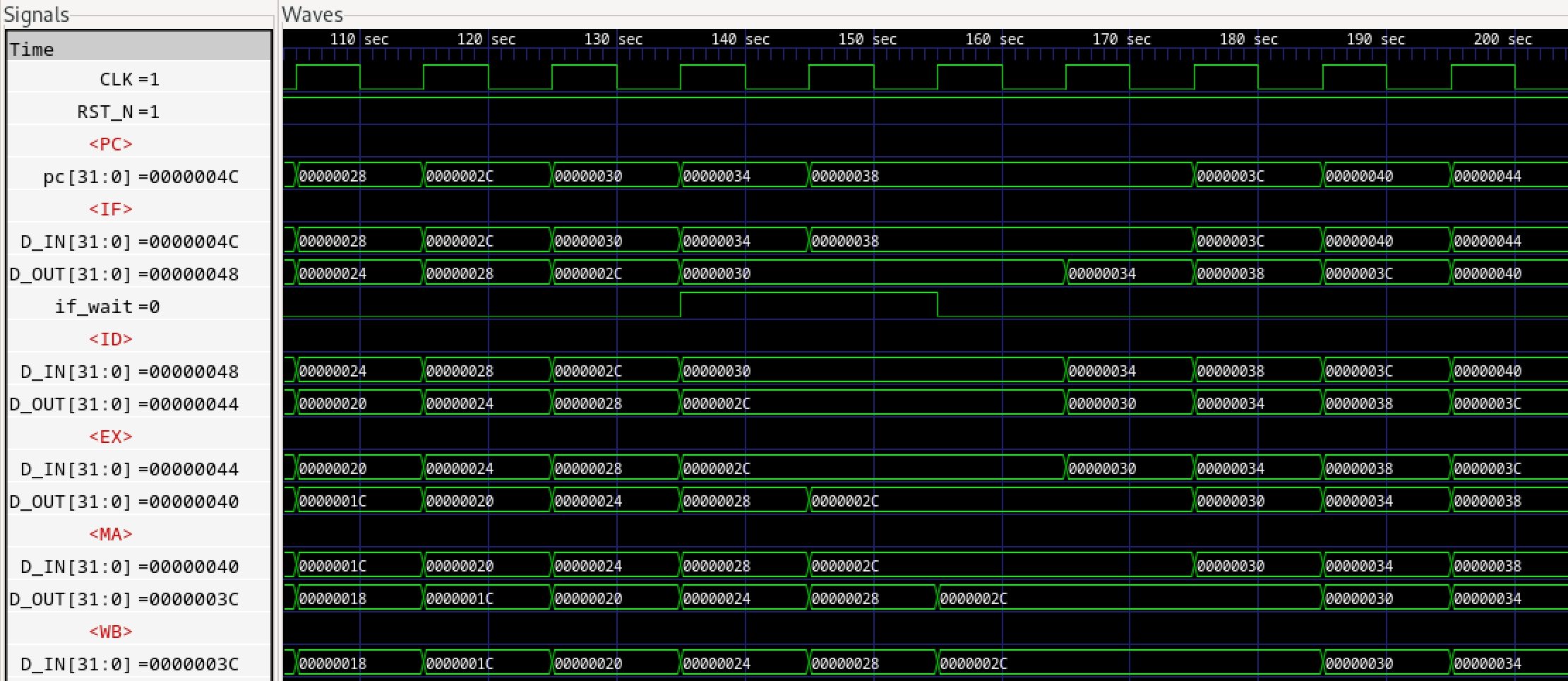
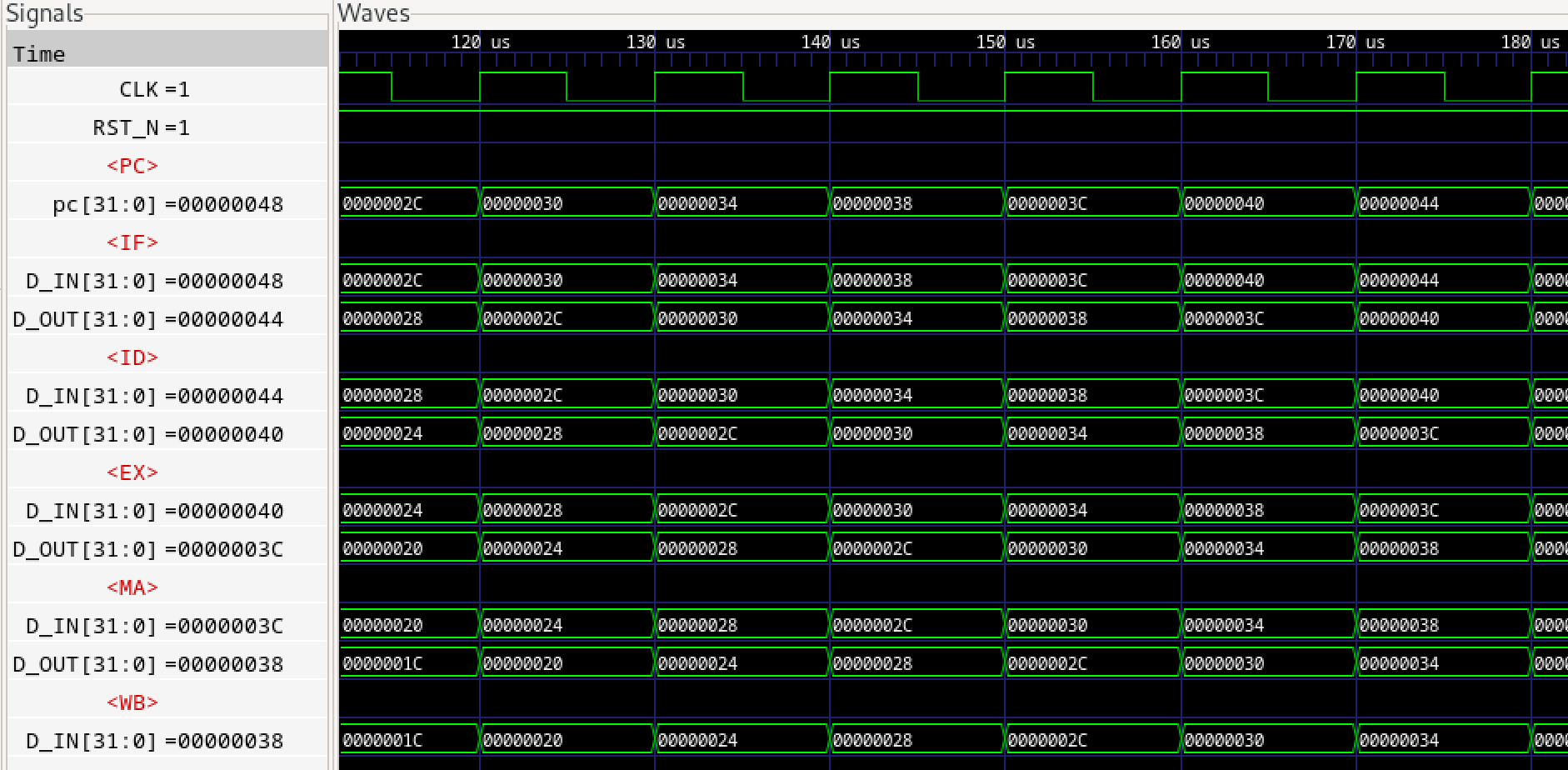
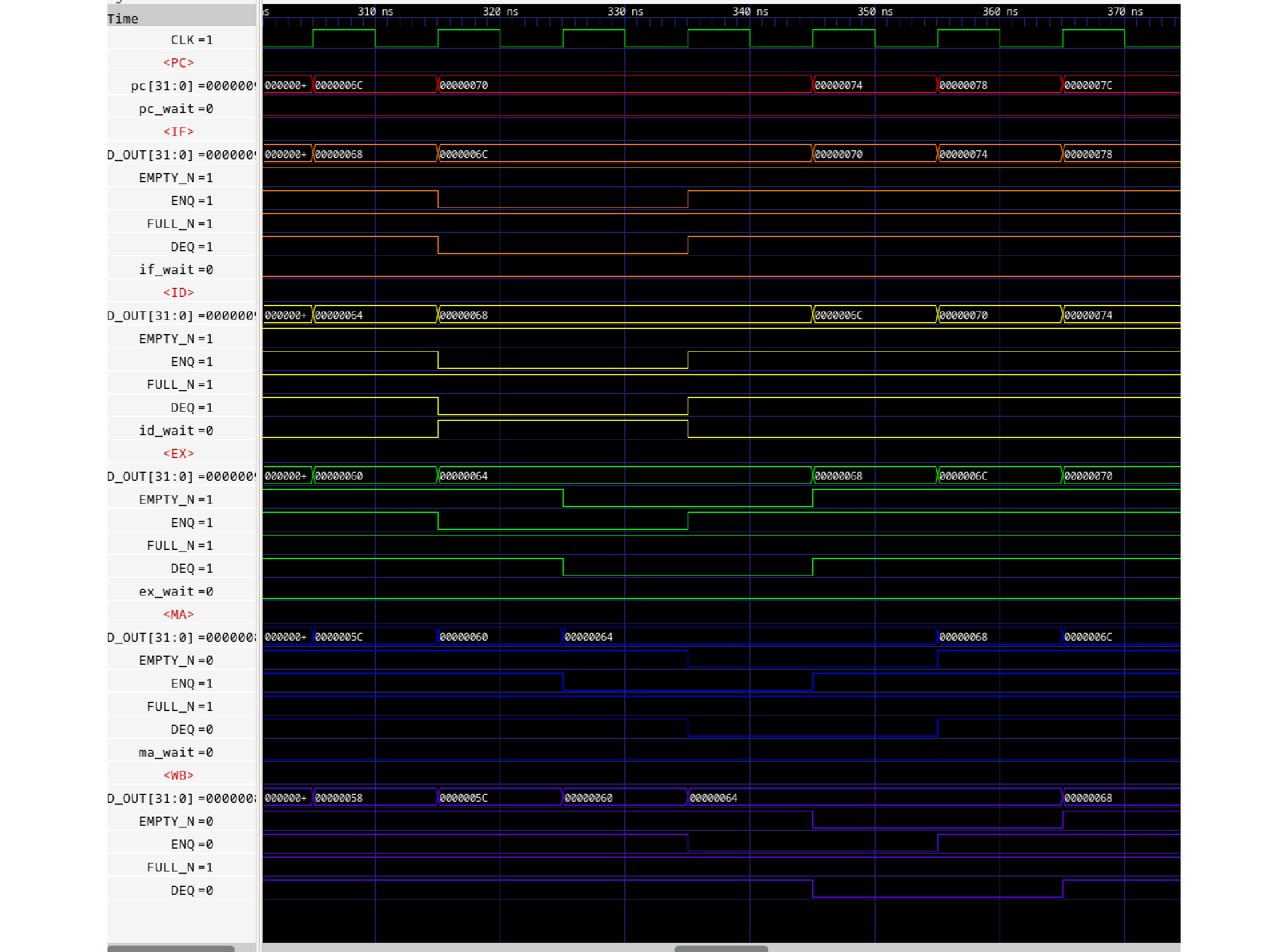
さらに前稿でインスタンスされるパイプラインFIFOであるFIFOL1のverilogライブラリのコードを見てみます。
assign FULL_N = !empty_reg || DEQ;
assign EMPTY_N = empty_reg ;
パイプラインFIFOは1段のF/Fなので、基本的にFULLとEMPTYは内部レジスタempty_regの背反ロジックとなりますが、例外的に下流からのDEQ要求がある場合は、仮にFULLであったとしても次のサイクルでFULLが解消されるため、DEQとのORをとり、not full(上位へのenq enable)とします。
always@(posedge CLK `BSV_ARESET_EDGE_META)
