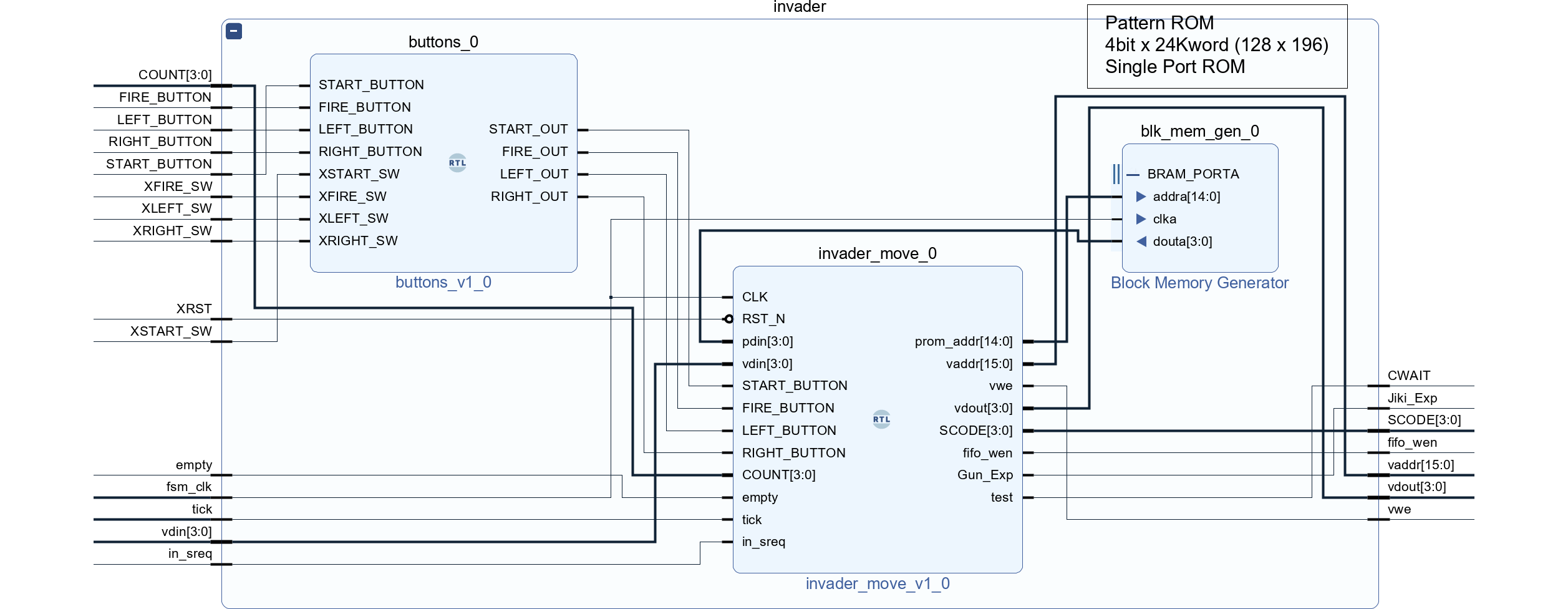
|
16 |
敵弾の貫通度の修正 (2) |
敵弾種類
敵弾名はインベーダゲームソースの研究から引用しています。図422.1の左から、Squiggly (抵抗器のようなジグザグ)、Rolling、Plunger (パイプつまり直し)と名前がついています。

図422.2において、敵弾の貫通度は左からそれぞれ3, 3, 7としています。
BSVコードの修正
元々敵弾をランダム(風)に出現させるため、カウンタの値により敵弾タイプを決めていますが、同じように貫通度を決めるテーブルです。
UInt#(3) invBullet_pdval[8] = { 7, 3, 3, 7, 3, 3, 7, 3}; // pd = penetrating depth
次は貫通度を記憶するためのレジスタであり、敵弾数だけ持つ必要があります。
Reg#(UInt#(3)) invBullet_pd[`INV_BULLET_MAX];
このレジスタを各敵弾にひとつ持たせるために敵弾の同時最大数だけインスタンシエートします。
for (int ii = 0; ii < `INV_BULLET_MAX; ii = ii + 1) begin
:
invBullet_pd[ii] <- mkRegU;
:
end
敵弾発生部において、タイプを決定するのと同じロジックにより、上記の表を引きます。
invBullet_type[idx] <= invBullet_rand[truncate(counter) & 3'h7];
invBullet_pd[idx] <= invBullet_pdval[truncate(counter) & 3'h7];
敵弾衝突の一部です。この2つのseq - endseqブロックは元は一つでしたが、base(バリケード)の時だけこの貫通度を使用するように分離します。他の場合は最深(貫通度=7)固定とします。
endseq else if (fbase) seq
eraseInvBullet(invBullet_x[idx], invBullet_y[idx]); // 現敵弾消去
explodeInvBullet(invBullet_x[idx], invBullet_y[idx], invBullet_pd[idx]); // 次敵弾爆発
invBullet_expTimer[idx] <= 1; // 敵弾爆発タイマスタート
voff <= 5; // break 'for'
endseq else if (fobj || invBullet_y[idx] >= 225) seq
eraseInvBullet(invBullet_x[idx], invBullet_y[idx]); // 現敵弾消去
invBullet_pd[idx] <= 7; // 最深
explodeInvBullet(invBullet_x[idx], invBullet_y[idx], 7); // 次敵弾爆発
invBullet_expTimer[idx] <= 1; // 敵弾爆発タイマスタート
voff <= 5; // break 'for'
コール先の爆発ルーチンです。爆発は、爆発マークを表示することで開始します。
// 敵弾爆発
function Stmt explodeInvBullet(
UInt#(8) destx,
UInt#(8) desty,
UInt#(3) pd);
return (seq
orArea(43, 16, destx - 3, desty + extend(pd), 8, 8);
endseq);
endfunction
爆発マーク消去コール部分です。爆発開始から一定時間後に、保存してある貫通度を使用して爆発マークを消去します。
expEraseInvBullet(invBullet_x[idx], invBullet_y[idx], invBullet_pd[idx]); // 敵弾爆発マーク消去
コール先の爆発マーク消去ルーチンです。
// 敵弾爆発マーク消去
function Stmt expEraseInvBullet(
UInt#(8) destx,
UInt#(8) desty,
UInt#(3) pd);
return (seq
eraseAreaSP(43, 16, destx - 3, desty + extend(pd), 8, 8);
endseq);
endfunction