|
29 |
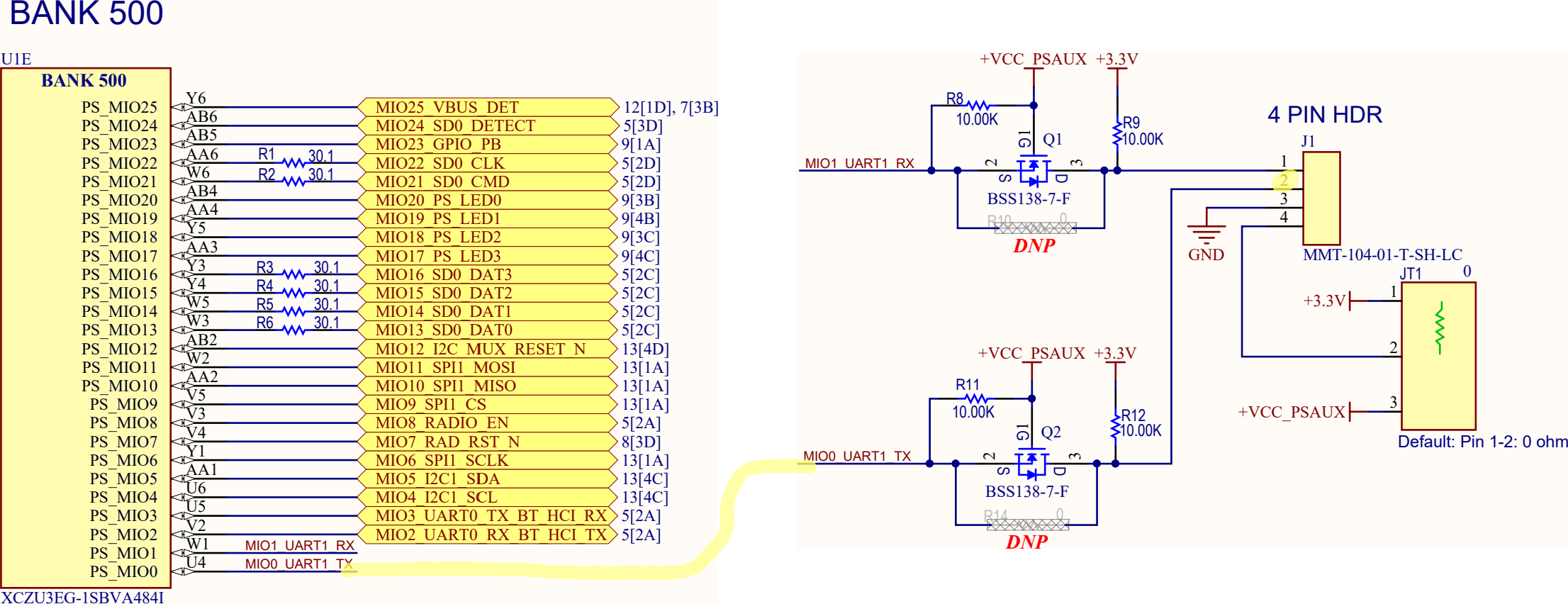
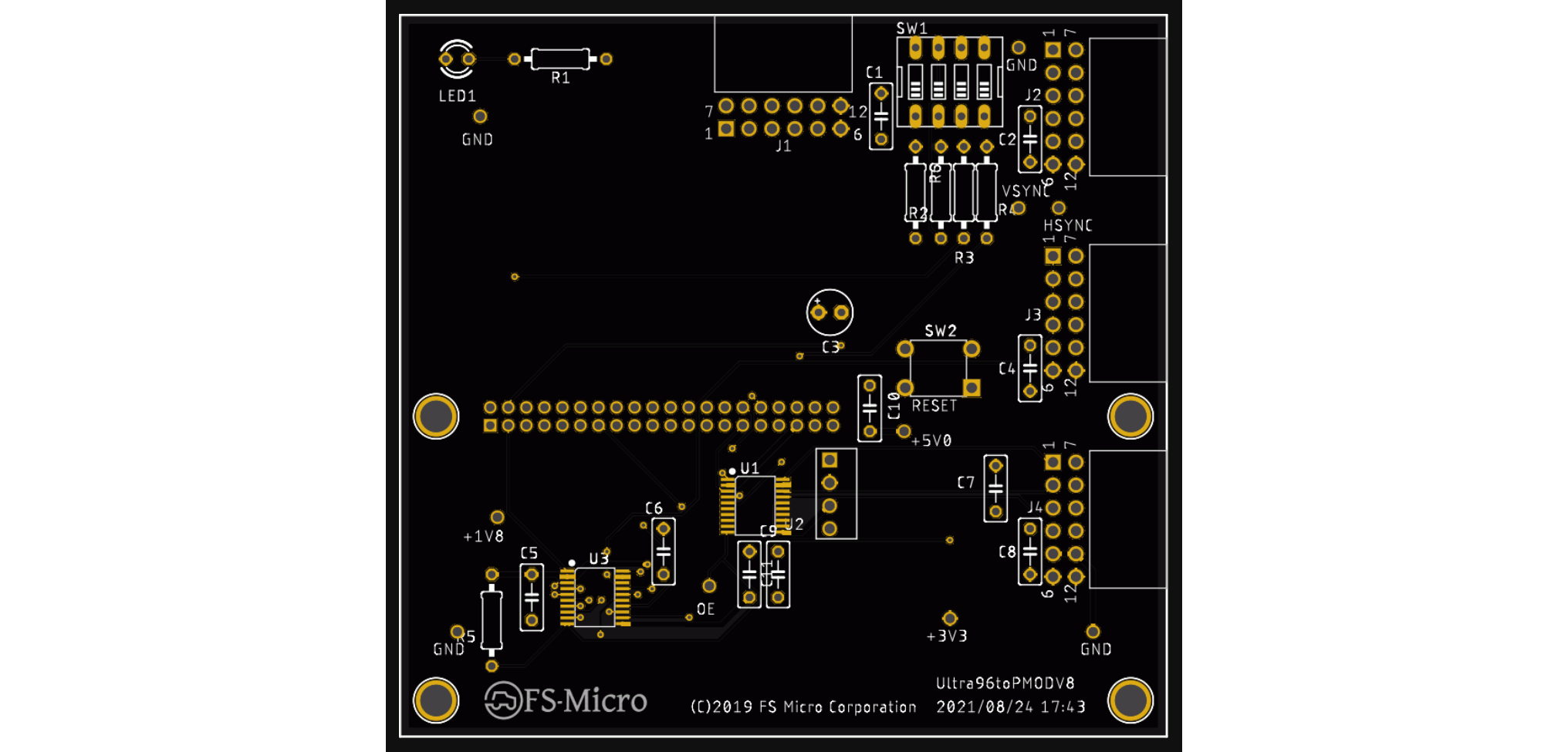
Ultra96toPMODの追加製造費用 |
Ulta96toPMOD基板製造再見積り
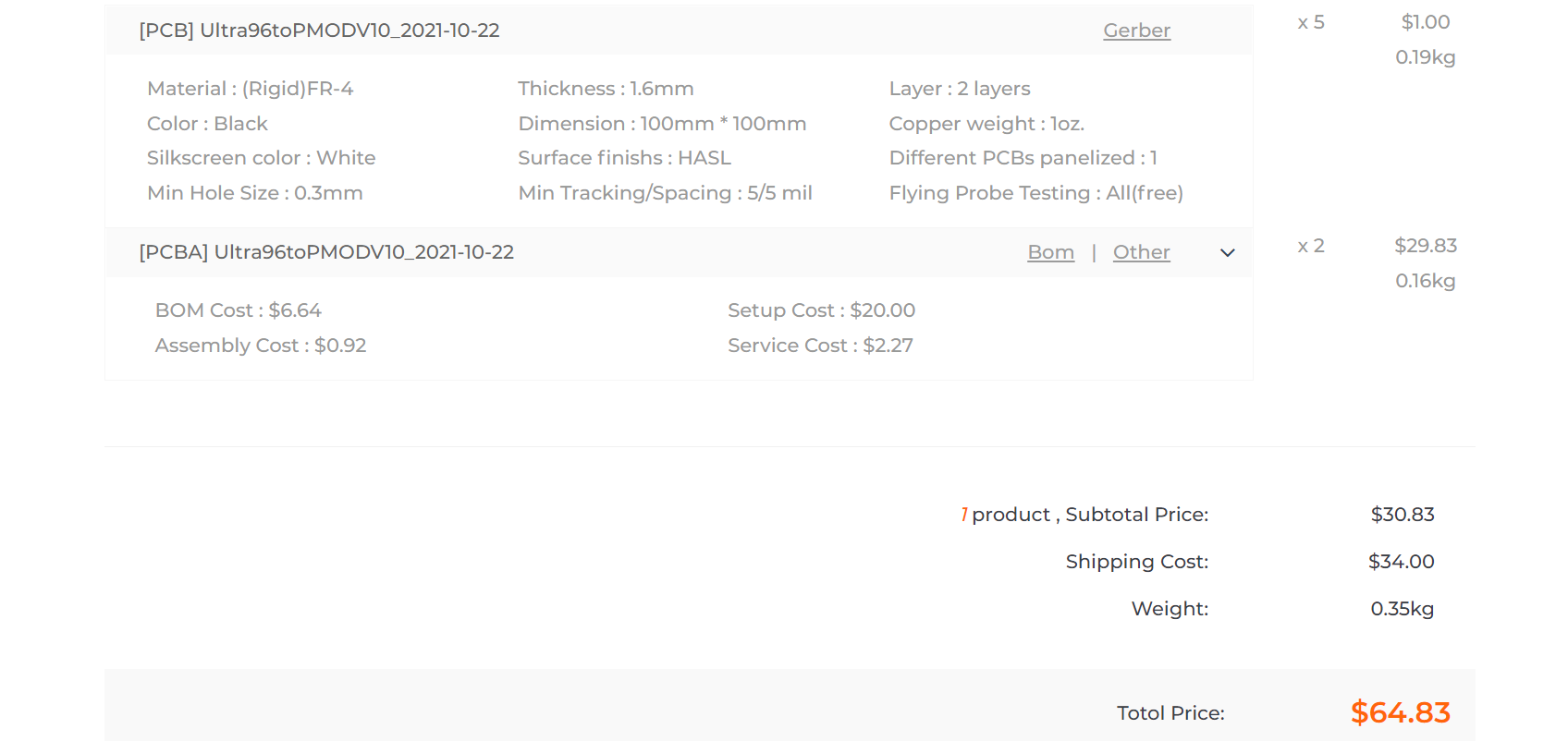
JLCPCBがPCBA(PCB製造及び部品実装)のセールをやっているようなので, 以前掲載したUltra96toPMODボードのオーダー費を再度計算してみました。
前回と同様パープルとグリーン基板を10枚製造し、さらにICを2個/枚×10枚実装した場合の費用の内訳を示します。前回パープル基板はEconomyの有利な価格で基板が製造できず、Standardとなっていました。今回はパープルもグリーンと同じEconomy扱いに変更されています。
| 10枚製造時費用内訳 | 基板色[USD] | |
|---|---|---|
| グリーン | パープル | |
| PCB Special Offer Price | 5.00 | |