begin
if (RST == `BSV_RESET_VALUE)
begin
empty_reg <= `BSV_ASSIGNMENT_DELAY 1'b0;
end
else
begin
if (CLR)
begin
empty_reg <= `BSV_ASSIGNMENT_DELAY 1'b0;
end
else if (ENQ)
begin
empty_reg <= `BSV_ASSIGNMENT_DELAY 1'b1;
end
else if (DEQ)
begin
empty_reg <= `BSV_ASSIGNMENT_DELAY 1'b0;
end // if (DEQ)
end // else: !if(RST == `BSV_RESET_VALUE)
end // always@ (posedge CLK or `BSV_RESET_EDGE RST)
empty_regはnot emptyを表す内部レジスタであり、ENQするとTrue(=1, not empty)となり、DEQするとFalse(=0, empty)となります。not fullは上位へのenq enable信号であり、not emptyは下位へのdeq enable信号です。当初なぜemptyもfullも負論理なのかと思いましたが、(正論理の)イネーブルの意味がありました。
always@(posedge CLK `BSV_ARESET_EDGE_HEAD)
begin
begin
if (ENQ)
D_OUT <= `BSV_ASSIGNMENT_DELAY D_IN;
end // else: !if(RST == `BSV_RESET_VALUE)
end // always@ (posedge CLK or `BSV_RESET_EDGE RST)
ENQはF/F入力の値を出力に移します。一方DEQはF/Fは何も変化させません。
これまで見たように、bscにより生成された回路を解析することは、論理設計能力の向上の一助となります。