|
16 |
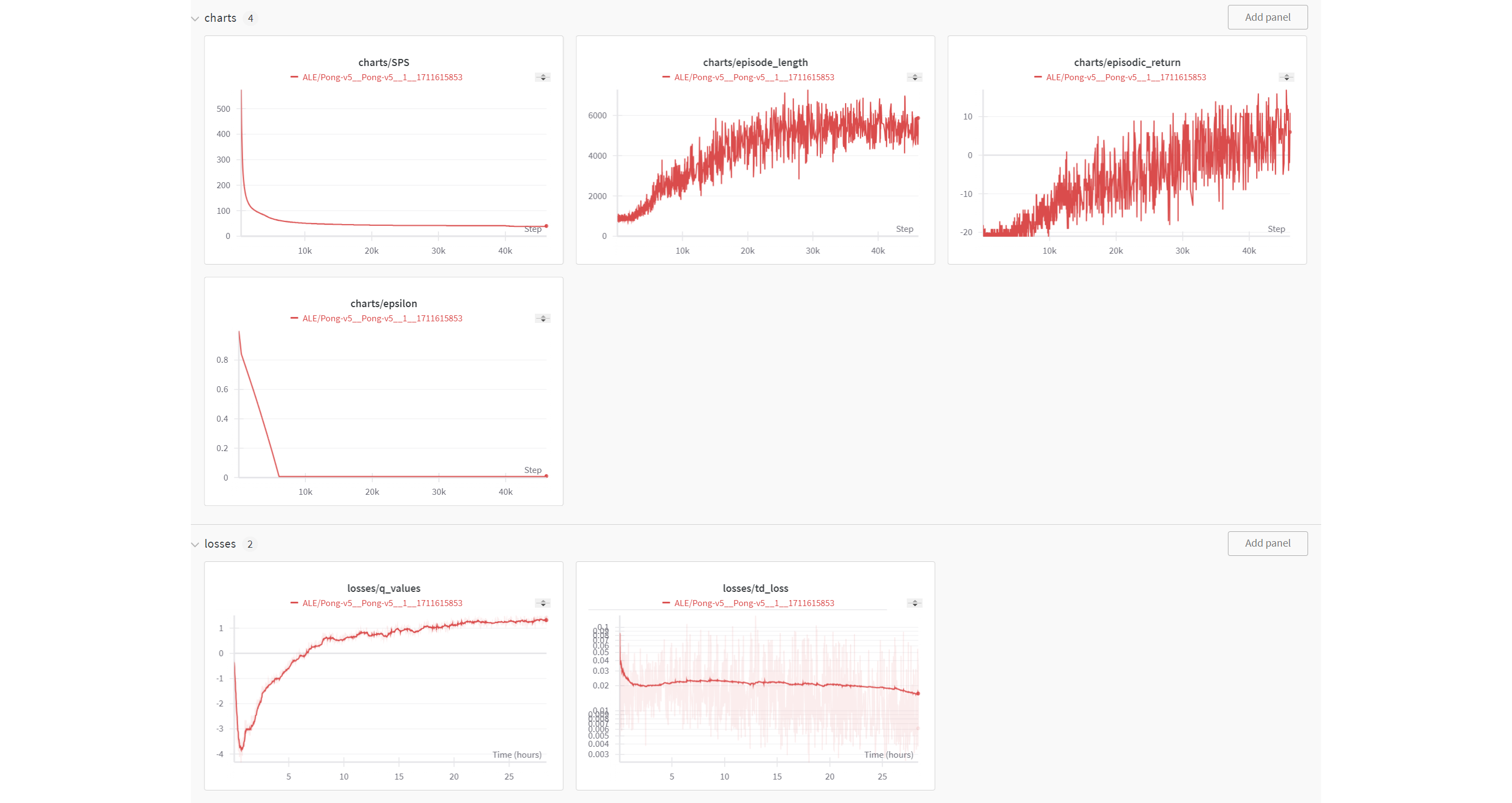
Pongと強化学習 (114) |
このプロトコルを用いてpythonのCustomAtariEnvと統合します。
CustomAtariEnv クラスを Device クラスを用いてシリアル通信の詳細を抽象化し、インタフェースをシンプルにするために再設計します。この方法により、CustomAtariEnv クラスはゲーム環境のロジックに集中し、シリアル通信の詳細は Device クラスが担当します。
Device クラスの設計
Device クラスはシリアル通信を担当し、コマンドの送受信を簡単に行えるように設計します。
import serial
class Device:
def __init__(self, port):
self.serial = serial.Serial(port, baudrate=115200, timeout=1)
def send(self, command, payload=None):
message = bytearray([SOH])
message.append(ord(command))
if payload is not None:
message.extend(payload)
message.append(EOT)
self.serial.write(message)
def receive(self):
response = bytearray()
while True:
byte = self.serial.read(1)
if byte:
response.append(byte[0])
if byte[0] == EOT:
break
return response
def close(self):
self.serial.close()
CustomAtariEnv クラスの再設計
CustomAtariEnv クラスは Device クラスを使用して通信を行います。これにより、CustomAtariEnv はシリアル通信の詳細から切り離されます。
import gym
from gym import spaces
class CustomAtariEnv(gym.Env):
def __init__(self, device):
super(CustomAtariEnv, self).__init__()
self.device = device
self.action_space = spaces.Discrete(4) # 仮に4つのアクション
self.observation_space = spaces.Box(low=0, high=255, shape=(256, 160, 3), dtype=np.uint8) # 仮の解像度
def reset(self):
self.device.send(CMD_RESET)
return self.device.receive()
def step(self, action):
action_command = self.get_action_command(action)
self.device.send(CMD_ACTION, [action_command])
return self.device.receive()
def get_action_command(self, action):
# Map the action to the actual command
if action == 0:
return ACTION_MOVE_LEFT
elif action == 1:
return ACTION_MOVE_RIGHT
elif action == 2:
return ACTION_FIRE
else:
raise ValueError("Invalid action")
def close(self):
self.device.close()
使用例
device = Device('/dev/ttyUSB0')
env = CustomAtariEnv(device)
initial_state = env.reset()
action = 1 # 仮に右移動
new_state = env.step(action)
env.close()
この再設計により、CustomAtariEnv クラスはシリアル通信の詳細から独立し、デバイスとの通信は Device クラスを通じて抽象化されます。これにより、ゲームロジックと通信ロジックが分離され、コードの可読性と保守性が向上します。