|
12 |
Pongと強化学習 (71) |
Q-networkの図があったので掲載します。
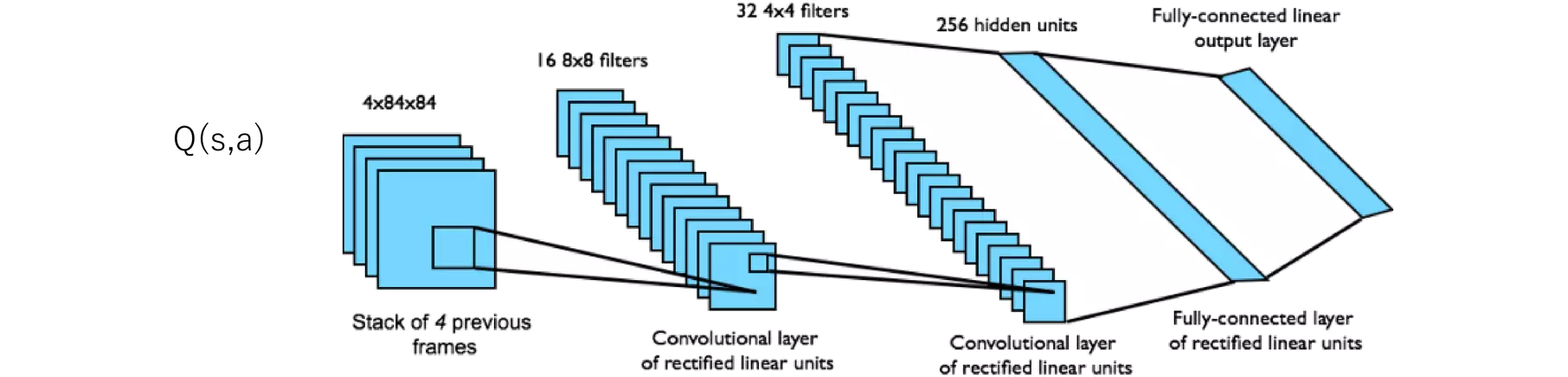
示されたQ-networkの構造は、典型的な強化学習タスクで使用される畳み込みニューラルネットワーク(CNN)の構成の一例です。特に、Atariゲームのようなビジュアルベースのタスクで使用されることが多い構成です。ここでは、各層がどのような役割を果たしているかを説明します。
1. 入力層: 4x84x84 --- 4つの前のフレームのスタック
- この層は、ゲームの現在の画面と過去3つの画面を含む、4つの連続するフレームからなる入力データを取り扱います。各フレームは84x84のグレースケール画像です。複数のフレームをスタックすることで、エージェントは動きや進行の速度など、時間的な情報を捉えることができます。これは、静止画だけでは得られない情報です。
2. 第1の畳み込み層: 16 8x8フィルター --- ReLU活性化関数を持つ畳み込み層
- この層では、16個の8x8のフィルター(カーネル)を使用して畳み込みを行います。これにより、入力画像から特徴を抽出します。ReLU(Rectified Linear Unit)活性化関数が適用され、非線形性が導入されます。これにより、ネットワークはより複雑な特徴を学習することができます。
3. 第2の畳み込み層: 32 4x4フィルター --- ReLU活性化関数を持つ畳み込み層
- 第2の畳み込み層では、より小さな4x4のフィルターを32個使用します。これにより、第1層で抽出された特徴からさらに詳細な特徴を抽出します。ReLU活性化関数がここでも使用され、特徴の非線形な組み合わせを可能にします。
4. 全結合層: 256隠れユニット --- ReLU活性化関数を持つ全結合層
- 第2の畳み込み層の後には、256ユニットを持つ全結合層が続きます。この層は、畳み込み層からの出力を受け取り、それらを一次元のベクトルに平坦化します。そして、全てのユニットが互いに接続されています。ReLU活性化関数により、さらに非線形性が導入されます。
5. 出力層: 全結合線形出力層
- 最後に、全結合の線形出力層があります。この層は、異なる行動に対応するQ値を出力します。層のユニット数は、エージェントが選択可能な行動の数に等しく、各ユニットの出力は特定の行動のQ値を表します。
このQ-networkの設計は、視覚的な入力から直接行動価値を推定する能力を提供します。畳み込み層は画像から特徴を抽出し、全結合層はこれらの特徴を利用して行動の価値を評価します。このネットワークを通じて、エージェントは画像データに基づいて最適な行動を決定することができます。