| Components(TXS0108EPWR --- 20個) | 9.39 | |
| Extended Components | 2.96 | |
| SMT Assembly | 0.65 | |
| Setup fee | 7.88 | |
| Stencil | 1.48 | |
| 合計 | 27.36 | |
| 送料(OCS Express:6~8日) | 11.68 | |
| 総計 | 39.04 | |
前回と比較してみると、部品(レベコンIC)代が若干安くなり、セットアップフィー、SMTアセンブリ、ステンシルがほんの少し安くなりました。一方、送料が上がりクーポンが使えないので、40.2%の値上げ(パープルは28.6%の値下げ)という結果になりました。
今回、再度BokTech及びSeeedFusion PCBの見積もりを取りましたが、それぞれこの2倍、4倍ほどの費用となりました。JLCPCBの安さが光ります。
PMODピンソケットコネクタの再オーダー
PMOD仕様の12ピンソケットの型格はSamtec製のSSW-106-02-T-D-RAです。
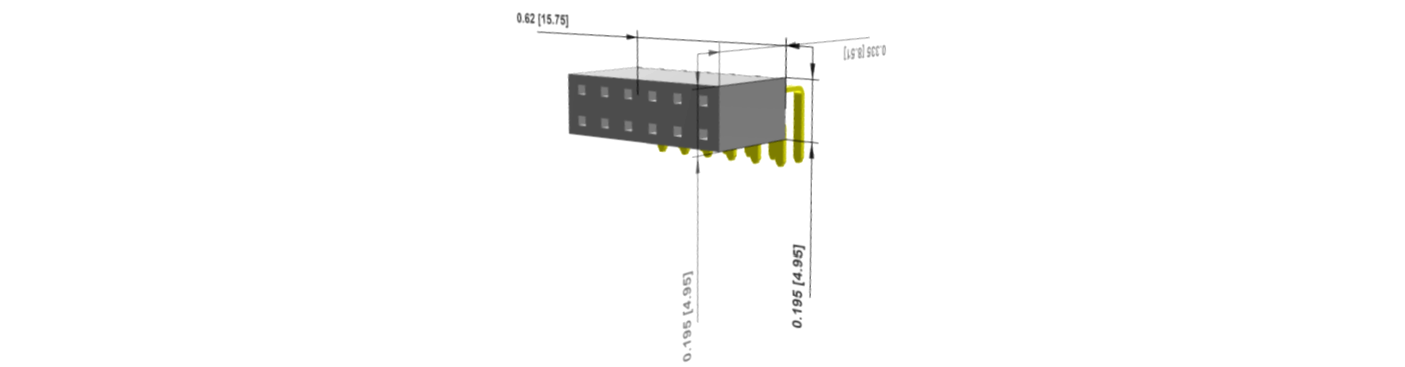
以前オーダーしたときはMouser から購入しました。この時は単価が141円と安く送料が無料なこともあり、総額が安かったのですが、今回見積もったら単価が258円とかなり値上がりしていたため、Arrowから購入しました。
再度調べたところ、以下のように最安はChip 1stopでした。単価的にはArrowと同じですが、送料が無料となることから、今後はChip 1stopで購入しようと思います。
- Chip1stop 単価156.2 x 40(送料650)= 6,899円 (税込み) 最安
- Arrow 単価156.2 x 40(送料3,080)= 9,330円 (税込み)
- RSオンライン 単価254.9x 40 (送料無料) =10,199円 (税込み)
- Mouser 単価263.6 x 40 (送料無料) =10,542円 (税込み)

本ピンソケット互換品でA2541HWR-2x6Pという製品があるようです。